







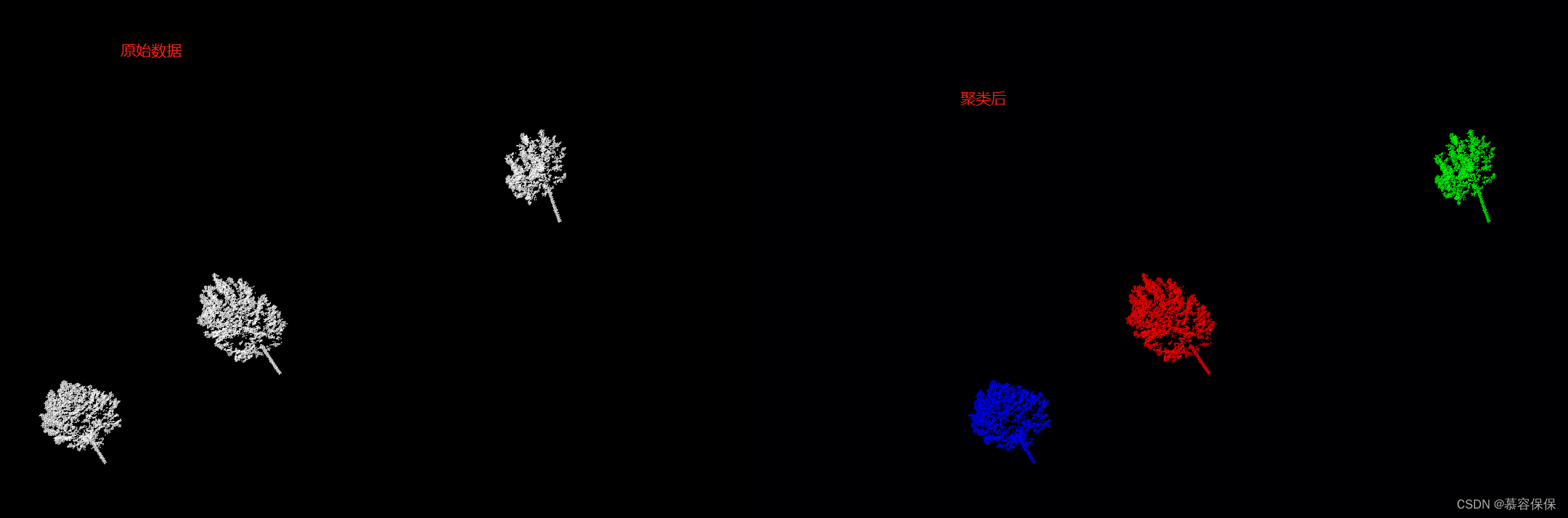
1.结果展示
2.算法原理
K-means 算法是一种基于划分的聚类算法,其原理如下:
1.随机选择 k 个对象,每个对象代表一个聚类的质心。
2.对集合中的每个对象,根据其与各质心之间的距离,把它分配到与之最相似的聚类中。
3.计算每个聚类的质心,质心定义为该聚类中所有对象的均值。
4.重复步骤 2 和 3,直到满足某个终止条件,例如质心的改变小于某个阈值或者迭代次数达到预设的上限。
K-means 算法接受输入量 k ,然后将 n 个数据对象划分为 k 个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。算法以 k 为参数,把 n 个对象分为 k 个簇,以使簇内具有较高的相似度,而且簇间的相似度较低。
3.代码
std::vector<pcl::PointCloud<pcl::PointXYZ
 订阅专栏 解锁全文
订阅专栏 解锁全文















 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









