







kMeans的算法为:
假定输入的样本为x1,x2,…xn
1.随机选择k个点作为质心:u1,u2,…uk
2.对每个样本xi计算其到质心的距离,将其标记为距离最近的质心那一类
3.将每个类别中心更新为该类别中样本的均值
4,重复2,3直到点距离质心的变化小于某阈值
python代码如下:
说明:
测试数据testSet中包含两列,可以假设为横坐标与纵坐标
其中center表示的是质心,其形式为center[横坐标,纵坐标, 以当前质心为中心聚类的点的个数],datamat表示的是样本数据,来源于datamat,record是记录样本Xi是属于哪个质心的,其形式为record[datamat中的索引(即在datamat中是第几个),质心的索引(即哪个质心),距离(当前样本距离质心的距离)]
import random
from numpy import *
from math import sqrt
import pylab as pl
datamat=[]
fr=open('testSet.txt')
line=fr.readline
count=0
while line:
line=fr.readline()
curline=line.strip().split('\t')
if curline[0]!='':
#print curline
fltline=map(float,curline)
#print fltline
count=count+1
#print count
#print line
datamat.append(fltline)
print datamat[0][0]
print count
###############preprocessing the data file
#datamat=random.shuffle(datamat) 这里本来是想把样本中的点打乱重新排列选择前面4个作为质心,这样达到了随机选择的目的,但是后面报错了,所以只能注释掉
center=zeros([4,3]) 先将center全部填充为0
record=zeros([count,3])
#print datamat[79][0]
for k in range(0,4):
center[k,0]=datamat[k][0] 因为前面打乱样本的报错,将datamat的前面几个点作为质心
center[k,1]=datamat[k][1]
tag=1
while tag==1:
tag=0
for i in range(0,4):对质心
for j in range(0,count):对样本中的数据
dist=sqrt((center[i,0]-datamat[j][0])**2+(center[i,1]-datamat[j][1])**2) 计算距离
if record[j,2]==0 or record[j,2]>dist:
tag=1
center[record[j,1],2]-=1 样本Xj之前对应的质心的以其作为质心的个数减1,因为样本Xj将有新的质心了
record[j,0]=j
record[j,1]=i
record[j,2]=dist
center[i,2]+=1 新质心对应的点的个数加1
for j in range(0,4):
center[j,0]=0
center[j,1]=0
for j in range(0,count): 对每个质心将其所属的点的横纵坐标相加,为后面的求均值做准备
center[record[j,1],0]=center[record[j,1],0]+datamat[j][0]
center[record[j,1],1]=center[record[j,1],1]+datamat[j][1]
for i in range(0,4):
center[i,0]=center[i,0]/center[i,2]
center[i,1]=center[i,1]/center[i,2]
print center
for i in range(0,count):
if record[i,1]==0:
pl.plot(datamat[i][0],datamat[i][1],'ob')
print datamat[i][0],datamat[i][1]
if record[i,1]==1:
pl.plot(datamat[i][0],datamat[i][1],'og')
if record[i,1]==2:
pl.plot(datamat[i][0],datamat[i][1],'or')
if record[i,1]==3:
pl.plot(datamat[i][0],datamat[i][1],'oy')
pl.show()

不知道是不是因为代码还有问题,明天再试。
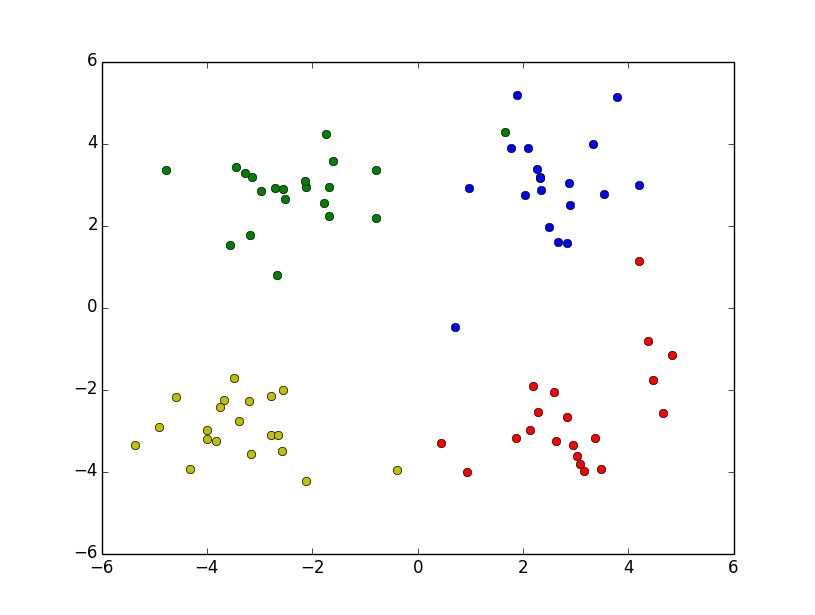
画完图之后发现效果确实不怎么理想,不知道你kMeans算法的问题,还是我的代码的问题

















 1990
1990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









