







散列表:哈希表,存储位置 = f(关键字) ,这种对应关系的函数成为哈希函数Hash
建立一张表,方便查找,每一个key对应表中的一个位置
跟传统的查找不同的是,散列表都有具体的位置,查找时的算法时间复杂度为O(1),不需要依靠规律查找。
#include "stdio.h"
#include "stdlib.h"
#include "io.h"
#include "math.h"
#include "time.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 100 /* 存储空间初始分配量 */
//散列表:哈希表,存储位置 = f(关键字) ,这种对应关系的函数成为哈希函数Hash
//建立一张表,方便查找,每一个key对应表中的一个位置
//这里采用的是:除留余数法:f(key) = key mod p (p<=m)
//mod 即就是取模(求余数)的意思,所以这个关键在于p的取值,
//散列表长度为m,通常p为小于或等于表长的最小质数或不包含小于20质因子的合数
#define SUCCESS 1
#define UNSUCCESS 0
#define HASHSIZE 12
#define NULLKEY -32768
typedef int Status;
typedef struct {
int *ele; //指向一个数组的指针
int count; // 数组元素的个数
}HashTable;
int m =0; //hash表的长度,全局变量
//初始化
Status InitHashTable(HashTable *H){
m = HASHSIZE;
int i;
H->count = m;
H->ele = (int *)malloc(m*sizeof(int));
for(i=0;i<m;i++){
H->ele[i] = NULLKEY;
}
return OK;
}
//散列函数
int Hash(int key){
return key % m; ///* 除留余数法 */
}
void InsertHashTable(HashTable *H,int key){
int addr = Hash(key); //散列地址
while(H->ele[addr]!=NULLKEY){ /* 如果不为空,则冲突 */
addr = (addr+1) % m; /* 开放定址法的线性探测 */
}
H->ele[addr] = key; /* 直到有空位后插入关键字 */
}
//查找
Status SearchHashTable(HashTable H,int *addr,int key){
*addr = Hash(key); //该点的散列地址
while(H.ele[*addr]!= key){ //如果不不等于,则进入线性探测
*addr = (*addr+1)%m; /* 开放定址法的线性探测 */
if(H.ele[*addr] == NULLKEY || *addr == Hash(key)){
/* 如果循环回到原点 */
return UNSUCCESS; //不存在
}
}
return SUCCESS;
}
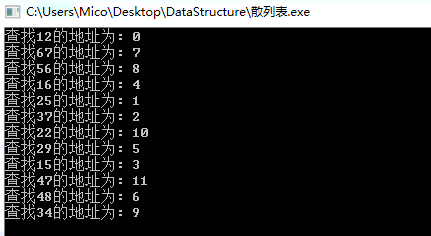
int main()
{
int arr[MAXSIZE] = {12,67,56,16,25,37,22,29,15,47,48,34};
int i,p,key,result;
HashTable H;
InitHashTable(&H);
for(i=0;i<m;i++){
InsertHashTable(&H,arr[i]);
}
for(i=0;i<m;i++){
result = SearchHashTable(H,&p,arr[i]);
if(result){
printf("查找%d的地址为: %d \n",arr[i],p);
}else{
printf("查找%d的地址失败\n",arr[i]);
}
}
} 















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









