






一、项目背景与目标
CIFAR10 数据集是图像分类领域的经典基准数据集,包含 10 个不同类别(飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车),每个类别有 6000 张 32×32 像素的彩色图像,共 60000 张图像。本项目旨在基于 PyTorch 框架构建一个 CIFAR10 图像分类模型,并利用 Swanlab 平台对模型训练过程进行实时跟踪与可视化,帮助开发者快速掌握图像分类任务的实现流程,以及如何通过可视化工具优化模型性能。
SwanLab官方文档:
CIFAR10 图像分类![]() https://docs.swanlab.cn/examples/cifar10.html
https://docs.swanlab.cn/examples/cifar10.html
二、环境准备
2.1 安装必要库
项目依赖以下 Python 库:
torch:深度学习框架,用于构建、训练和评估模型。
torchvision:PyTorch 的计算机视觉扩展库,提供 CIFAR10 数据集加载和图像预处理工具。
swanlab:训练跟踪与可视化平台,用于记录训练过程中的指标和模型状态。
tkinter:Python 标准 GUI 库,用于创建图像分类的可视化界面。
Pillow(PIL):图像处理库,用于读取、操作和显示图像。
使用以下命令安装:
pip install torch torchvision swanlab tkinter pillow2.2 注册 Swanlab 账号
访问 Swanlab 官方网站完成账号注册,获取 API Key。在后续代码中,通过 API Key 登录 Swanlab,以便上传训练数据进行跟踪。
2.3 验证 GPU 环境
如果你是第一次进行torch系列软件包的使用,想要在GPU上进行模型训练以加快训练速度,请一定按照下列方式检查torch及cuda是否安装到位,如果没有正确安装,电脑将会使用CPU来进行训练,也可以,就是速度会较慢:
参考往期文章片段:
三、数据加载与预处理
3.1 数据集加载
使用torchvision.datasets.CIFAR10加载数据集,并通过torch.utils.data.DataLoader创建数据加载器,实现数据的批量处理和随机打乱。
from torchvision.datasets import CIFAR10from torchvision.transforms import ToTensor, Compose, Resizefrom torch.utils.data import DataLoader, random_split
# 定义图像预处理操作
transform = Compose([
ToTensor(), # 将图像转换为张量
Resize((224, 224), antialias=True) # 调整图像大小为224x224])
# 加载训练集和测试集
full_dataset = CIFAR10(root='./data', train=True, download=True, transform=transform)# 划分训练集和验证集
train_size = int(0.9 * len(full_dataset))
val_size = len(full_dataset) - train_size
train_dataset, val_dataset = random_split(full_dataset, [train_size, val_size])
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=1, shuffle=False)代码解释:
- Compose将多个图像预处理操作组合起来,ToTensor把图像从 PIL 格式转换为 PyTorch 张量,Resize将图像尺寸调整为 224×224,适配后续使用的 ResNet50 模型。
- random_split将原始训练集按 9:1 比例划分为训练集和验证集,用于模型训练和验证。
- DataLoader创建数据加载器,batch_size指定每次加载的数据量,shuffle=True使数据在每个 epoch 打乱,增加模型训练的随机性。
3.2 数据可视化
使用 Swanlab 平台可视化部分训练数据,直观了解数据集内容。
import swanlab
swanlab.login(api_key="粘贴你的API")
def log_images(loader, num_images=16):
images_logged = 0
logged_images = []
for images, labels in loader:
for i in range(images.shape[0]):
if images_logged < num_images:
logged_images.append(swanlab.Image(images[i], caption=f"Label: {labels[i]}", size=(128, 128)))
images_logged += 1
else:
break
if images_logged >= num_images:
break
swanlab.log({"Preview/CIFAR10": logged_images})
log_images(train_loader, 8)代码解释:
- swanlab.login使用 API Key 登录 Swanlab。
- log_images函数从数据加载器中选取指定数量的图像,将其转换为 Swanlab 的Image对象并添加标签说明。
- swanlab.log将图像数据上传到 Swanlab 平台进行可视化展示。
四、模型构建
采用预训练的 ResNet50 模型,并修改最后一层全连接层以适配 CIFAR10 的 10 个类别。
from torchvision.models import resnet50, ResNet50_Weights
# 加载预训练的ResNet50模型
model = resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)# 修改全连接层输出维度为10
model.fc = nn.Linear(model.fc.in_features, 10)代码解释:
- resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)加载在 ImageNet 数据集上预训练好的 ResNet50 模型。
- model.fc = nn.Linear(model.fc.in_features, 10)将模型最后一层全连接层的输出维度改为 10,使其能够预测 CIFAR10 的 10 个类别。
五、模型训练
5.1 定义训练参数
包括损失函数、优化器、训练轮数等。
import torchfrom torch import nn, optim
# 选择设备(优先使用GPU,否则使用CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# 训练轮数
num_epochs = 5代码解释:
- torch.device根据系统是否支持 GPU 选择训练设备,并将模型移动到对应设备上。
- nn.CrossEntropyLoss定义交叉熵损失函数,适用于多分类任务。
- optim.Adam创建 Adam 优化器,lr设置学习率为 1e-4。
- num_epochs指定模型训练的总轮数。
5.2 训练过程
在每个训练轮次中,遍历训练集进行前向传播、计算损失、反向传播和参数更新,并在验证集上评估模型性能,同时使用 Swanlab 记录训练指标。
import swanlab
swanlab.login(api_key="YOUR_API_KEY")
run = swanlab.init(
project="CIFAR10",
experiment_name="resnet50-pretrained",
config={
"model": "Resnet50",
"optim": "Adam",
"lr": 1e-4,
"batch_size": 32,
"num_epochs": 5,
"train_dataset_num": len(train_dataset),
"val_dataset_num": len(val_dataset),
"device": device,
"num_classes": 10
})
for epoch in range(1, num_epochs + 1):
run.log({"train/epoch": epoch}, step=epoch)
model.train()
train_correct = 0
train_total = 0
for iter, batch in enumerate(train_loader):
x, y = batch
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()
_, predicted = torch.max(output, 1)
train_total += y.size(0)
train_correct += (predicted == y).sum().item()
if iter % 40 == 0:
print(
f"Epoch [{epoch}/{num_epochs}], Iteration [{iter + 1}/{len(train_loader)}], Loss: {loss.item()}"
)
run.log({"train/loss": loss.item()}, step=(epoch - 1) * len(train_loader) + iter)
train_accuracy = train_correct / train_total
run.log({"train/acc": train_accuracy}, step=(epoch - 1) * len(train_loader) + iter)
model.eval()
correct = 0
total = 0
val_loss = 0
with torch.no_grad():
for batch in val_loader:
x, y = batch
x, y = x.to(device), y.to(device)
output = model(x)
loss = criterion(output, y)
val_loss += loss.item()
_, predicted = torch.max(output, 1)
total += y.size(0)
correct += (predicted == y).sum().item()
accuracy = correct / total
avg_val_loss = val_loss / len(val_loader)
run.log({
"val/acc": accuracy,
"val/loss": avg_val_loss
}, step=(epoch - 1) * len(train_loader) + iter)
torch.save(model.state_dict(), 'cifar10_model.pth')
swanlab.finish()代码解释:
- swanlab.login和swanlab.init初始化 Swanlab 训练实验,记录项目名称、实验名称和配置参数。
- 在训练循环中,model.train()将模型设置为训练模式,optimizer.zero_grad()清空梯度,loss.backward()进行反向传播计算梯度,optimizer.step()更新模型参数。
- 每训练 40 个批次,打印当前训练信息,并使用run.log将训练损失记录到 Swanlab。
- 在验证阶段,model.eval()将模型设置为评估模式,with torch.no_grad()关闭梯度计算,计算验证集上的损失和准确率,并记录到 Swanlab。
- 训练结束后,保存模型参数,并调用swanlab.finish()结束实验。
六、创建可视化界面
使用tkinter创建图形用户界面,实现随机展示 CIFAR10 图像或从本地选择图像进行分类预测的功能。
from tkinter import Tk, Button, Label, filedialog
from PIL import Image, ImageTk
import os
import random
import torch
import numpy as np
from torchvision.datasets import CIFAR10
import torchvision.transforms as transforms
def detect_window(model, transform, classes):
root = Tk()
root.title("CIFAR10识别")
root.attributes('-topmost', True)
root.after(0, lambda: root.attributes('-topmost', False))
root.update_idletasks()
width, height = 800, 600
x = (root.winfo_screenwidth() - width) // 2
y = (root.winfo_screenheight() - height) // 2
root.geometry(f"{width}x{height}+{x}+{y}")
root.resizable(False, False)
class_mapping = {
'plane': '飞机',
'car': '车',
'bird': '鸟',
'cat': '猫',
'deer': '鹿',
'dog': '狗',
'frog': '青蛙',
'horse': '马',
'ship': '船',
'truck': '卡车'
}
class_text = "可识别:" + "、".join([f"{class_mapping[cls]}({cls})" for cls in classes])
title_label = Label(root, text=class_text)
title_label.grid(row=0, column=0, columnspan=4, pady=10)
def clear_right_content():
for widget in root.grid_slaves():
if int(widget.grid_info()["column"]) >= 2:
widget.destroy()
def show_random_images():
clear_right_content()
dataset = CIFAR10(os.getcwd(), train=True, download=True, transform=transform)
indices = random.sample(range(len(dataset)), 4)
tensors = []
images = []
for idx in indices:
img, _ = dataset[idx]
tensors.append(img)
img = img.permute(1, 2, 0).cpu().numpy()
img = (img * 255).astype(np.uint8)
img = Image.fromarray(img)
img = img.resize((128, 128))
img = ImageTk.PhotoImage(img)
images.append(img)
result_labels = []
for i in range(4):
label = Label(root, image=images[i])
label.image = images[i]
label.grid(row=i // 2 * 3 + 1, column=2 + i % 2, pady=20)
result_label = Label(root, text="")
result_label.grid(row=i // 2 * 3 + 2, column=2 + i % 2)
result_labels.append(result_label)
def recognize_random_images():
for i, idx in enumerate(indices):
img = tensors[i].unsqueeze(0).to(device)
with torch.no_grad():
output = model(img)
_, predicted = torch.max(output, 1)
predicted_class = classes[predicted.item()]
result_text = f"识别到:{class_mapping[predicted_class]}({predicted_class})"
result_labels[i].config(text=result_text)
recognize_button = Button(root, text="识别", command=recognize_random_images)
recognize_button.grid(row=7, column=2, columnspan=2)
def select_local_image():
clear_right_content()
file_path = filedialog.askopenfilename(filetypes=[("Image files", "*.png;*.jpg;*.jpeg")])
if file_path:
img = Image.open(file_path)
img = img.resize((224, 224))
img_tensor = transform(img).unsqueeze(0).to(device)
if img_tensor.shape[1] == 4:
img_tensor = img_tensor[:, :3, :, :]
img_np = img_tensor.permute(0, 2, 3, 1).cpu().numpy()[0]
img_np = (img_np * 255).astype(np.uint8)
img = Image.fromarray(img_np)
img = ImageTk.PhotoImage(img)
label = Label(root, image=img)
label.image = img
label.grid(row=1, column=2, rowspan=4)
result_label = Label(root, text="")
result_label.grid(row=5, column=2)
def recognize_local_image():
with torch.no_grad():
output = model(img_tensor)
_, predicted = torch.max(output, 1)
predicted_class = classes[predicted.item()]
result_text = f"识别到:{class_mapping[predicted_class]}({predicted_class})"
result_label.config(text=result_text)
recognize_button = Button(root, text="识别", command=recognize_local_image)
recognize_button.grid(row=6, column=2)
random_button = Button(root, text="随机4张图片", command=show_random_images)
random_button.grid(row=1, column=0, pady=10)
local_button = Button(root, text="从本机选择图片", command=select_local_image)
local_button.grid(row=2, column=0, pady=10)
exit_button = Button(root, text="退出", command=root.destroy)
exit_button.grid(row=3, column=0, pady=10)
root.mainloop()代码解释:
- 创建主窗口并设置标题、初始置顶和居中显示。
- clear_right_content函数用于清空窗口右侧的内容,方便重新展示图像。
- show_random_images函数从 CIFAR10 训练集中随机选取 4 张图像,进行格式转换后在界面展示,并提供识别按钮,点击后调用recognize_random_images函数进行分类预测。
- select_local_image函数允许用户从本地选择图像,进行预处理后展示在界面,并实现图像分类预测功能。
- 界面包含 “随机 4 张图片”“从本机选择图片” 和 “退出” 按钮,分别绑定相应功能。
七、完整代码
完整代码及环境已上传至百度网盘:
CIFAR10——百度网盘![]() https://pan.baidu.com/s/1bINgBs5yFimxaSDNT1LoBw?pwd=SWAN
https://pan.baidu.com/s/1bINgBs5yFimxaSDNT1LoBw?pwd=SWAN
需注意:链接中的CIFAR10.zip是所有的源文件,包括环境和程序,文件latest_checkpoint.pth为我的5轮训练结果,放置于与main.py相同目录(即CIFAR10文件夹)中即可试用,测试用图片也已放入网盘链接。
代码运行说明:
先检测有无训练结果,如没有检测到训练结果文件,则打开Swanlab并进行训练,完成后打开检测窗口;
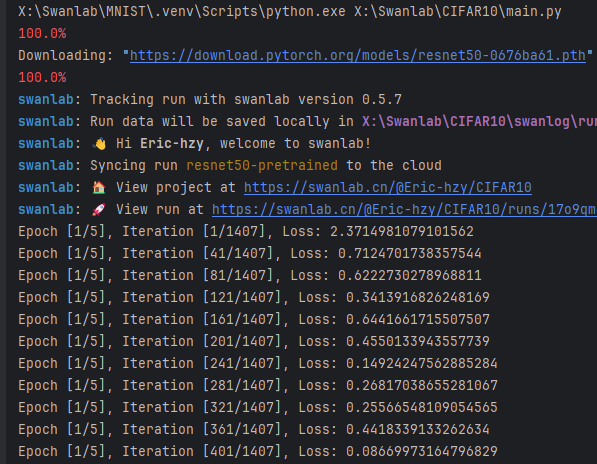
如果检测到CIFAR10文件夹有训练结果(latest_checkpoint.pth),则命令行提示检测到历史训练结果,按y直接打开检测窗口,按n重新进行训练。
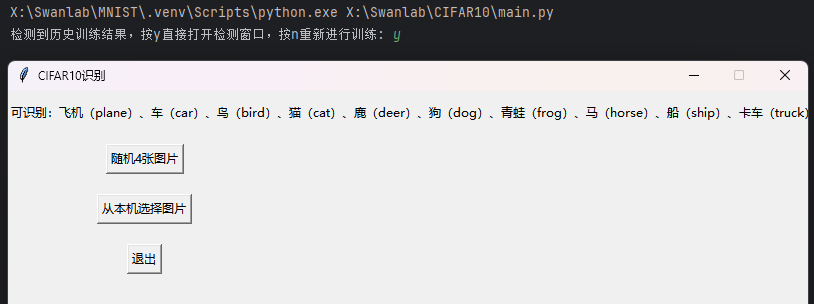
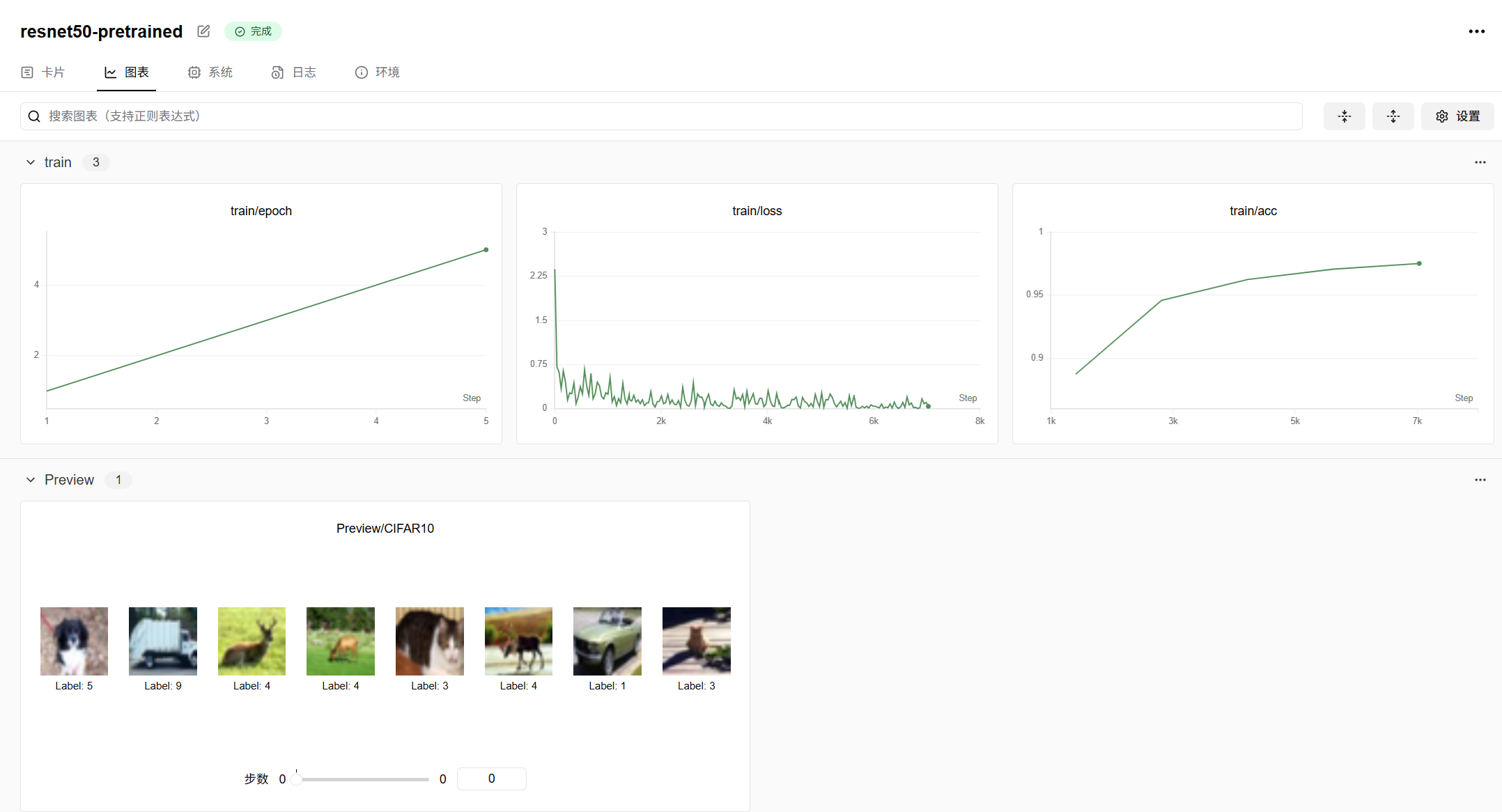
训练成效:(训练结果出乎意料地理想!)
数据集随机展示:
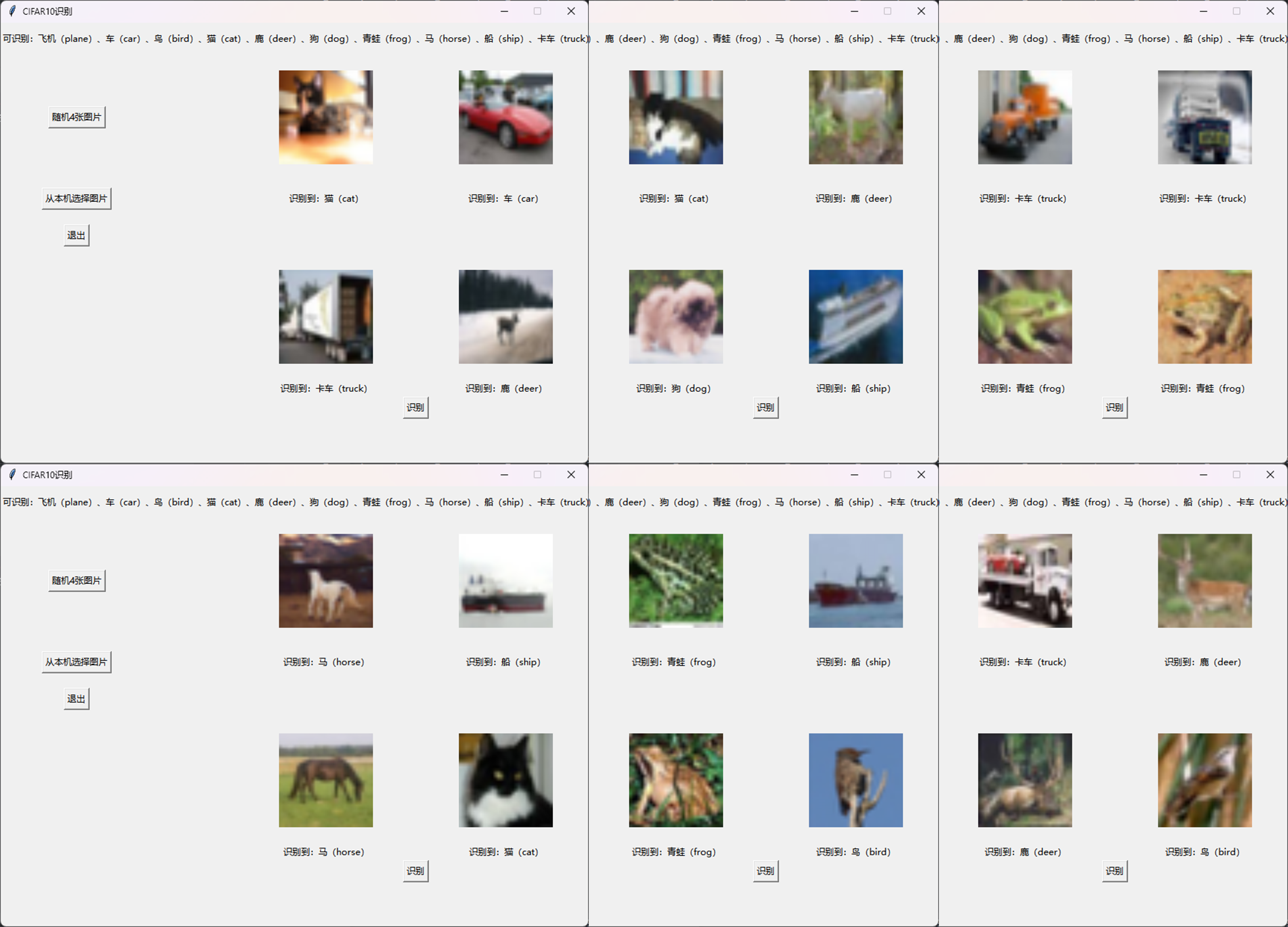
这些图我自己都认不出来:-)
上传图片进行测试:
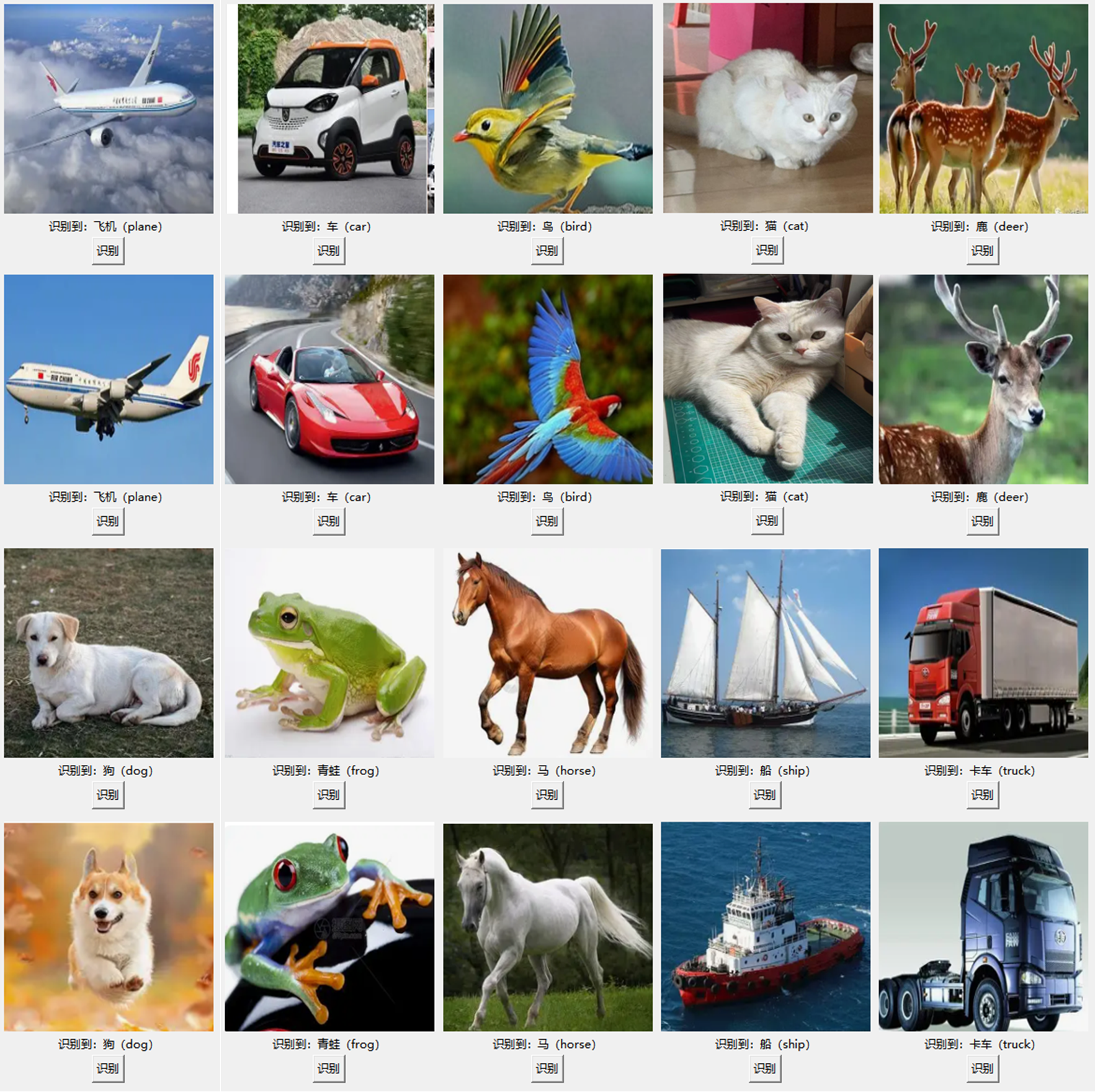
测试用图片已放入网盘链接,效果还不错哦
图片中的猫猫是我家的~
其他图是Bing随机搜到的图
以下是完整代码:
import os
import torch
from torch import nn, optim, utils
import torch.nn.functional as F
import torchvision
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import swanlab
import tkinter as tk
from PIL import Image, ImageDraw, ImageOps
import numpy as np
swanlab.login(api_key="粘贴你的API")
# CNN网络构建
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1,28x28
self.conv1 = nn.Conv2d(1, 10, 5) # 10, 24x24
self.conv2 = nn.Conv2d(10, 20, 3) # 128, 10x10
self.fc1 = nn.Linear(20 * 10 * 10, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x) # 24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) # 12
out = self.conv2(out) # 10
out = F.relu(out)
out = out.view(in_size, -1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out, dim=1)
return out
# 捕获并可视化前20张图像
def log_images(loader, num_images=16):
images_logged = 0
logged_images = []
for images, labels in loader:
# images: batch of images, labels: batch of labels
for i in range(images.shape[0]):
if images_logged < num_images:
# 使用swanlab.Image将图像转换为wandb可视化格式
logged_images.append(swanlab.Image(images[i], caption=f"Label: {labels[i]}"))
images_logged += 1
else:
break
if images_logged >= num_images:
break
swanlab.log({"MNIST-Preview": logged_images})
def train(model, device, train_dataloader, optimizer, criterion, epoch, num_epochs):
model.train()
# 1. 循环调用train_dataloader,每次取出1个batch_size的图像和标签
for iter, (inputs, labels) in enumerate(train_dataloader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# 2. 传入到resnet18模型中得到预测结果
outputs = model(inputs)
# 3. 将结果和标签传入损失函数中计算交叉熵损失
loss = criterion(outputs, labels)
# 4. 根据损失计算反向传播
loss.backward()
# 5. 优化器执行模型参数更新
optimizer.step()
print(
'Epoch [{}/{}], Iteration [{}/{}], Loss: {:.4f}'.format(epoch, num_epochs, iter + 1, len(train_dataloader),
loss.item()))
# 6. 每20次迭代,用SwanLab记录一下loss的变化
if iter % 20 == 0:
swanlab.log({"train/loss": loss.item()})
def test(model, device, val_dataloader, epoch):
model.eval()
correct = 0
total = 0
with torch.no_grad():
# 1. 循环调用val_dataloader,每次取出1个batch_size的图像和标签
for inputs, labels in val_dataloader:
inputs, labels = inputs.to(device), labels.to(device)
# 2. 传入到resnet18模型中得到预测结果
outputs = model(inputs)
# 3. 获得预测的数字
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
# 4. 计算与标签一致的预测结果的数量
correct += (predicted == labels).sum().item()
# 5. 得到最终的测试准确率
accuracy = correct / total
# 6. 用SwanLab记录一下准确率的变化
swanlab.log({"val/accuracy": accuracy}, step=epoch)
class DigitRecognizerApp:
def __init__(self, root, model, device):
self.root = root
self.root.title("数字识别器")
self.model = model
self.device = device
# 创建画布,设置背景为白色
self.canvas = tk.Canvas(root, width=280, height=280, bg="white")
self.canvas.pack()
self.canvas.bind("<B1-Motion>", self.paint)
# 创建清除按钮
self.clear_button = tk.Button(root, text="清除", command=self.clear_canvas)
self.clear_button.pack()
# 创建识别按钮
self.recognize_button = tk.Button(root, text="识别", command=self.recognize_digit)
self.recognize_button.pack()
# 创建结果标签
self.result_label = tk.Label(root, text="结果: ")
self.result_label.pack()
# 创建 PIL 图像和绘图对象,背景为白色
self.image = Image.new("L", (280, 280), 255)
self.draw = ImageDraw.Draw(self.image)
def paint(self, event):
x1, y1 = (event.x - 3), (event.y - 3)
x2, y2 = (event.x + 3), (event.y + 3)
# 绘制黑色椭圆
self.canvas.create_oval(x1, y1, x2, y2, fill="black")
self.draw.ellipse([x1, y1, x2, y2], fill=0)
def clear_canvas(self):
self.canvas.delete("all")
self.image = Image.new("L", (280, 280), 255)
self.draw = ImageDraw.Draw(self.image)
self.result_label.config(text="结果: ")
def recognize_digit(self):
# 调整图像大小为 28x28
img = self.image.resize((28, 28), Image.LANCZOS)
# 反转颜色
img = ImageOps.invert(img)
img = np.array(img) / 255.0
img = torch.tensor(img, dtype=torch.float32).unsqueeze(0).unsqueeze(0).to(self.device)
# 进行预测
with torch.no_grad():
output = self.model(img)
_, predicted = torch.max(output, 1)
result = predicted.item()
# 更新结果标签
self.result_label.config(text=f"结果: {result}")
if __name__ == "__main__":
# 检测是否支持mps
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
# 检测是否支持cuda
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
# 初始化模型
model = ConvNet()
model.to(torch.device(device))
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
checkpoint_path = 'checkpoint/latest_checkpoint.pth'
if os.path.exists(checkpoint_path):
choice = input("检测到训练结果,是否直接使用训练结果进行测试?(y/n): ")
if choice.lower() == 'y':
model.load_state_dict(torch.load(checkpoint_path))
model.eval()
root = tk.Tk()
app = DigitRecognizerApp(root, model, device)
root.mainloop()
else:
# 初始化swanlab
run = swanlab.init(
project="MNIST-example",
experiment_name="PlainCNN",
config={
"model": "ResNet18",
"optim": "Adam",
"lr": 1e-4,
"batch_size": 256,
"num_epochs": 20,
"device": device,
},
)
# 设置MNIST训练集和验证集
dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(dataset, [55000, 5000])
train_dataloader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)
val_dataloader = utils.data.DataLoader(val_dataset, batch_size=8, shuffle=False)
# (可选)看一下数据集的前16张图像
log_images(train_dataloader, 16)
# 加载模型
model.load_state_dict(torch.load(checkpoint_path))
# 开始训练和测试循环
for epoch in range(1, run.config.num_epochs + 1):
swanlab.log({"train/epoch": epoch}, step=epoch)
train(model, device, train_dataloader, optimizer, criterion, epoch, run.config.num_epochs)
if epoch % 2 == 0:
test(model, device, val_dataloader, epoch)
# 保存模型
# 如果不存在checkpoint文件夹,则自动创建一个
if not os.path.exists("checkpoint"):
os.makedirs("checkpoint")
torch.save(model.state_dict(), checkpoint_path)
# 结束Swanlab记录
swanlab.finish()
root = tk.Tk()
app = DigitRecognizerApp(root, model, device)
root.mainloop()
else:
# 初始化swanlab
run = swanlab.init(
project="MNIST-example",
experiment_name="PlainCNN",
config={
"model": "ResNet18",
"optim": "Adam",
"lr": 1e-4,
"batch_size": 256,
"num_epochs": 20,
"device": device,
},
)
# 设置MNIST训练集和验证集
dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(dataset, [55000, 5000])
train_dataloader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)
val_dataloader = utils.data.DataLoader(val_dataset, batch_size=8, shuffle=False)
# (可选)看一下数据集的前16张图像
log_images(train_dataloader, 16)
# 开始训练和测试循环
for epoch in range(1, run.config.num_epochs + 1):
swanlab.log({"train/epoch": epoch}, step=epoch)
train(model, device, train_dataloader, optimizer, criterion, epoch, run.config.num_epochs)
if epoch % 2 == 0:
test(model, device, val_dataloader, epoch)
# 保存模型
# 如果不存在checkpoint文件夹,则自动创建一个
if not os.path.exists("checkpoint"):
os.makedirs("checkpoint")
torch.save(model.state_dict(), checkpoint_path)
# 结束Swanlab记录
swanlab.finish()
root = tk.Tk()
app = DigitRecognizerApp(root, model, device)
root.mainloop()
八、模型评估与结果分析
8.1 训练结果可视化与解读
我的SwanLab训练结果曲线图表:
点击查看我的SwanLab训练结果曲线图表![]() https://swanlab.cn/@Eric-hzy/CIFAR10/runs/17o9qm8gpxzusyt01vpx2/chart
https://swanlab.cn/@Eric-hzy/CIFAR10/runs/17o9qm8gpxzusyt01vpx2/chart
借助 Swanlab 平台,可直观呈现模型训练过程中的各项指标变化趋势:
- 损失曲线:观察训练损失和验证损失曲线,若训练损失不断下降,而验证损失在经过一段时间后开始上升,这表明模型出现过拟合现象,即模型在训练数据上表现良好,但在新数据上的泛化能力较差。例如,模型可能过度学习了训练集中某些图像的特征,而无法准确识别具有不同特征的验证集图像。
- 准确率曲线:训练准确率和验证准确率曲线展示了模型在训练集和验证集上分类能力的提升情况。理想状态下,验证准确率应随着训练推进逐步提高,并趋近于训练准确率。若两者差距较大,如训练准确率远高于验证准确率,同样提示存在过拟合问题;若两者均处于较低水平且增长缓慢,则说明模型可能存在欠拟合,未能有效学习到图像的关键特征。
8.2 模型性能分析与优化策略
- 过拟合问题:若出现过拟合,可采取以下优化措施:
- 数据增强:通过对训练图像进行随机翻转、旋转、缩放、裁剪等操作,扩充数据集的多样性,使模型接触到更多不同形态的图像,降低对特定训练样本的依赖。例如,对 “鸟” 类图像进行水平翻转,模拟不同飞行方向的鸟,增加模型的泛化能力。
- 正则化:在损失函数中引入 L1 或 L2 正则化项,对模型参数进行约束,防止参数过度膨胀,使模型更加简单、泛化能力更强。
- Dropout 技术:在网络训练过程中,随机将部分神经元的输出设置为 0,避免神经元之间过度依赖,增强模型的鲁棒性。
- 欠拟合问题:当模型出现欠拟合时,可尝试以下改进方法:
- 调整模型结构:增加网络层数或神经元数量,提升模型的表达能力,使其能够学习到更复杂的图像特征。例如,从简单的卷积神经网络升级为更深的 ResNet 架构。
- 优化超参数:调整学习率、批次大小等超参数,找到更适合模型训练的参数组合。如适当增大学习率,加快模型收敛速度;调整批次大小,平衡训练速度和稳定性。
- 改进数据预处理:重新审视图像的预处理方式,如调整归一化参数、尝试不同的图像变换方法,使数据更符合模型的学习需求。
- 类别不平衡问题:CIFAR10 数据集中不同类别的图像数量可能存在差异,导致模型对少数类别的识别能力较弱。可通过过采样少数类(如复制少数类图像)、欠采样多数类(减少多数类图像数量),或使用类别加权损失函数,加大对少数类别的训练权重,改善模型在各类别上的分类性能。
九、总结
通过本项目,我们学习了从数据加载与预处理、模型构建、训练,到可视化界面创建的完整图像分类项目流程。利用 Swanlab 平台进行训练跟踪,能直观观察模型训练过程中的指标变化,帮助开发者及时调整模型参数和训练策略。开发者可以在此基础上进一步探索数据增强、模型调优、迁移学习等技术,提升模型在 CIFAR10 数据集上的分类性能 。
十、参考链接
SwanLab:https://swanlab.cn/
SwanLab官方文档:CIFAR10 图像分类
我的SwanLab训练结果曲线图表:点击查看我的SwanLab训练结果曲线图表
以上内容呈现了完整的CIFAR10 图像分类及 Swanlab 训练跟踪流程
训练结果出乎意料地理想!
觉得文章不错的话点个赞吧~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









