






一、引言
(一)项目背景与意义
MNIST 数据集作为机器学习领域的“Hello World”,是由手写数字的图像和对应的标签组成,广泛应用于图像识别和深度学习算法的入门实践。掌握 MNIST 手写文字识别技术,不仅能帮助初学者快速理解深度学习的基本概念和流程,还为后续探索更复杂的图像识别任务奠定基础。而 Swanlab 作为一款强大的训练跟踪工具,能让我们实时监控模型训练过程,分析训练数据,优化模型性能,在深度学习实践中有着不可或缺的作用。
(二)Swanlab 工具介绍
Swanlab 是一款专注于深度学习训练过程管理与分析的工具。它提供了直观的界面,方便用户可视化模型训练的各项指标,如损失函数、准确率等随训练轮次的变化情况。同时,Swanlab 支持记录和对比不同训练配置下的实验结果,帮助开发者快速找到最优的模型参数和训练策略。此外,它还具备数据版本管理功能,能有效管理训练数据和模型版本,提升项目开发效率和管理水平。
SwanLab:MNIST手写体识别![]() https://docs.swanlab.cn/examples/mnist.html
https://docs.swanlab.cn/examples/mnist.html
二、环境搭建
(一)安装 Python 及相关库
在这里,我使用PyCharm软件进行虚拟环境的部署和调试。
首先,确保系统中安装了 Python 环境,建议使用 Python 3.8 及以上版本。可以从 Python 官方网站下载对应操作系统的安装包进行安装。安装完成后,通过命令行工具,使用pip命令安装深度学习所需的库,包括pytorch、torchvision、numpy等。
(二)安装 Swanlab
Swanlab 的安装可以通过其官方提供的安装包或pip命令进行。如果使用pip安装,在命令行中输入pip install swanlab即可完成安装。安装完成后,还需要进行简单的配置,登录Swanlab官网进行账号注册,你会在登录后看到属于你的API,粘贴在
swanlab.login(api_key="粘贴你的API")代码中,以便后续使用 Swanlab 进行训练跟踪。
(三)安装 CUDA
检查显卡兼容性:在 NVIDIA 官方网站查看显卡是否支持 CUDA,确认显卡型号及对应的 CUDA 版本。例如,RTX 30 系列显卡支持 CUDA 11 及以上版本。
使用以下命令下载对应cuda版本的torch:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu128结尾的cu128对应cuda v12.8(也可进行更改),先去NVIDIA官网下载合适的cuda,虽然最新版到了v12.9,但是torch目前应该最高支持到v12.8,所以需要安装旧版本,这里是v12.8的下载链接:
安装 CUDA Toolkit:运行下载的安装包,按照安装向导提示进行操作。安装过程中,可以指定安装路径,建议保留默认路径,以便后续配置。安装完成后,将 CUDA 的安装路径添加到系统环境变量中。在 Windows 系统中,将
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v[版本号]\bin添加到Path变量中。
(四)验证 GPU 环境
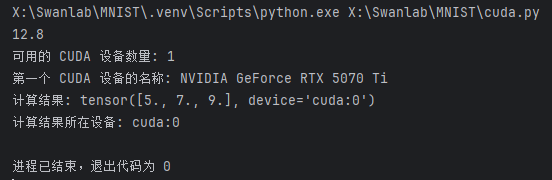
如果你是第一次进行torch系列软件包的使用,想要在GPU上进行模型训练以加快训练速度,请一定按照下列方式检查torch及cuda是否安装到位(如果没有正确安装,电脑将会使用CPU来进行训练,也可以,就是速度会较慢):
这里我安装的是torch v2.7.0对应cuda v12.8,也可以去网上查找适合你的显卡的版本。
运行这个程序可以帮你快速检查cuda状态:
#使用以下命令下载对应cuda版本的torch:
# pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu128
# 结尾的cu128对应cuda v12.8(也可进行更改),先去NVIDIA官网下载合适的cuda
# 虽然v12.9出来了,但是torch目前应该最高支持到12.8
# 运行以下程序可检测cuda是否安装正确
import torch
print(torch.version.cuda)
# 检查 CUDA 是否可用
if torch.cuda.is_available():
# 获取可用的 CUDA 设备数量
num_gpus = torch.cuda.device_count()
print(f"可用的 CUDA 设备数量: {num_gpus}")
# 获取第一个 CUDA 设备的名称
device_name = torch.cuda.get_device_name(0)
print(f"第一个 CUDA 设备的名称: {device_name}")
# 创建一个张量并将其移动到 GPU 上
x = torch.tensor([1.0, 2.0, 3.0], device='cuda')
y = torch.tensor([4.0, 5.0, 6.0], device='cuda')
# 在 GPU 上执行计算
z = x + y
print("计算结果:", z)
print("计算结果所在设备:", z.device)
else:
print("CUDA 不可用,当前使用 CPU 进行计算。")在这里我的运行结果如下:
三、MNIST 数据集准备
(一)数据集介绍
MNIST 数据集包含 60,000 张训练图像和 10,000 张测试图像,每张图像都是一个 28×28 像素的手写数字灰度图,对应的标签是 0 - 9 的数字。这些图像已经过归一化处理,像素值在 0 - 1 之间,并且进行了居中操作,方便模型进行学习和识别。
数据集下载与加载
下载 MNIST 数据集使用的是 torchvision 库。具体来说,是通过 torchvision.datasets.MNIST 类来实现的,示例代码如下:
from torchvision.datasets import MNIST
# 下载并加载MNIST训练集,transform参数用于数据转换,这里将数据转换为张量格式
dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())- os.getcwd() 表示数据集下载的路径,即当前工作目录。
- train=True 表示下载的是训练集,如果设置为 False 则下载测试集。
- download=True 表示如果数据集在指定路径下不存在,则自动下载数据集。
- transform=ToTensor() 是一个数据转换操作,它将 PIL 图像转换为 PyTorch 的张量(Tensor)格式,方便后续在模型中使用。
四、模型构建
(一)选择模型架构
这里选择了一个简单的卷积神经网络(Convolutional Neural Network, CNN)架构。CNN 非常适合处理图像数据,它能够自动学习图像中的特征,通过卷积层、池化层和全连接层来对图像进行分类。在手写数字识别任务中,CNN 能够有效地捕捉数字图像的局部特征,从而实现准确的分类。
(二)搭建模型
以下是代码中搭建模型的部分:
# CNN网络构建
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1,28x28
self.conv1 = nn.Conv2d(1, 10, 5) # 10, 24x24
self.conv2 = nn.Conv2d(10, 20, 3) # 128, 10x10
self.fc1 = nn.Linear(20 * 10 * 10, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x) # 24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) # 12
out = self.conv2(out) # 10
out = F.relu(out)
out = out.view(in_size, -1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out, dim=1)
return out代码解释:
- 类定义:ConvNet 类继承自 nn.Module,这是 PyTorch 中所有神经网络模块的基类。
- 初始化方法 __init__:
- self.conv1 = nn.Conv2d(1, 10, 5):定义第一个卷积层,输入通道数为 1(因为 MNIST 图像是单通道的灰度图像),输出通道数为 10,卷积核大小为 5x5。
- self.conv2 = nn.Conv2d(10, 20, 3):定义第二个卷积层,输入通道数为 10,输出通道数为 20,卷积核大小为 3x3。
- self.fc1 = nn.Linear(20 * 10 * 10, 500):定义第一个全连接层,输入特征数为 20 * 10 * 10(经过卷积和池化后特征图的尺寸),输出特征数为 500。
- self.fc2 = nn.Linear(500, 10):定义第二个全连接层,输入特征数为 500,输出特征数为 10,对应 MNIST 数据集中的 10 个数字类别。
前向传播方法 forward:
- out = self.conv1(x):将输入数据 x 传入第一个卷积层。
- out = F.relu(out):对卷积层的输出应用 ReLU 激活函数,引入非线性。
- out = F.max_pool2d(out, 2, 2):对激活后的输出进行最大池化操作,减小特征图的尺寸。
- out = self.conv2(out):将池化后的输出传入第二个卷积层。
- out = F.relu(out):再次应用 ReLU 激活函数。
- out = out.view(in_size, -1):将卷积层的输出展平为一维向量,以便输入到全连接层。
- out = self.fc1(out):将展平后的向量传入第一个全连接层。
- out = F.relu(out):对第一个全连接层的输出应用 ReLU 激活函数。
- out = self.fc2(out):将第一个全连接层的输出传入第二个全连接层。
- out = F.log_softmax(out, dim=1):对第二个全连接层的输出应用 log_softmax 函数,得到每个类别的对数概率。
通过以上步骤,就完成了一个简单 CNN 模型的搭建。在训练过程中,模型会根据输入的图像数据不断调整参数,以最小化损失函数,从而提高对数字图像的分类准确率。
五、模型训练与 Swanlab 跟踪
在 MNIST 数字识别项目中,模型的构建与训练配置是实现准确识别的核心环节,下面将从模型编译和训练跟踪两方面进行详细阐述。
(一)编译模型
在 PyTorch 框架下,需要指定优化器、损失函数,以完成模型训练前的关键配置工作。
在mnist_digit_recognizer.py代码中,采用Adam优化器和CrossEntropyLoss损失函数对模型进行配置。具体实现代码如下:
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)其中,nn.CrossEntropyLoss是 PyTorch 中用于多分类任务的损失函数,它结合了LogSoftmax和NLLLoss,适用于标签为整数的多分类问题,能够有效计算预测结果与真实标签之间的差距。而optim.Adam是一种自适应学习率优化算法,它根据参数的梯度自动调整学习率,在训练过程中能够更高效地更新模型参数,加速模型收敛。这里将学习率设置为1e-4 ,在实际应用中,可根据模型训练的具体情况对学习率进行调整,以达到更好的训练效果。
(二)使用 Swanlab 进行训练跟踪
为了更好地监控模型训练过程,了解训练进展和模型性能变化,项目引入了 Swanlab 工具进行训练跟踪。
首先,需要在代码中完成 Swanlab 的初始化,并设置实验名称和相关参数。在main.py中,具体操作如下:
swanlab.login(api_key="替换成你的API")
run = swanlab.init(
project="MNIST-example",
experiment_name="PlainCNN",
config={
"model": "ResNet18",
"optim": "Adam",
"lr": 1e-4,
"batch_size": 256,
"num_epochs": 20,
"device": device,
},
)上述代码通过swanlab.login完成登录认证,使用swanlab.init方法初始化实验。在初始化过程中,指定了项目名称为MNIST-example,实验名称为PlainCNN,并在config参数中详细配置了模型类型、优化器、学习率、批量大小、训练轮次以及设备等关键信息。这些信息有助于在 Swanlab 平台上对实验进行全面的记录和管理。
在模型训练过程中,需要将训练的指标数据发送给 Swanlab。在训练函数train和测试函数test中,通过swanlab.log方法实现这一功能。具体代码片段如下:
def train(model, device, train_dataloader, optimizer, criterion, epoch, num_epochs):
# 设置模型为训练模式
model.train()
# 遍历训练数据加载器
for iter, (inputs, labels) in enumerate(train_dataloader):
# 将输入和标签数据移动到指定设备(如GPU或CPU)
inputs, labels = inputs.to(device), labels.to(device)
# 清空优化器的梯度
optimizer.zero_grad()
# 前向传播:通过模型得到输出
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播:计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
# 打印训练信息
print(
'Epoch [{}/{}], Iteration [{}/{}], Loss: {:.4f}'.format(
epoch, num_epochs, iter + 1, len(train_dataloader), loss.item()
)
)
# 每20次迭代记录一次训练损失
if iter % 20 == 0:
swanlab.log({"train/loss": loss.item()})
def test(model, device, val_dataloader, epoch):
# 设置模型为评估模式
model.eval()
correct = 0
total = 0
# 不计算梯度,节省内存和计算资源
with torch.no_grad():
# 遍历验证数据加载器
for inputs, labels in val_dataloader:
# 将输入和标签数据移动到指定设备(如GPU或CPU)
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播:通过模型得到输出
outputs = model(inputs)
# 获取预测结果
_, predicted = torch.max(outputs, 1)
# 统计总样本数
total += labels.size(0)
# 统计预测正确的样本数
correct += (predicted == labels).sum().item()
# 计算准确率
accuracy = correct / total
# 记录验证准确率
swanlab.log({"val/accuracy": accuracy}, step=epoch)在train函数中,每训练 20 个批次,就将当前批次的训练损失通过swanlab.log记录到 Swanlab 平台,键为"train/loss" ,值为当前损失值。在test函数中,每次测试完成后,将测试准确率以"val/accuracy"为键记录到 Swanlab,同时通过step=epoch指定记录的时间步为当前训练轮次。通过这些操作,Swanlab 会自动记录训练和验证过程中的损失函数值、准确率等关键指标,并在 Swanlab 的界面中进行可视化展示,方便开发者直观地观察模型训练的动态过程和性能变化,及时发现问题并对模型进行优化调整。
六、完整样例程序及使用说明:
MNIST打包——百度网盘![]() https://pan.baidu.com/s/1sYi5uIhcUTAzvyTREUa56g?pwd=SWAN
https://pan.baidu.com/s/1sYi5uIhcUTAzvyTREUa56g?pwd=SWAN
链接中的MNIST打包.zip是所有的源文件,包括环境和程序,文件latest_checkpoint.pth为我的200轮训练结果,放置在/checkpoint文件夹中即可试用。
完整样例程序:(记得填写你的SwanLab的API)
在这里登录后获取API:https://swanlab.cn/
import os
import torch
from torch import nn, optim, utils
import torch.nn.functional as F
import torchvision
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import swanlab
import tkinter as tk
from PIL import Image, ImageDraw, ImageOps
import numpy as np
swanlab.login(api_key="替换成你的API")
# CNN网络构建
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1,28x28
self.conv1 = nn.Conv2d(1, 10, 5) # 10, 24x24
self.conv2 = nn.Conv2d(10, 20, 3) # 128, 10x10
self.fc1 = nn.Linear(20 * 10 * 10, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x) # 24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) # 12
out = self.conv2(out) # 10
out = F.relu(out)
out = out.view(in_size, -1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out, dim=1)
return out
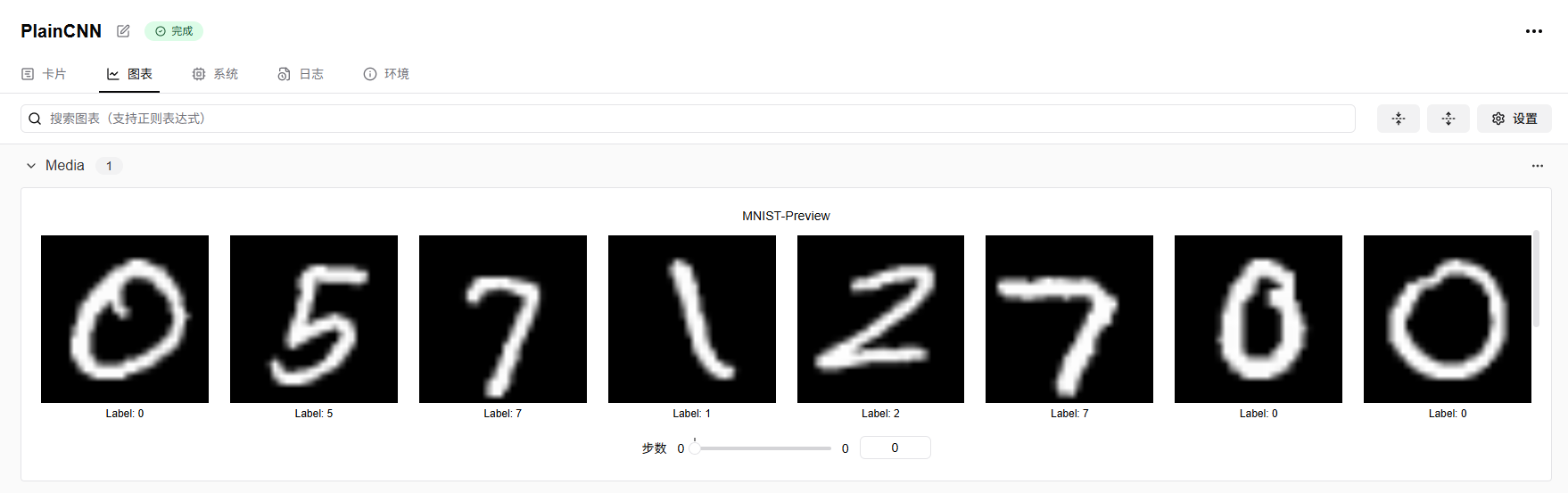
# 捕获并可视化前20张图像
def log_images(loader, num_images=16):
images_logged = 0
logged_images = []
for images, labels in loader:
# images: batch of images, labels: batch of labels
for i in range(images.shape[0]):
if images_logged < num_images:
# 使用swanlab.Image将图像转换为wandb可视化格式
logged_images.append(swanlab.Image(images[i], caption=f"Label: {labels[i]}"))
images_logged += 1
else:
break
if images_logged >= num_images:
break
swanlab.log({"MNIST-Preview": logged_images})
def train(model, device, train_dataloader, optimizer, criterion, epoch, num_epochs):
model.train()
# 1. 循环调用train_dataloader,每次取出1个batch_size的图像和标签
for iter, (inputs, labels) in enumerate(train_dataloader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# 2. 传入到resnet18模型中得到预测结果
outputs = model(inputs)
# 3. 将结果和标签传入损失函数中计算交叉熵损失
loss = criterion(outputs, labels)
# 4. 根据损失计算反向传播
loss.backward()
# 5. 优化器执行模型参数更新
optimizer.step()
print(
'Epoch [{}/{}], Iteration [{}/{}], Loss: {:.4f}'.format(epoch, num_epochs, iter + 1, len(train_dataloader),
loss.item()))
# 6. 每20次迭代,用SwanLab记录一下loss的变化
if iter % 20 == 0:
swanlab.log({"train/loss": loss.item()})
def test(model, device, val_dataloader, epoch):
model.eval()
correct = 0
total = 0
with torch.no_grad():
# 1. 循环调用val_dataloader,每次取出1个batch_size的图像和标签
for inputs, labels in val_dataloader:
inputs, labels = inputs.to(device), labels.to(device)
# 2. 传入到resnet18模型中得到预测结果
outputs = model(inputs)
# 3. 获得预测的数字
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
# 4. 计算与标签一致的预测结果的数量
correct += (predicted == labels).sum().item()
# 5. 得到最终的测试准确率
accuracy = correct / total
# 6. 用SwanLab记录一下准确率的变化
swanlab.log({"val/accuracy": accuracy}, step=epoch)
class DigitRecognizerApp:
def __init__(self, root, model, device):
self.root = root
self.root.title("数字识别器")
self.model = model
self.device = device
# 创建画布,设置背景为白色
self.canvas = tk.Canvas(root, width=280, height=280, bg="white")
self.canvas.pack()
self.canvas.bind("<B1-Motion>", self.paint)
# 创建清除按钮
self.clear_button = tk.Button(root, text="清除", command=self.clear_canvas)
self.clear_button.pack()
# 创建识别按钮
self.recognize_button = tk.Button(root, text="识别", command=self.recognize_digit)
self.recognize_button.pack()
# 创建结果标签
self.result_label = tk.Label(root, text="结果: ")
self.result_label.pack()
# 创建 PIL 图像和绘图对象,背景为白色
self.image = Image.new("L", (280, 280), 255)
self.draw = ImageDraw.Draw(self.image)
def paint(self, event):
x1, y1 = (event.x - 3), (event.y - 3)
x2, y2 = (event.x + 3), (event.y + 3)
# 绘制黑色椭圆
self.canvas.create_oval(x1, y1, x2, y2, fill="black")
self.draw.ellipse([x1, y1, x2, y2], fill=0)
def clear_canvas(self):
self.canvas.delete("all")
self.image = Image.new("L", (280, 280), 255)
self.draw = ImageDraw.Draw(self.image)
self.result_label.config(text="结果: ")
def recognize_digit(self):
# 调整图像大小为 28x28
img = self.image.resize((28, 28), Image.LANCZOS)
# 反转颜色
img = ImageOps.invert(img)
img = np.array(img) / 255.0
img = torch.tensor(img, dtype=torch.float32).unsqueeze(0).unsqueeze(0).to(self.device)
# 进行预测
with torch.no_grad():
output = self.model(img)
_, predicted = torch.max(output, 1)
result = predicted.item()
# 更新结果标签
self.result_label.config(text=f"结果: {result}")
if __name__ == "__main__":
# 检测是否支持mps
try:
use_mps = torch.backends.mps.is_available()
except AttributeError:
use_mps = False
# 检测是否支持cuda
if torch.cuda.is_available():
device = "cuda"
elif use_mps:
device = "mps"
else:
device = "cpu"
# 初始化模型
model = ConvNet()
model.to(torch.device(device))
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
checkpoint_path = 'checkpoint/latest_checkpoint.pth'
if os.path.exists(checkpoint_path):
choice = input("检测到训练结果,是否直接使用训练结果进行测试?(y/n): ")
if choice.lower() == 'y':
model.load_state_dict(torch.load(checkpoint_path))
model.eval()
root = tk.Tk()
app = DigitRecognizerApp(root, model, device)
root.mainloop()
else:
# 初始化swanlab
run = swanlab.init(
project="MNIST-example",
experiment_name="PlainCNN",
config={
"model": "ResNet18",
"optim": "Adam",
"lr": 1e-4,
"batch_size": 256,
"num_epochs": 20,
"device": device,
},
)
# 设置MNIST训练集和验证集
dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(dataset, [55000, 5000])
train_dataloader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)
val_dataloader = utils.data.DataLoader(val_dataset, batch_size=8, shuffle=False)
# (可选)看一下数据集的前16张图像
log_images(train_dataloader, 16)
# 加载模型
model.load_state_dict(torch.load(checkpoint_path))
# 开始训练和测试循环
for epoch in range(1, run.config.num_epochs + 1):
swanlab.log({"train/epoch": epoch}, step=epoch)
train(model, device, train_dataloader, optimizer, criterion, epoch, run.config.num_epochs)
if epoch % 2 == 0:
test(model, device, val_dataloader, epoch)
# 保存模型
# 如果不存在checkpoint文件夹,则自动创建一个
if not os.path.exists("checkpoint"):
os.makedirs("checkpoint")
torch.save(model.state_dict(), checkpoint_path)
# 结束Swanlab记录
swanlab.finish()
root = tk.Tk()
app = DigitRecognizerApp(root, model, device)
root.mainloop()
else:
# 初始化swanlab
run = swanlab.init(
project="MNIST-example",
experiment_name="PlainCNN",
config={
"model": "ResNet18",
"optim": "Adam",
"lr": 1e-4,
"batch_size": 256,
"num_epochs": 20,
"device": device,
},
)
# 设置MNIST训练集和验证集
dataset = MNIST(os.getcwd(), train=True, download=True, transform=ToTensor())
train_dataset, val_dataset = utils.data.random_split(dataset, [55000, 5000])
train_dataloader = utils.data.DataLoader(train_dataset, batch_size=run.config.batch_size, shuffle=True)
val_dataloader = utils.data.DataLoader(val_dataset, batch_size=8, shuffle=False)
# (可选)看一下数据集的前16张图像
log_images(train_dataloader, 16)
# 开始训练和测试循环
for epoch in range(1, run.config.num_epochs + 1):
swanlab.log({"train/epoch": epoch}, step=epoch)
train(model, device, train_dataloader, optimizer, criterion, epoch, run.config.num_epochs)
if epoch % 2 == 0:
test(model, device, val_dataloader, epoch)
# 保存模型
# 如果不存在checkpoint文件夹,则自动创建一个
if not os.path.exists("checkpoint"):
os.makedirs("checkpoint")
torch.save(model.state_dict(), checkpoint_path)
# 结束Swanlab记录
swanlab.finish()
root = tk.Tk()
app = DigitRecognizerApp(root, model, device)
root.mainloop()使用说明:
为方便直观感受训练成效,在这里我将程序分为两个阶段;
首先检测是否已有训练结果,如果有,则询问是否直接开始测试:
y:打开数字识别器窗口,
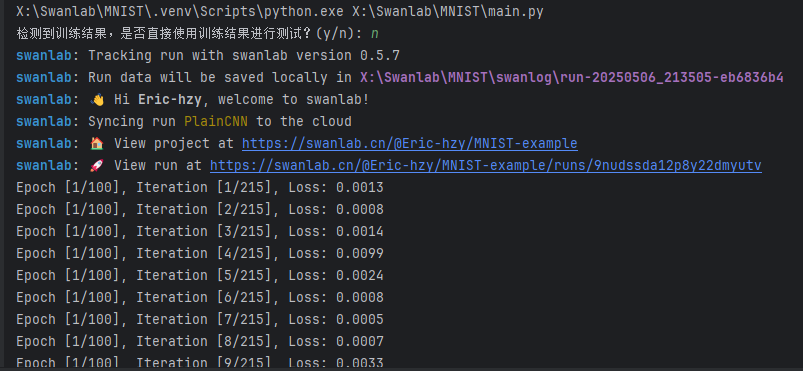
n:进行新一轮训练并替换掉旧的训练结果;
如果未训练过,则开始第一次训练,并保存训练结果以供使用,同时打开数字识别器窗口。
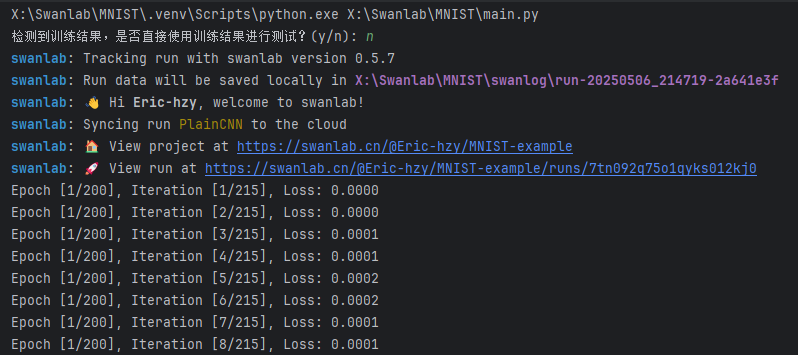
这里进行了200轮训练
在鼠标选中处更改训练轮数(共两处,都要改):
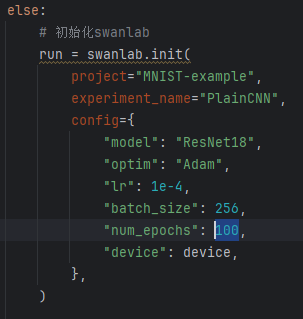
图中为100轮次
测试训练结果:
写字的时候要尽量写大一点,占满识别区域

可以看到结果还是较为理想的,对于各种手写字体都能较好应对
七、模型评估与结果分析
完成 MNIST 数字识别模型训练后,全面评估与深入分析模型,对衡量性能、发现问题及优化模型至关重要,主要从测试集评估与 Swanlab 分析两方面展开。
(一)在测试集上评估模型
在 PyTorch 中,通过测试集评估模型可了解其对未训练数据的处理能力,判断泛化性。main.py利用自定义test函数实现该评估,代码如下:
def test(model, device, val_dataloader, epoch):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_dataloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
swanlab.log({"val/accuracy": accuracy}, step=epoch)
return accuracy代码步骤为:以model.eval()设模型为评估模式,关闭防止过拟合操作;用with torch.no_grad()避免计算梯度,节省内存与加速;遍历测试集val_dataloader,将数据移至指定设备,经模型得预测结果,对比真实标签统计正确与总数;计算准确率并记录到 Swanlab,最后返回准确率。该指标直观反映模型对未知数字的识别能力,准确率高意味着模型可靠性强,低则需优化。
(二)通过 Swanlab 分析训练过程
Swanlab 能实时记录与展示模型训练指标,助力开发者分析训练动态与优化模型。MNIST 项目集成 Swanlab 操作来跟踪训练,打开界面可见系列可视化图表,提供关键信息。
- 损失函数曲线分析:观察损失函数随训练轮次的变化可评估训练状态。曲线下降并后期平稳,表明模型有效学习特征,降低误差达收敛;若波动大、难下降或上升,可能因学习率不当、架构复杂致过拟合或数据有噪声,需调整参数、架构或训练策略。
- 准确率曲线对比分析:对比训练集与验证集准确率曲线可判断是否过拟合。理想情况是两者均上升,但验证集稍慢。若训练后期训练集准确率持续升,验证集降,差距增大,即出现过拟合,此时可通过增加数据量、添加正则化项或用 Dropout 技术提升模型泛化能力。
点击查看我的SwanLab训练结果曲线图表![]() https://swanlab.cn/@Eric-hzy/MNIST-example/runs/7tn092q75o1qyks012kj0/chart
https://swanlab.cn/@Eric-hzy/MNIST-example/runs/7tn092q75o1qyks012kj0/chart
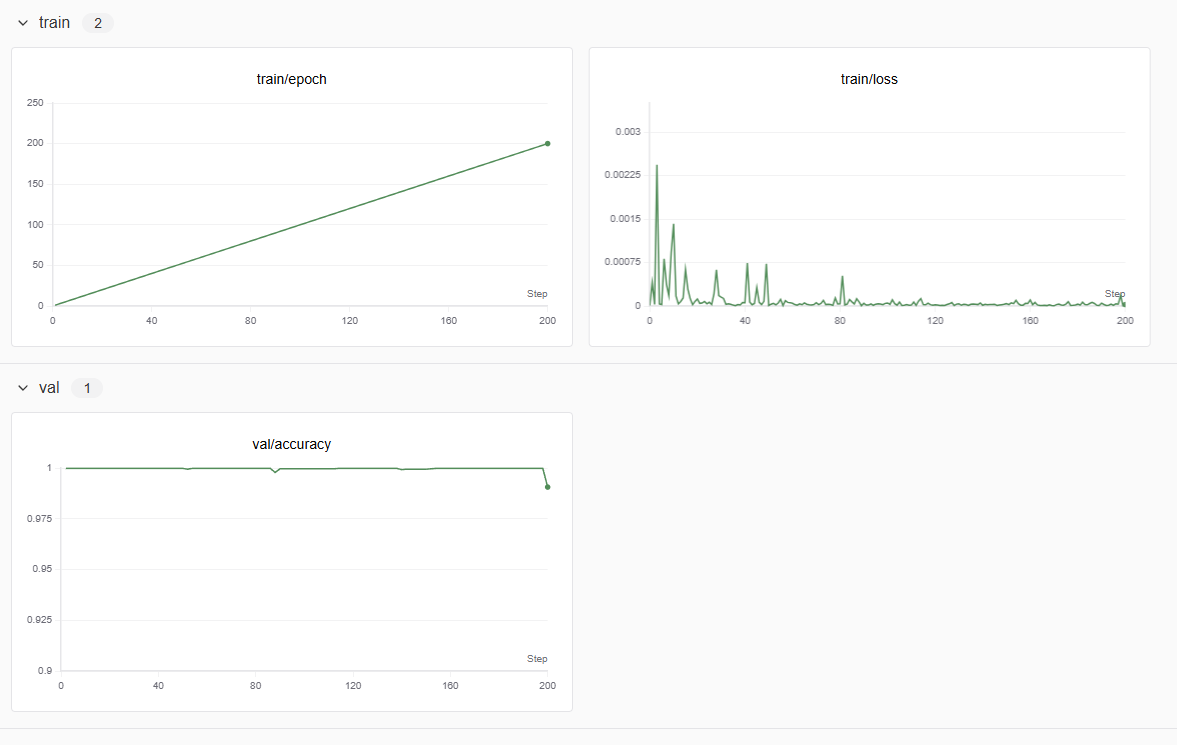
通过分析 Swanlab 图表,开发者能全面掌握模型性能,剖析问题,针对性调整,进而优化模型,提升 MNIST 数字识别的准确性与可靠性。
八、总结与展望
(一)项目总结
通过本次实践,我们从零开始完成了 MNIST 手写文字识别项目,并使用 Swanlab 对训练过程进行了有效跟踪。我们学习了环境搭建、数据集准备、模型构建、训练和评估的全过程,掌握了深度学习在图像识别任务中的基本应用方法,同时也体会到了 Swanlab 在辅助模型训练和优化方面的重要作用。
(二)未来发展方向
虽然我们在 MNIST 数据集上取得了一定的识别效果,但这只是深度学习图像识别的入门阶段。未来,可以尝试使用更复杂的模型架构,如 ResNet、VGG 等,进一步提高识别准确率;探索迁移学习技术,将在 MNIST 数据集上训练好的模型应用到其他类似的手写文字识别任务中;还可以研究如何在实际场景中部署模型,实现手写文字识别的实际应用。
九、参考链接
SwanLab:https://swanlab.cn/
SwanLab官方文档:MNIST手写体识别
我的SwanLab训练结果曲线图表:点击查看我的SwanLab训练结果曲线图表
NVIDIA的Cuda v12.8下载:cuda_12.8.0_571.96_windows.exe
以上内容呈现了完整的 MNIST 手写文字识别及 Swanlab 训练跟踪流程。
也期待您分享在Swanlab进行的跟踪训练~
觉得文章不错的话点个赞吧~

















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









