









学习前(理论)
最小二乘法、岭回归、Lasso等
学习中(领悟)
1.首先是一段包导入,跳过
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.ml.tuning.{CrossValidator, ParamGridBuilder}
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
/**
* A simple example demonstrating model selection using CrossValidator.
* This example also demonstrates how Pipelines are Estimators.
*
* Run with
* {{{
* bin/run-example ml.ModelSelectionViaCrossValidationExample
* }}}
*
*/
2.看一下run-example这个脚本:
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
export _SPARK_CMD_USAGE="Usage: ./bin/run-example [options] example-class [example args]"
exec "${SPARK_HOME}"/bin/spark-submit run-example "$@"- 首先,[ -z “${SPARK_HOME}” ]判断当前环境有没有设置SPARK_HOME,(-z判断后面参数的长度是否为0)。
- dirname取指定路径所在的目录,保留最后一个/前面的字符,删除其他部分,并写结果到标准输出。如果最后一个/后无字符,dirname 命令使用倒数第二个/,并忽略其后的所有字符。
- $0表示当前运行的命令名,source “ (dirname" 0”)”/find-spark-home就是执行find-spark-home的脚本。source不会创建新进程。
- 查看find-spark-home。就是想方设法export SPARK_HOME
- 然后执行spark-submit脚本,spark-submit会调用spark-class执行org.apache.spark.deploy.SparkSubmit
- spark-class。。。无穷无尽,以后在细学吧。简单的说它会设置大量的环境变量,以及一些classpath和jvm参数。
3.回到正题:(这段也没啥可看的)
object ModelSelectionViaCrossValidationExample {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val spark = SparkSession
.builder
.master("local")
.appName("ModelSelectionViaCrossValidationExample")
.getOrCreate()
// $example on$
// Prepare training data from a list of (id, text, label) tuples.
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0),
(4L, "b spark who", 1.0),
(5L, "g d a y", 0.0),
(6L, "spark fly", 1.0),
(7L, "was mapreduce", 0.0),
(8L, "e spark program", 1.0),
(9L, "a e c l", 0.0),
(10L, "spark compile", 1.0),
(11L, "hadoop software", 0.0)
)).toDF("id", "text", "label")4.配置ML pipeline, 该流水线包括三个阶段: tokenizer(分词器), hashingTF, lr
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10) // 迭代次数,默认100
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr)) // 函数原型:setStages(value: Array[_ <: PipelineStage]): Pipeline.this.type5.
- 使用ParamGridBuilder 来构建 a grid of parameters to search over.
- hashingTF.numFeatures设置三个值, lr.regParam设置两个值
- 这样一来,对于CrossValidator,就可以评估上面设置的6个参数,也可以认为可以学习6种模型(模型运行是使用“fit”方法,2.0.0版本加入)
- hashingTF:目前使用Austin Appleby的MurmurHash 3算法————将词映射为词频
val paramGrid = new ParamGridBuilder()
.addGrid(hashingTF.numFeatures, Array(10, 100, 1000)) // Features的数量,默认为2的18次方。
.addGrid(lr.regParam, Array(0.1, 0.01)) // 正则化参数,默认0.0
.build() // this grid will have 3 x 2 = 6 parameter settings for CrossValidator to choose from.6.
- 现在将Pipeline视为一个Estimator(进行算法或管道调-整), 把它包裹进一个CrossValidator实例
这会在所有的Pipeline stages中调整参数 - 所有的模型选择器都需要:
- 一个Estimator【之前设置的流水线】, 一个Estimator参数集【之前设置的paramGrid】, 一个Evaluator【评估者:衡量拟合模型对延伸测试数据有多好的度量】.
- 这里的BinaryClassificationEvaluator是默认的(我修改为了RegressionEvaluator)
- 模型评估工具有————回归:RegressionEvaluator;二进制数据:BinaryClassificationEvaluator;多类问题:MulticlassClassificationEvaluator
val cv = new CrossValidator() // 模型选择工具有: CrossValidator和TrainValidationSplit
.setEstimator(pipeline)
.setEvaluator(new RegressionEvaluator) // 默认是BinaryClassificationEvaluator
.setEstimatorParamMaps(paramGrid)
.setNumFolds(2) // 生成2个(训练,测试)数据集对,其中训练数据占比2/3,测试数据占1/3
//详:【参数值必须>=2,默认3】。数据集对是不重叠的随机拆分,每对中的测试数据仅测试一次。
//所以数据集大时,我们可以设置得高一些,但是数据集小时,可能会过拟合。TODO:不能整除怎么办?7.
- 运行交叉验证,选择出最好的参数集
- 对于上面的setNumFolds,fit函数会调用MLUtils的kFold方法进行拆分(org.apache.spark.mllib.util.MLUtils)
- fit函数详见:https://github.com/apache/spark/blob/v2.1.1/mllib/src/main/scala/org/apache/spark/ml/tuning/CrossValidator.scala
val cvModel = cv.fit(training) // 对于这里,返回一个CrossValidatorModel
// 准备测试集
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "mapreduce spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
// 使用刚才学习出来的模型对测试集进行预测
cvModel.transform(test) // transform对数据进行转换,返回一个DataFrame。"probability"和"prediction"
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}
spark.stop()
}
}TODO:返回的DataFrame是如何构造的?(”probability”, “prediction”)
stackoverflow有人解释说:
RawPrediction通常是直接用概率/置信度计算出来的
prediction是rawPrediction.argmax的结果
Probability是条件概率:
Estimate the probability of each class given the raw prediction,
doing the computation in-place. These predictions are also called class conditional probabilities.
还是比较模糊,我还想知道的是该DataSet是如何构造的。
学习后(实践):
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.ml.regression.LinearRegression
import org.apache.spark.ml.tuning.{CrossValidator, ParamGridBuilder}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
/**
* @author 王海[https://github.com/AtTops]
* package main.scala.firstput
* description 这里没有结合字符串类型(使用StringIndexer);
* 没有处理分类变量(使用VectorIndexer(向量类型索引化));也没有使用独热编码OneHotEncoder;
* Date 2018/1/4 20:40
* Version V1.0
*/
object LrPipline {
val myTrainCsvPath: String = ""
val myCVPath: String = ""
val myTestCsvPath: String = ""
val resultsPath: String = ""
/**
* 目前可以使用CrossValidator和TrainValidationSplit这两种方式调整参数,前者慢后者快,
* 但是后者在数据集小时表现得可能不好(TrainValidationSplit只对一次参数的每个组合进行评估,而在CrossValidator的情况下则为k次。)
*
* @param spark
*/
def piplineWithCrossValidator(spark: SparkSession): Unit = {
var rawTrainDf: DataFrame = spark.read.format("csv").option("header", true).option("inferSchema", true).load(myTrainCsvPath)
rawTrainDf.printSchema()
rawTrainDf = rawTrainDf.withColumnRenamed("sale_quantity", "label").na.drop()
// 将多个特征变量合并成一个特征变量,以用于输入之后的模型
val calArray = Array("sale_date", "class_id", "brand_id", "compartment", "type_id", "department_id", "TR", "displacement", "driven_type_id", "emission_standards_id", "if_MPV_id", "if_luxurious_id", "cylinder_number", "engine_torque", "car_length", "car_height", "total_quality", "rear_track")
val assembler = new VectorAssembler() // 设置哪些是特征,剩下的是标签,但是还没有开始转换
.setInputCols(calArray)
.setOutputCol("features")
val output = assembler.transform(rawTrainDf)
output.select("features", "label").show
// 初步建立线性回归模型
val lr = new LinearRegression()
// .setFeaturesCol("features") // 也可以不这样做,因为之前的assemble人已经指明了哪些是特征列。后面的setStages(Array(lr))用setStages(Array(assembler,lr))代替
// .setLabelCol("sale_quantity") // 所有数值类型会自动转为double型(所以不用自己去处理为double型)
// .fit(output)
// 使用ParamGridBuilder构建参数网格
val paramMap = new ParamGridBuilder() // 这些参数可以在LinearRegression类中的Parameters找到
.addGrid(lr.regParam, Array(0.1, 0.01)) // 正则化参数,默认0.0
.addGrid(lr.elasticNetParam, Array(0.1, 0.5, 0.9)) // 给L1、L2正则化的结合版设置3种需要尝试的参数(默认0.0,仅L2正则)
.addGrid(lr.maxIter, Array(10, 20))
.build()
// 构建管道,把各个阶段连接在一起(这里就一个)
val pipeline = new Pipeline()
.setStages(Array(assembler, lr))
// 模型评估以及选择
val cv = new CrossValidator()
.setEstimator(pipeline)
.setEvaluator(new RegressionEvaluator)
.setEstimatorParamMaps(paramMap)
.setNumFolds(4)
val cvModel = cv.fit(rawTrainDf)
// 打印模型相关参数
println("extractParamMap=============================")
val params: ParamMap = cvModel.extractParamMap() // 打印“冻结”的所有参数
params.toSeq.foreach {
print
}// cvModel.getDefault()
println("extractParamMap.length=============================")
println(cvModel.getEstimatorParamMaps.length)
println("foreach=============================")
cvModel.getEstimatorParamMaps.foreach {
println
} // 参数组合的集合
println(cvModel.getEvaluator.isLargerBetter) // 评估的度量值是大的好,还是小的好
// 测试集准备
var rawTestDf: DataFrame = spark.read.format("csv").option("header", true).option("inferSchema", true).load(myTestCsvPath)
rawTestDf = rawTestDf.drop("sale_quantity").na.drop()
// 测试并且打印结果
println("开始测试===================")
val results: DataFrame = cvModel.transform(rawTestDf)
println("打印预测结果===================")
results.select("class_id", "prediction")
.collect()
.foreach { case Row(id: Double, prediction: Double) =>
println(s"$id ----------> prediction=$prediction")
}
val save = results.select("class_id", "prediction") // 不转换一下的话,报错说csv数据源类型错误
save.coalesce(1)
.write
.mode("overwrite")
.option("header", true)
.format("csv")
.save(resultsPath)
println(s"预测结果保存完毕,保存路径————————>:$resultsPath")
// 保存模型
cvModel.write.overwrite().save(myCVPath)
spark.stop()
}
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val spark = SparkSession.builder()
.master("local")
.appName("SomeStatistics")
.getOrCreate()
piplineWithCrossValidator(spark)
}
}预测结果:
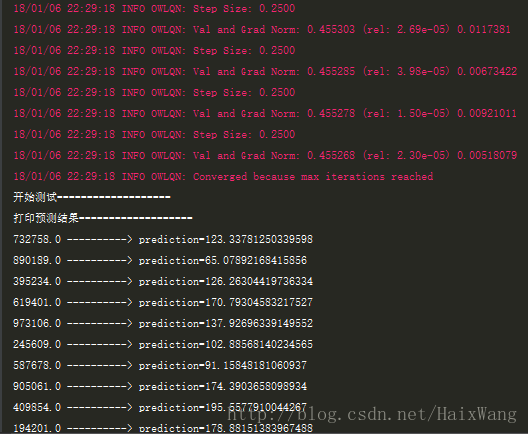
保存的模型:
总结
Spark机器学习中的小框架:
Spark中的LogisticRegression:
1.默认会对数据集进行标准化
TODO:具体采用哪种方法进行标准化,怎样手动选择其他标准化方法
def setStandardization(value: Boolean): this.type = set(standardization, value)
setDefault(standardization -> true)2.如果不设置权重,则将所的权值设置为1.0
TODO:参数怎么是String类型的?
def setWeightCol(value: String): this.type = set(weightCol, value)3.平方误差函数为:

4.支持使用setElasticNetParam设置alpha的值:(默认0.0)
none(最小二乘法)
L2正则化 (岭回归)——alpha=0
L1正则化 (Lasso)——alpha=1
L2 + L1 正则化(elastic net)——alpha=(0,1)
TrainValidationSplit和CrossValidator:
1.TrainValidationSplit仅对参数的每个组合进行一次评估,而在CrossValidator的情况下,是k次(k=getNumFolds)。 因此,它较快,但在训练数据集不够大时可能不会产生可靠的结果。
2. CrossValidator使用setNumFolds设置交叉集(默认3);TrainValidationSplit使用setTrainRatio设置训练集和测试集的比率(无默认值)。
保存和加载模型:
Please refer to the algorithm’s API documentation to see if saving and loading is supported.
。。。
CrossValidator就找见save没找见load。。。















 1379
1379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









