







Fayson的github: https://github.com/fayson/cdhproject
推荐关注微信公众号:“Hadoop实操”,ID:gh_c4c535955d0f,或者扫描文末二维码。
1.文档编写目的
随着Hadoop集群数据量的增长,集群中也同时会存在大量的小文件,即文件Size比HDFS的Block Size(默认128MB)小的多的文件。Hadoop集群中存在大量的小文件对集群造成的影响如下:
1.对NameNode的内存造成很大的压力以及性能问题,在HDFS中任何文件、目录或者block在NameNode内存中均以对象的方式表示(即元数据),默认每个元数据对象约占150bytes。
2.HDFS在存储小文件上效率会很低,同样在读取上也会导致大量的查找,在各个DN节点去检索小文件。
在前面的文章Fayson介绍了《如何在Hadoop中处理小文件》,《如何使用Impala合并小文件》和《如何在Hadoop中处理小文件-续》。基于上述原因Fayson主要介绍如何通过离线分析HDFS的FsImage的方式查找集群中的小文件。
内容概述:
1.FsImage分析脚本
2.FsImage数据转存到Impala表中
3.各个维度分析查找集群中的小文件
4.总结
测试环境:
1.CM和CDH版本为5.15
2.离线FsImage分析脚本
本篇文章Fayson的分析脚本主要基于HDFS提供的oiv命令来进行FsImage离线分析,将FsImage文件解析问指定的csv格式数据,如下脚本分析的具体步骤:
1.使用hdfs命令获取FsImage数据文件
[root@cdh02 fsimage]# hdfs dfsadmin -fetchImage ./tmp_meta

2.使用hdfs oiv命令解析FsImage文件
[root@cdh02 fsimage]# hdfs oiv -i ./tmp_meta/fsimage_0000000000008236656 -o ./tmp_meta/fsimage.csv -p Delimited
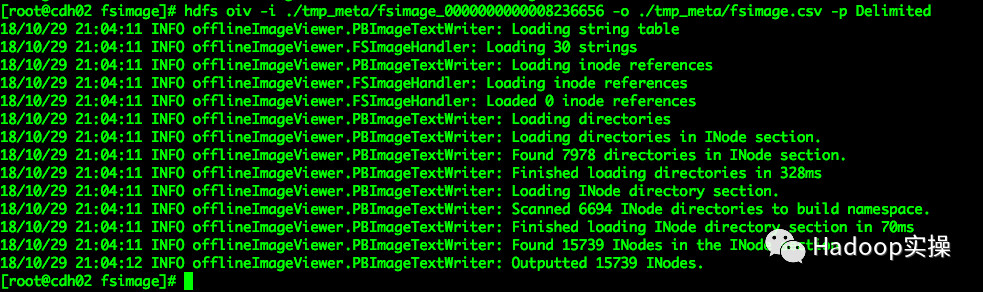
3.将解析的csv文件加载到Hive的HDFS_META_TEMP表中
[root@cdh02 fsimage]# sed -i -e "1d" ./tmp_meta/fsimage.csv
[root@cdh02 fsimage]# hdfs dfs -rmr /tmp/hdfs_metadata/fsimage
[root@cdh02 fsimage]# hdfs dfs -mkdir -p /tmp/hdfs_metadata/fsimage
[root@cdh02 fsimage]# hdfs dfs -copyFromLocal ./tmp_meta/fsimage.csv /tmp/hdfs_metadata/fsimage

4.使用Sqoop脚本将Hive元数据中关于Hive库和表的信息抽取的Hive中
sqoop import \
--connect "jdbc:mysql://${DB_IPADDR}:${DB_PORT}/${META_DB_NAME}" \
--username ${DB_USERNAME} \
--password ${DB_PASSWORD} \
--query 'select c.NAME,c.DB_LOCATION_URI,a.TBL_NAME,a.OWNER,a.TBL_TYPE,b.LOCATION from TBLS a,SDS b,DBS c where a.SD_ID=b.SD_ID and a.DB_ID=c.DB_ID and $CONDITIONS' \
--fields-terminated-by ',' \
--delete-target-dir \
--hive-database ${DB_NAME} \
--target-dir /tmp/${TARG_HIVE_TB} \
--hive-import \
--hive-overwrite \
--hive-table ${TARG_HIVE_TB} \
--m ${MAP_COUNT}
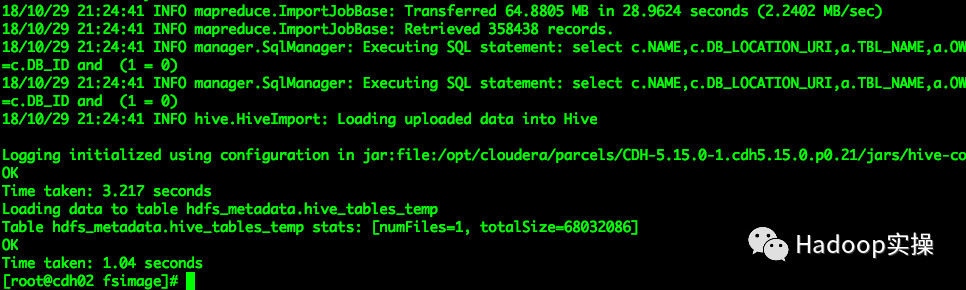
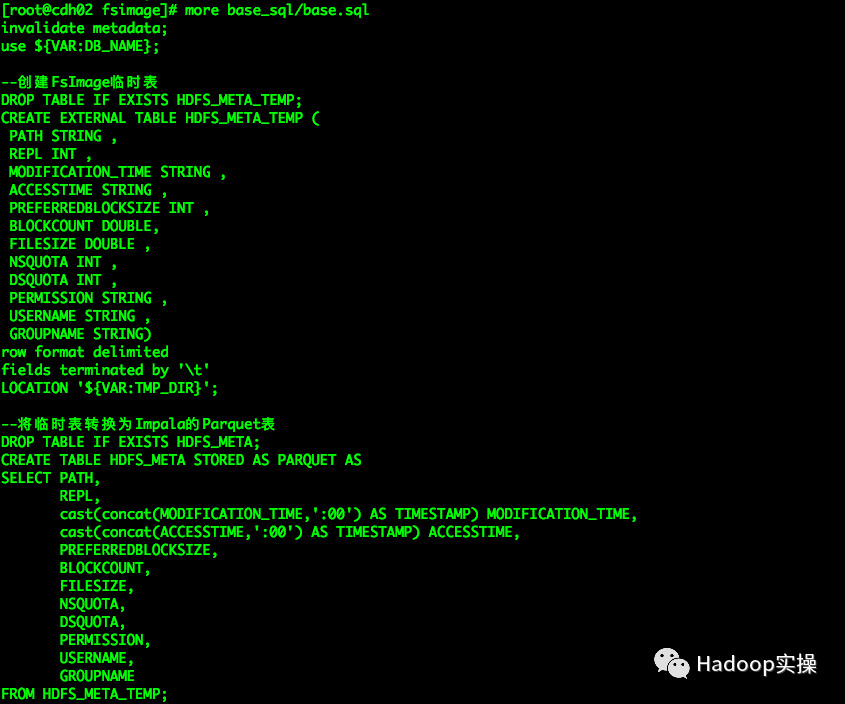
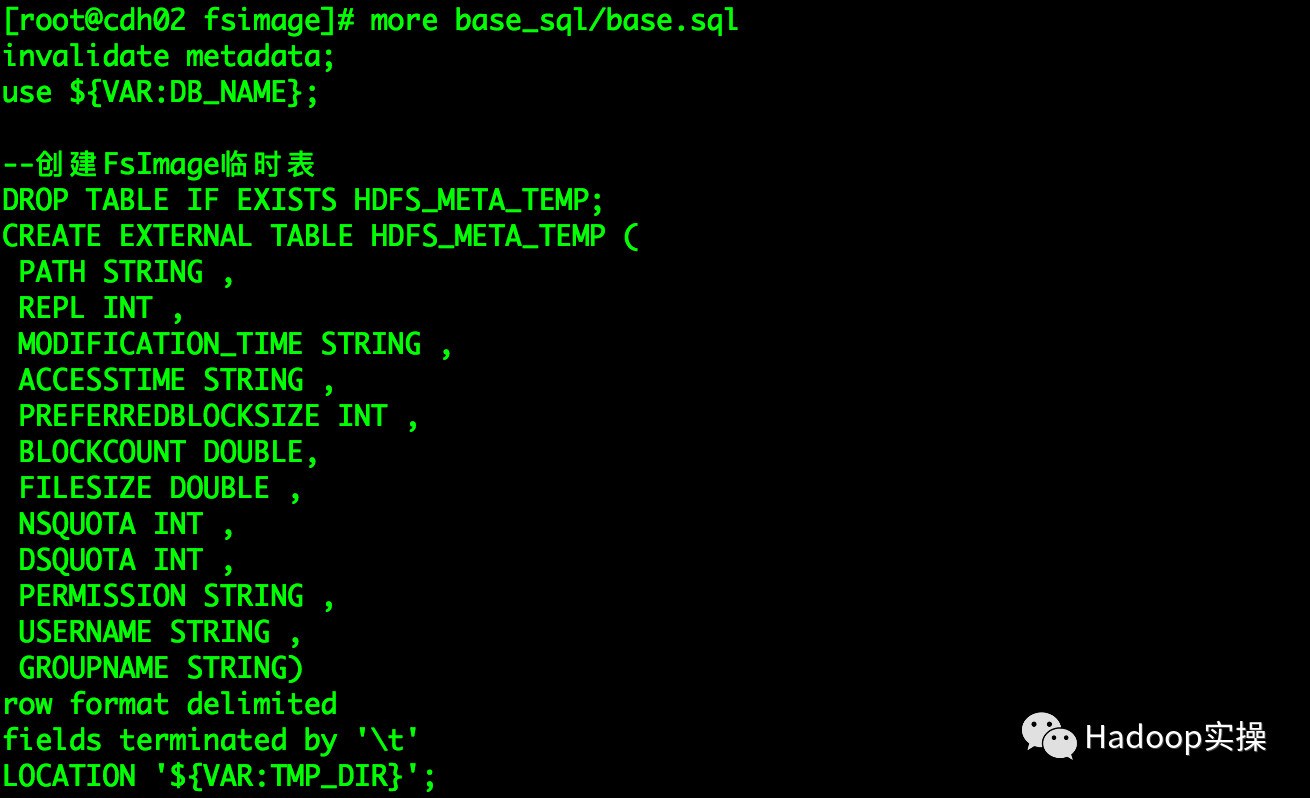
5.执行base.sql文件创建分析的Impala表
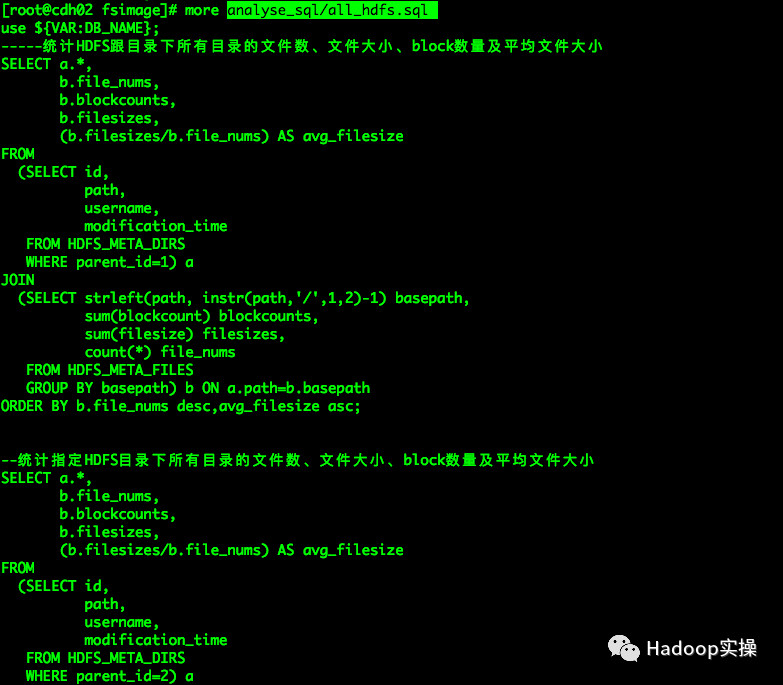
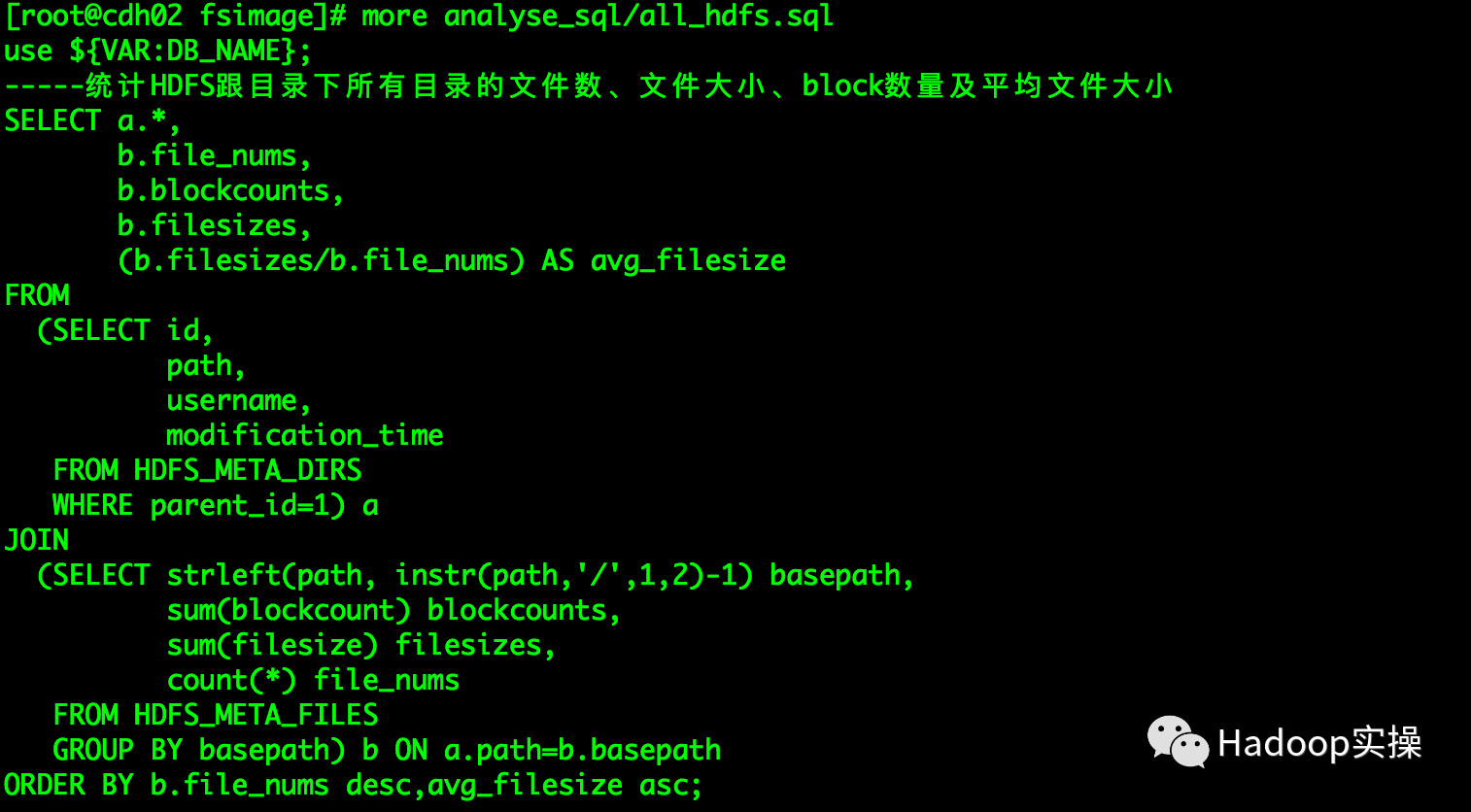
6.执行analyse_sql/all_hdfs.sql语句通过各个维度查找小文件
离线分析脚本目录结构如下:
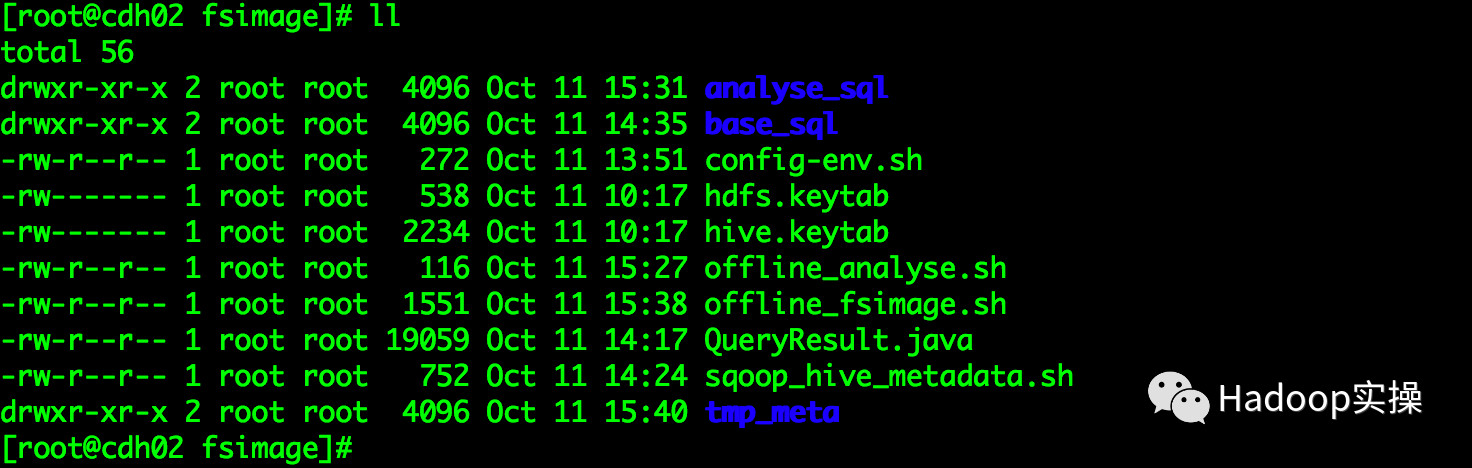
analyse_sql:主要存放分析小文件的SQL语句
base_sql:主要存放建表语句及基础数据生成SQL脚本
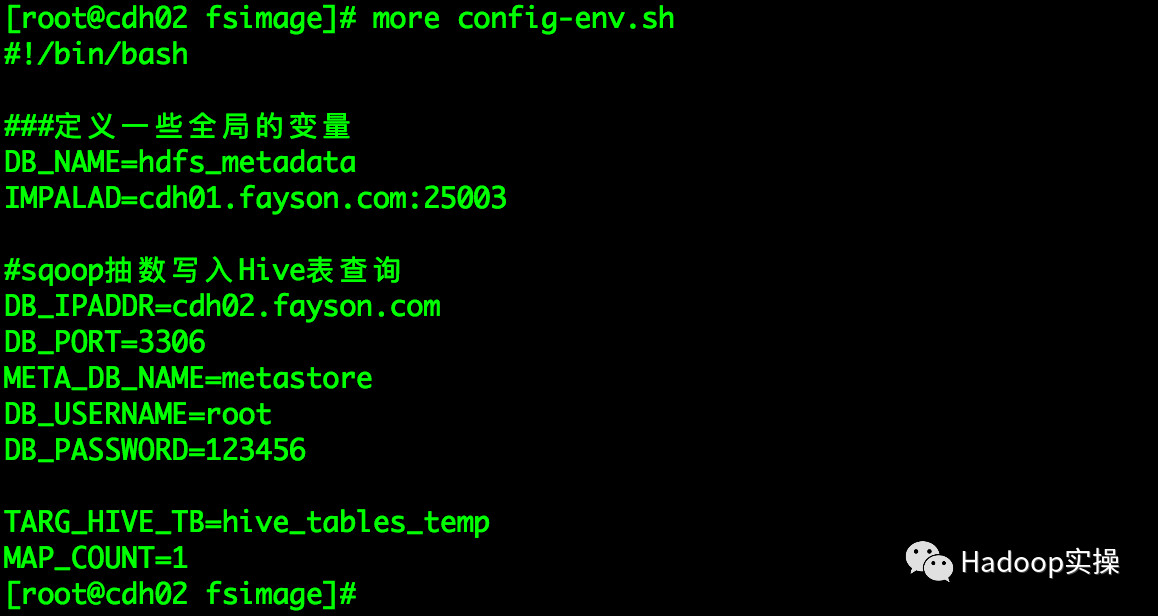
config-env.sh:脚本主要用户配置集群信息(如:ImpalaDaemon访问地址、存储的表名、临时文件存放目录等)
[root@cdh02 fsimage]# more config-env.sh
#!/bin/bash
###定义一些全局的变量
DB_NAME=hdfs_metadata
IMPALAD=cdh01.fayson.com:25003
#sqoop抽数写入Hive表配置参数
DB_IPADDR=cdh02.fayson.com
DB_PORT=3306
META_DB_NAME=metastore
DB_USERNAME=root
DB_PASSWORD=123456
TARG_HIVE_TB=hive_tables_temp
MAP_COUNT=1
*.keytab:两个keytab文件为前面环境准备过程中导出的hive和hdfs用户
offline_fsimage.sh:脚本主要用于创建分析用户的数据表及生成分析需要的数据
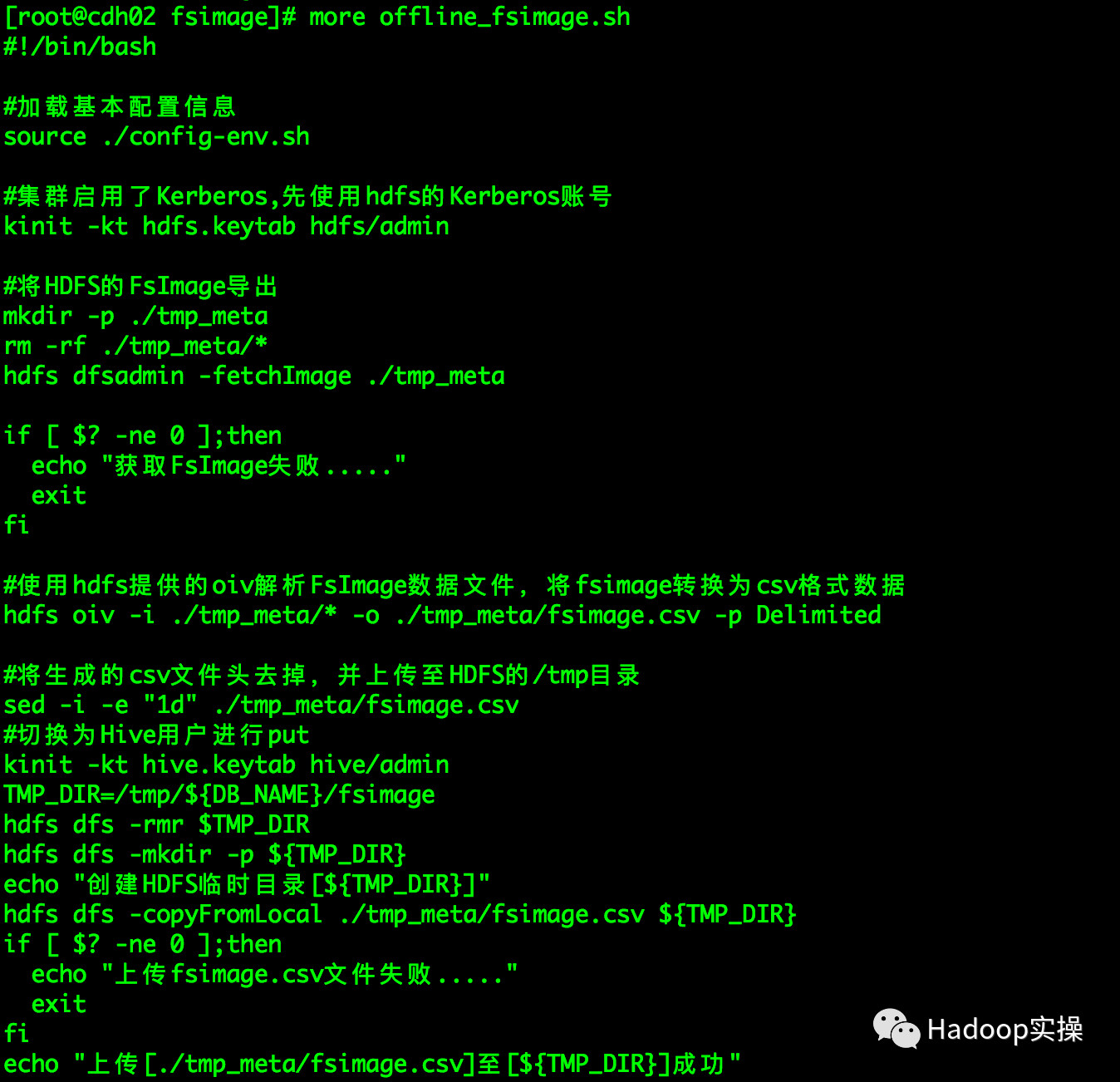
offline_analyse.sh:脚本用于执行analyse_sql目录的SQL语句
[root@cdh02 fsimage]# more offline_analyse.sh
#!/bin/bash
source ./config-env.sh
impala-shell -i $IMPALAD --var=DB_NAME=${DB_NAME} -f ./analyse_sql/all_hdfs.sql

sqoop_hive_metadata.sh:用于Sqoop抽取MySQL中Hive元数据表数据到Hive仓库
[root@cdh02 fsimage]# more sqoop_hive_metadata.sh
#!/bin/bash
#将Hive元数据库中的库及表等信息抽取到Hive仓库
sqoop import \
--connect "jdbc:mysql://${DB_IPADDR}:${DB_PORT}/${META_DB_NAME}" \
--username ${DB_USERNAME} \
--password ${DB_PASSWORD} \
--query 'select c.NAME,c.DB_LOCATION_URI,a.TBL_NAME,a.OWNER,a.TBL_TYPE,b.LOCATION from TBLS a,SDS b,DBS c where a.SD_ID=b.SD_ID and a.DB_ID=c.DB_ID and $CONDITIONS' \
--fields-terminated-by ',' \
--delete-target-dir \
--hive-database ${DB_NAME} \
--target-dir /tmp/${TARG_HIVE_TB} \
--hive-import \
--hive-overwrite \
--hive-table ${TARG_HIVE_TB} \
--m ${MAP_COUNT}

tmp_meta:该目录主要用于存放HDFS的元数据及oiv生成的csv文件
3.基于HDFS数据目录统计分析
如下统计方式主要基于HDFS的数据目录进行统计分析,统计HDFS指定目录下所有数据文件数、Block数量、文件总大小(bytes)及平均文件大小(bytes)。
统计中有两个重要参数parent_id和instr(path,’/’,1,2)这两个参数主要表示指定统计的HDFS目录以及目录钻取深度,instr()函数中的最后一个参数即为目录钻取深度(如果为parent_id=1为根目录“/”,钻取深度则为2,即根目录下所有的数据目录,需要钻取根深的目录则依次递增)。
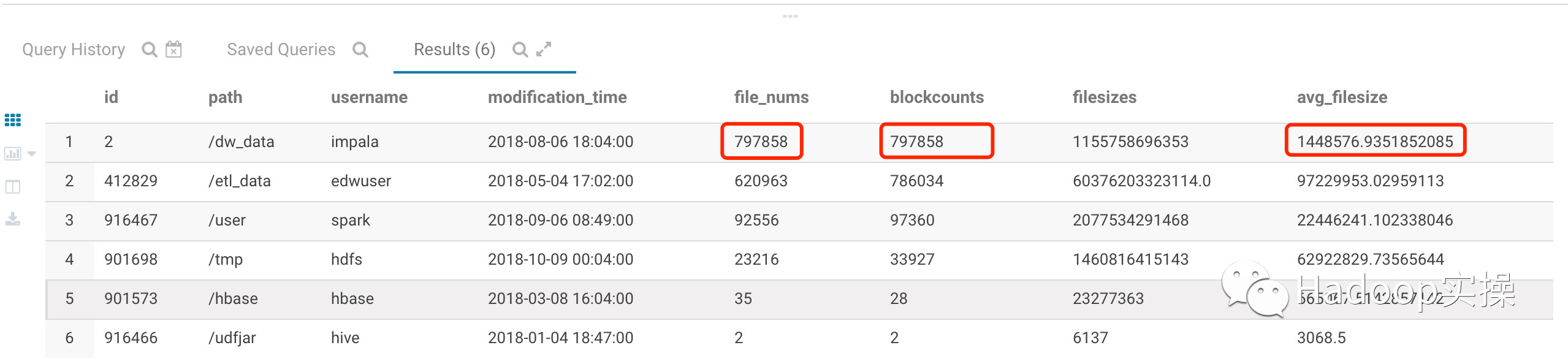
1.HDFS根目录统计分析
SELECT a.*,
b.file_nums,
b.blockcounts,
b.filesizes,
(b.filesizes/b.file_nums) AS avg_filesize
FROM
(SELECT id,
path,
username,
modification_time
FROM HDFS_META_DIRS
WHERE parent_id=1) a
JOIN
(SELECT strleft(path, instr(path,'/',1,2)-1) basepath,
sum(blockcount) blockcounts,
sum(filesize) filesizes,
count(*) file_nums
FROM HDFS_META_FILES
GROUP BY basepath) b ON a.path=b.basepath
ORDER BY b.file_nums desc,avg_filesize asc;
2.指定HDFS数据目录统计分析
SELECT a.*,
b.file_nums,
b.blockcounts,
b.filesizes,
(b.filesizes/b.file_nums) AS avg_filesize
FROM
(SELECT id,
path,
username,
modification_time
FROM HDFS_META_DIRS
WHERE parent_id=2) a
JOIN
(SELECT strleft(path, instr(path,'/',1,3)-1) basepath,
sum(blockcount) blockcounts,
sum(filesize) filesizes,
count(*) file_nums
FROM HDFS_META_FILES
GROUP BY basepath) b ON a.path=b.basepath
ORDER BY b.file_nums desc,avg_filesize asc;

4.基于Hive库和表的统计分析
如下统计方式主要基于Hive库和表的统计分析,统计Hive中所有库存的数据文件数、Block数量、文件总大小(bytes)及平均文件大小(bytes)。
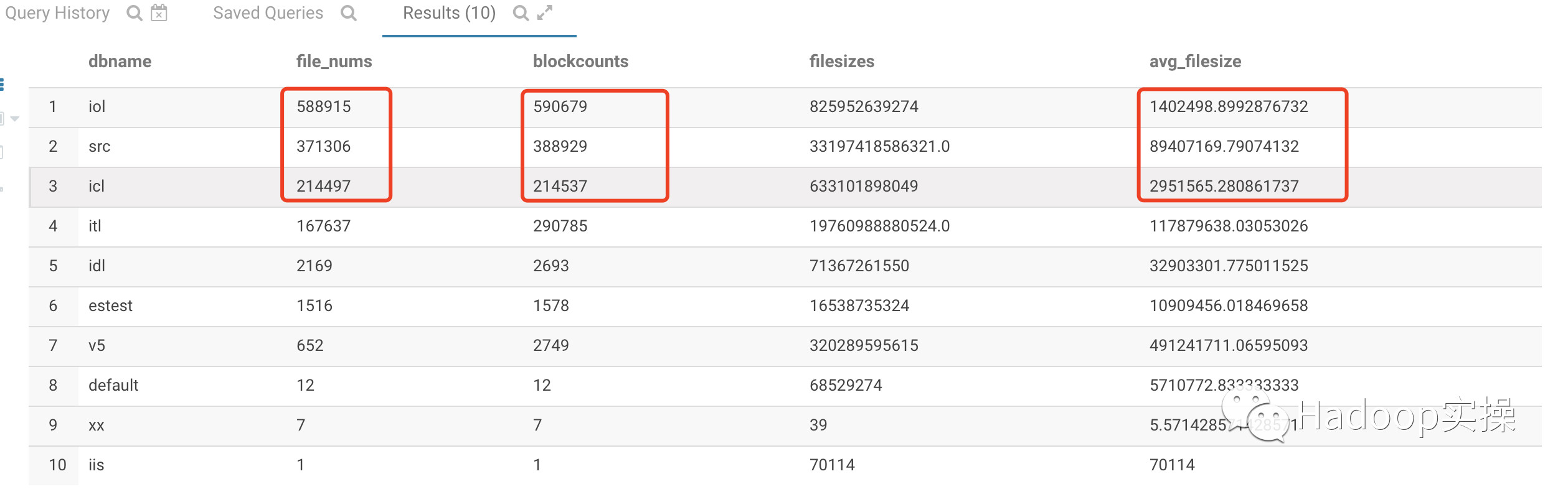
1.基于Hive库的统计分析
SELECT n.*,
(n.filesizes/n.file_nums) AS avg_filesize
FROM hdfs_meta_dirs p,
(SELECT a.id,
b.dbname,
count(*)
FROM hdfs_meta_dirs a
JOIN hive_table_details b ON a.path=b.db_path
GROUP BY a.id,
b.dbname) m,
(SELECT a.dbname,
count(1) file_nums,
sum(b.blockcount) blockcounts,
sum(b.filesize) filesizes
FROM hive_table_details a,
hdfs_meta_files b
WHERE a.fid=b.fid
GROUP BY a.dbname) n
WHERE p.id=m.id
AND m.dbname=n.dbname
order by file_nums desc,avg_filesize asc;
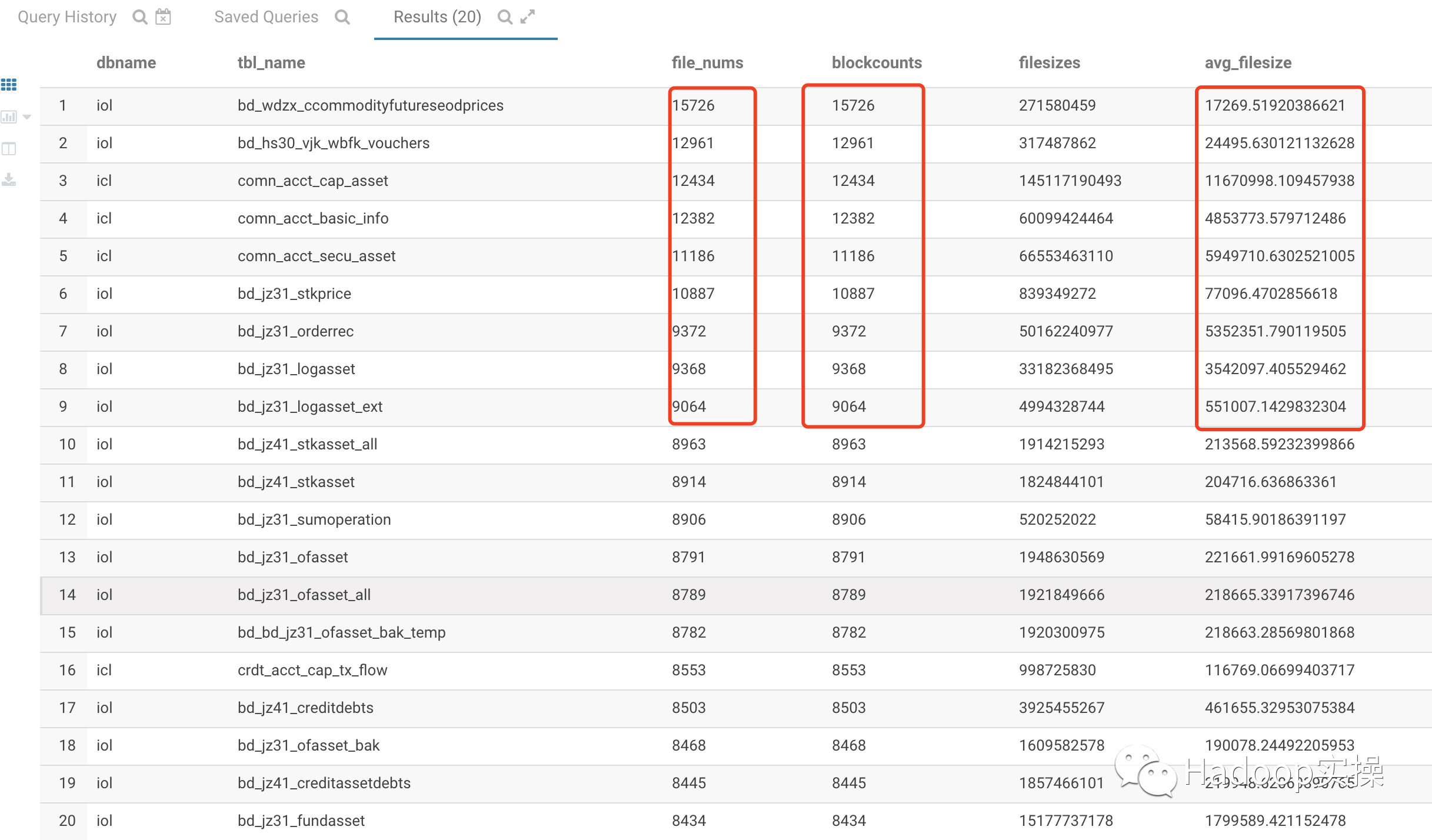
2.基于Hive表的统计分析
select n.*,(n.filesizes/n.file_nums) AS avg_filesize from hdfs_meta_dirs p,
(select a.id,b.dbname,count(*) from hdfs_meta_dirs a join hive_table_details b on a.path=b.db_path group by a.id, b.dbname) m,
(SELECT
a.dbname,a.tbl_name,
count(1) file_nums,
sum(b.blockcount) blockcounts,
sum(b.filesize) filesizes
FROM hive_table_details a,
hdfs_meta_files b
WHERE a.fid=b.fid
GROUP BY a.dbname,a.tbl_name) n
where p.id=m.id and m.dbname=n.dbname
order by file_nums desc,avg_filesize asc
limit 20;
5.总结
如上SQL的统计分析可以看到有三个比较重要的统计指标file_nums、blockcounts和avg_filesize。通过这三个指标进行小文件分析,进行如下分析:
如果file_nums/blockcounts的值越大且avg_filesize越小则说明该HDFS或Hive表的小文件越多。
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操















 3176
3176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









