







一 、决策树原理: 基本的分类与回归方法,通过对每个结点进行划分,选择“是”和“否”。
对于分类问题:测试样本点到达的叶子节点,输出分类结果。
对于回归问题:测试样本点到达的叶子节点上所有样本点输出值的平均值,即为测试样本点的输出值;
对于决策树来说,回归和分类唯一的区别在于最终通过叶子节点(预测阶段,测试样本点所到达决策树的叶子节点)得到的是一个具体数值的回归结果(叶子节点上所有样本点输出值的平均值),还是一个类别的分类结果(叶子节点上所有类别中样本点最多的类别)。
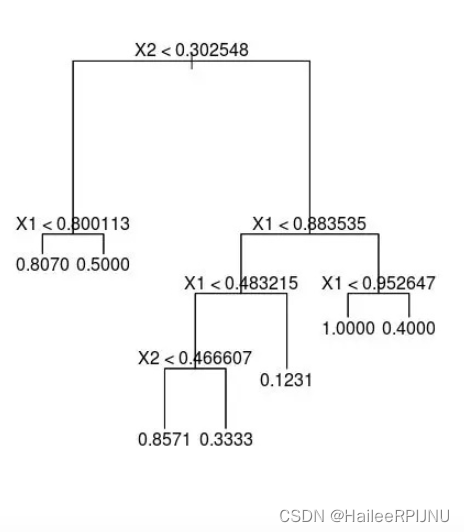
二、切分点怎么选
每次划分数据都能让信息熵(混乱程度)降低,当划分到最后一个叶子节点里面只有一类数据的时候,信息熵就自然降为零了,所属的类别就确定了。
1. 什么是熵:熵就是混乱程度
其中, pi 是指数据中一共有n类信息,pi就是值第i类数据所占比例。
假设数据中一共有三类,每一类所占的比例为1/3, 那么信息熵就是:
H = -1/3 log (1/3) - 1/3 log (1/3) - 1/3 log (1/3) = 1.0986
假设数据一共有三类,每类所占的比例为0,0,1, 那么信息熵:
H = - 0 log (0) - 0 log(0) - 1 log(1) = 0
可以看出,第二组比第一组信息熵更少,也就是更为确定。
2. 什么是信息增益:信息增益代表了在一个条件下,信息复杂度(不确定性)减少的程度。
信息熵是代表随机变量的复杂度(不确定度),条件熵代表在某一个条件下,随机变量的复杂度(不确定度)。
信息增益 = 信息熵-条件熵,也就是X的熵 - Y条件下的X的熵。如果信息增益值很大,也就意味着这个信息很重要,使得随机变量的不确定度大大降低。
eg: 原本明天下雨的信息熵是2,条件熵是0.01(因为如果知道明天是阴天,那么下雨的概率很大,信息量少),这样相减后为1.99。下雨信息不确定性减少了1.99,不确定减少了很多,所以信息增益大。
三、sklearn参数
sklearn.tree.DecisionTreeRegressor(*, criterion='squared_error', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, ccp_alpha=0.0)
criterion{“squared_error”, “friedman_mse”, “absolute_error”, “poisson”} 寻找最佳节点的方法,也就是找一个方法使“不纯度”最低。
(1) 均方误差“squared_error”: 以方差减少作为特征选择标准,使用终端的均值来最小化L2 损失。
(2) “费尔德曼均方误差” friedman_mse: 使用弗尔德曼针对潜在分歧问题改进后的均方误差。
(3) 绝对误差“absolute error”, 这种指标使用叶节点的中值来最小化L1损失。
(4) 泊松: 通过减少泊松偏差来寻找分裂。
splitter{“best”, “random”}: 在每个节点选择拆分的策略
包括“最佳”选择,和“随机”选择。输入“best”, 决策树在分枝时虽然随机,但是还是会有限选择更重要的特征进行分枝(feature_importance), 输入“random", 决策树在分枝时会更加随机,树会因为含有更多不必要信息而更深更大,并因为这些不必要信息而降低对训练集的拟合,也是防止过拟合的方式。
max_depth(int): 树的最大深度,超过设定深度的树枝全部剪掉。
如果不设定,将一直分裂到纯度局部最优点,或者使比min_samples_split 样本更少为止。决策树多长一层,对样本的需求量会增加一倍,复杂度更高,也更容易过拟合。
min_samples_leaf: 分割所需的最小样本数(考虑当前)。例如,如果min_sample_split = 6并且节点中有4个样本,则不会发生拆分(不管熵是多少)
min_samples_split:叶节点所需的最小样本数(考虑下一代的限制)。例如,假设min_sample_leaf = 3并且一个含有5个样本的节点可以分别分裂成2个和3个大小的叶子节点,那么这个分裂就不会发生,因为最小的叶子大小为3。
min_samples_leaf 和 min_samples_split 一般搭配max_depth使用,在回归树中有神奇的效果,可以让模型变得更加平滑。这个参数的数量设置得太小会引起过拟合,设置得太大就会阻止模型学习数据。
min_weight_fraction_leaf(float): 叶子结点所有样本权重和,如果低于阈值,则会和兄弟节点一起被剪枝,默认是零,就是不考虑权重问题。这个一般在样本类别偏差较大或有较多缺失值的情况下会考虑。如果样本是加权的,则使用基于权重的预修剪标准来更容易优化树结构,这确保叶节点至少包含样本权重总和的一小部分。
max_features: int;float; {'auto', 'sqrt', 'log2'}
和max_depth有异曲同工之妙,划分考虑最大特征数,超过限制个数的特征都会被舍弃。不输入则默认全部特征,如果特征大于50,则可以选择考虑用auto来控制决策树的生成时间。max_features是用来限制高维度数据的过拟合的剪枝参数,但其方法比较暴力,是直接限制可以使用的特征数量而强行使决策树停下的参数,在不知道决策树中的各个特征的重要性的情况下,强行设定这个参数可能会导致模型学习不足。
(1) 如果是整数,考虑每一次分割的最大特征。
(2)如果是浮点数,max_features是一个分数,每次拆分时都会考虑 max(1, int(max_features * n_features_in_)) 特征。
(3)如果是“aoto” , 最大特征 = 特征数
(4) 如果是“sqrt”, 最大特征 = sqrt(特征数)
(5)如果是“log2”, 最大特征 = log2 (特征数)
(6)如果是none, 最大特征 = 特征数
random_state,随机状态实例或无,默认值=无
random_state用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会表现更明显,低维度的数据(比如鸢尾花数据集),随机性几乎不会显现。输入任意整数,会一直长出同一棵树,让模型稳定下来。
max_leaf_nodes: 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
min_impurity_decrease:min_impurity_decrease限制信息增益的大小,信息增益小于设定数值的分枝不会发生。
ccp_alpha: 成本复杂性参数。将选择成本复杂度最大且小于 ccp_alpha 的子树。默认情况下,不执行任何修剪。
四、应用函数
| apply(X[, check_input]) | Return the index of the leaf that each sample is predicted as. | |
| cost_complexity_pruning_path(X, y[, ...]) | Compute the pruning path during Minimal Cost-Complexity Pruning. | |
| decision_path(X[, check_input]) | Return the decision path in the tree. | |
| fit(X, y[, sample_weight, check_input]) | Build a decision tree regressor from the training set (X, y). | |
| Return the depth of the decision tree. | ||
| Return the number of leaves of the decision tree. | ||
| get_params([deep]) | Get parameters for this estimator. | |
| predict(X[, check_input]) | Predict class or regression value for X. | |
| score(X, y[, sample_weight]) | Return the coefficient of determination of the prediction. | |
| set_params(**params) | Set the parameters of this estimator. |
五、总结:
七个参数:Criterion,两个随机性相关的参数(random_state,splitter),四个剪枝参数(max_depth, ,min_sample_leaf,max_feature,min_impurity_decrease)
一个属性:feature_importances_
四个接口:fit,score,apply,predict
六、举例
1. 画决策树, 预测
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import tree
df0=pd.read_csv('final_data_Guida.csv')
X = df0.iloc[:,2:98]
y = df0['R1M_Usd']
dt_feature_names = list(X.columns)
X=X.fillna(0.50)
y=y.fillna(y.median())
clf = tree.DecisionTreeRegressor(
min_samples_split = 8000,
max_depth = 3,
min_samples_leaf =3500
)
clf = clf.fit(X, y)
fig, ax = plt.subplots(figsize=(12, 12))
tree.plot_tree(clf.fit(X, y), max_depth=3, fontsize=10, feature_names=dt_feature_names)
plt.show()
y_pred=clf.predict(X.iloc[1:6,:])

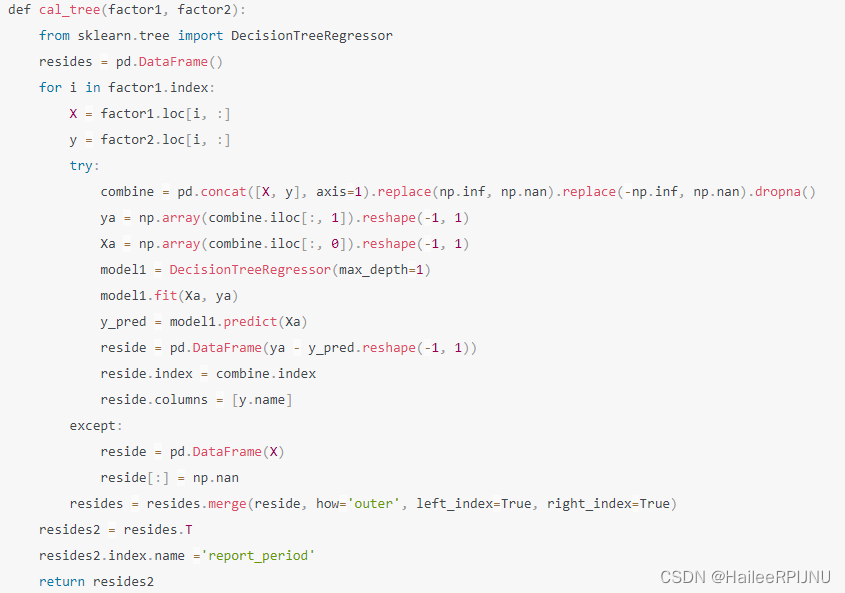
2. 举例:截面数据回归求残差
通过两列数据,使用树回归求残差















 1620
1620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









