










目录
2. 任务一:Aspect Term Extraction 具体实现与代码
3. 任务二:Aspect Term Classification 具体实现与代码
4.1 Step 1: 原始数据与预处理 (preProcessing.py)
4.2 Step2: 词向量训练与单词聚类 (word2vecProcessing.py)
4.3 Step3: Aspect Term抽取任务实现(exam_CRF.py)
4.4 Step4: Aspect Term相关上下文构建(contextProcessing.py)
4.5 Step5. Aspect Term分类任务实现 (polClassification_ML.py)
前言
最近整理以前的文档,发现了以前的做课题学习的东西还趟在文件夹。然后突发奇想,不如将以前写的一些基础代码重构下,作个完整的入门教程,从同到尾来整理一篇 “细粒度情感分析 Aspect-Based Sentiment Analysis,ABSA” 的案例教程。一来“缅怀”一去不复返的学生时代,二来也回顾一下之前的工作。(反正都是自己写的,一大堆东西可以直接copy,笑)
PS: 这篇博客可以看做是一个NLP基础教程,用的都是基本的方法,不会出现Bert什么时髦的东西(反正我也不会用,笑)。你可以从这里学习到:文本基本预处理,词向量训练与聚类,CRF序列标注,基本的分类任务。(大概,我写的渣可能讲不清)
PPS: 由于博主现在毕业已经不搞NLP了,博客有勘误那是肯定的,欢迎指出。
PPPS: 如需转载(如果真有人想的话 ( -_- ))请标明出处。 毕竟是博主搬砖加班之余,用仅剩的休息时间慢慢磨出来的。
数据和源码
我知道你想要什么,这里是本博客需要用到的代码数据,和工具,建议读之前都下下来。
本文源码地址(给个星星如何? ): https://github.com/BladeCoda/ABSA_system
------ 数据与工具下载 ---------
SemEval 2014 ABSA 竞赛数据:https://pan.baidu.com/s/18fsF8Bx4yZxpw9gZy2u9Fg
原始数据地址:http://alt.qcri.org/semeval2014/task4/index.php?id=data-and-tools
yelp 餐厅评论语料:https://pan.baidu.com/s/12h7xCFgnlxZX2CWSlmhlBg
原始数据地址:https://www.yelp.com/dataset
amzon电子产品评论语料:https://pan.baidu.com/s/1emRDSdwWYNZ2RePboYq85w
原始数据地址: http://jmcauley.ucsd.edu/data/amazon/
stanford parser网盘备份(本文版本):https://pan.baidu.com/s/17xLGWRqHLvA827jpaQmhEQ
原始下载地址(最新):https://nlp.stanford.edu/software/lex-parser.shtml
你要了解的基础
虽然是ABSA的基础教程,但是还是有些东西需要你掌握一些基础知识了。包括且不仅包括:
- 机器学习与NLP的基本知识
- python 机器学习基础:sklearn, numpy, pandas等使用。
- NLP基本处理库:nltk, gensim等的使用
- Word2vec的基本。
最好还能够了解下文本情感分析与细粒度情感分析的基本需求,这里不会对概念做过多的解析,只是大致介绍一下它们的背景。以上玩意网上有很多学习资源,如何后面的东西你有些不懂,不妨对照上面的列表去学习下。
------------------------------------------------------------- 正文分割线 --------------------------------------------------------------------
1. 细粒度情感分析(ABSA)案例背景
1.1 任务介绍
早期的粗粒度情感分析方法只能获得文本的观点信息,而事实上评价可能中包含着多个对象与方面的评价,而对这些表达对象被赋予的情感倾向可能不尽相同。例如如下评论文本:手机屏幕很清晰,但是电池续航能力太弱了。
很显然,该从文本的角度上看,我们不能直接对判断用户对这个手机的情感是正向还是负向,因为用户对手机的两个方面(Aspect)分别发表的看法,那么我们便能大致知道ABSA的两个任务了,即 情感对象识别 (Aspect Term Extraction),与情感对象倾向分析(Aspect Term Polarity Analysis)。
重本源上看,前者是一个NLP的标注任务(如命名实体识别等),后者则是一个分类任务(针对性地判断Aspect的情感类别)。如下图:
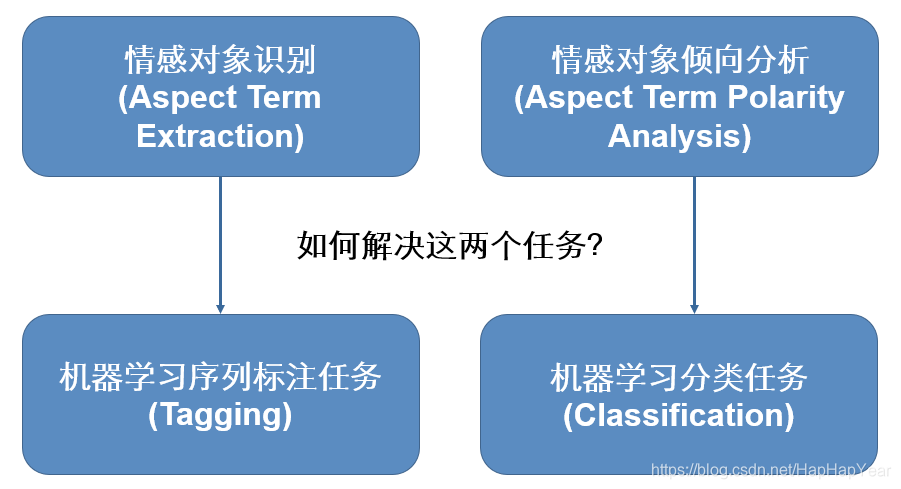
这便是ABSA的主要目标:找到文本中被赋予了情感表达的对象(手机电池,屏幕);然后判断对象具体的情感(屏幕但是电池坏)。这里说的很笼统,下面的案例教程,我们会用一个实际的竞赛任务来展示如何处理这种任务。
这里使用的是Sem-Eval 2014年的ABSA竞赛题目,具体的任务目标请见下面的链接,页面里详细结果了ABSA了具体需求,而我们后面的工作也是完全造这竞赛里的目标来进行的。任务基本也就是上面的Aspect识别与Aspect情感打标两方面。
任务链接(原始数据也在这里哦,当然就是顶上网盘里的数据): http://alt.qcri.org/semeval2014/task4/
当年竞赛总结论文(强烈建议阅读!比看竞赛页面更好):https://www.researchgate.net/publication/266776421_ASPECT_BASED_SENTIMENT_ANALYSIS_SEMEVAL-2014_TASK_4
1.2 数据基本介绍
我知道有人会懒得看数据格式介绍,然后放弃治疗,这里便大致说一下SemEval竞赛的主要目标。
SemEval 的ABSA任务需要参与者标记出文本中情感表达对象的位置,该课题包含以下两个阶段:
阶段一:指定训练文本,对应每一条文本给定个多个起止位置集合,例如{ from:49, to:55 },代表文本字符串的第49个字符到第55个字符为正确的情感对象。对应未标记的测试文本,参赛者需要提交每一条文本对应的情感对象起止位置集合以用于评估。
阶段二:训练文本给定正确情感对象起止位置以及该位置对象正确的情感倾向,例如{from:49, to:55, pol:“positive”}代表文本字符串的第49个字符到第55个字符为正确的情感对象,且情感对象的倾向为正向(positive)。测试文本给定了正确的情感对象起止集合,参赛者需要提交每个位置上的情感对象对应的倾向用于评估。
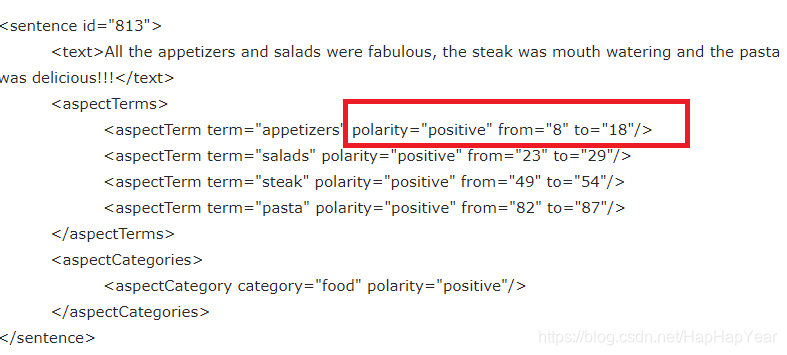
打开一个XML看看,上面的记录代表 ID为813的句子,有4个Aspect(方面),其中appetizer为句子的“第8字节到第18字节”(自己数数吧),它的情感为正向(看句子,appetizer were fabulous)。
那好了,这里你拿到数据就知道两个任务的具体要干嘛了:
任务一:Aspect Term 抽取,训练数据告诉你Aspect Term在句子中的位置(from 和 to),测试数据则没有包含它,要你预测aspect的from和to。
任务二:Aspect Term情感打标,告诉你Aspect Term在句子里的from和to,预测该Aspect Term的polarity(情感极性)。
* 其实在实际场景中,情感打标完全是基于你任务一的识别结果的,但这毕竟是竞赛,任务二你是知道了情感对象的具体位置的。任务一和任务二的评估是分开的。
1.3 如何评估ABSA的结果
还是以竞赛为例,Aspect Term抽取,和Aspect Term情感识别的评估是分开的(具体还是建议你看任务guild,这里只是简单介绍)。
抽取评估:采用SemEval指定的精确率(Precison),召回率(Recall)与F1值(F1-Measure)来进行。对于每条测试文本S,预测的情感对象位置集合为W1(S),真实的情感对象位置为W2(S),指定W1的元素数量为pre(S)(预测的情感对象数量),W2(S)的元素数量为true(S)(真实的情感对象数量),两个集合的交集元素数量为cor(S)(正确预测了位置的情感对象的数量)。设测试文本集合为D,精确率和召回率的计算公式如下:
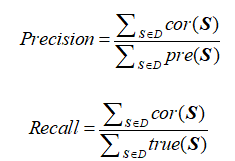
精确率反映了预测的情感对象中正确的比例,召回率反映了预测正确的情感对象占全部情感对象的比例,而F1为精确率与召回率的调和均值。
情感打标评估:由于SemEval语料中含有四种情感类别(Positive、Negative、Neutral和Conflict),指定全部的测试样本数为|D|,被正确分类到四种情感类别的样本数分别为TP1、TP2、TP3和TP4,则分类准确率公式为:
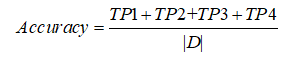
2. 任务一:Aspect Term Extraction 具体实现与代码
PS 背景理论介绍完全基于个人理解,可能有误,欢迎指出。
2.1 这个任务怎么做?
从本源入手,Aspect Term Extraction是一个NLP的序列标注任务,那么我们便可以用CRF,RNN等手段来解决它,这里我只介绍CRF + Word2Vec的解决方案。
机器学习序列标记算法,如隐马尔可夫模型(Hidden Markov Model, HMM)和条件随机场(Conditional Random Field, CRF)等,普遍地被应用于文本序列预测问题,在这类NLP任务中,文本首先需要被转化为一系列观测序列与状态序列。
例如,在进行词性标注任务时,观测序列为文本的单词列表[w1,w2,…,wn],而状态序列则为文本中每个单词对应的词性[p1,p2,…,pn]。训练语料中应当包含每条训练文本对应的单词序列与已标记的词性序列,以作为序列标记模型的输入,通过训练拟合后的模型将可以通过新输入的单词列表(观测序列)来预测其所对应的词性列表(状态序列),到达序列标注的目的。
因此,要使用CRF等模型处理情感对象识别任务,先要将文本转化为一组对应的观测序列与状态序列。观测序列依然是文本的单词列表,而状态序列则为需要使用B, I, O三种状态进行标记,其中,B代表情感对象的起始词,I代表情感对象的延续词,O代表非情感对象词。
以一条手机评论为例,“I think the screen is good but its battery is weak to use”。指定文本中两个情感对象“screen”与“battery”,那么文本的单词序列(观测序列)与情感对象BIO序列如下图:
* 下图例子不是很好,没有"I",“I”只有在连词时出现,如果battery改成两个单词的“inner battery”,那么状态序列就成了"OOOBOOOOBIOOOO "。
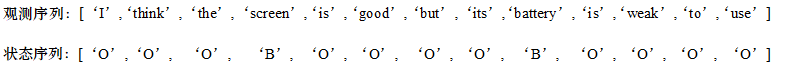
确定了情感对象识别任务所采用的观测序列和状态序列的形式后,便可利用CRF模型来解决该问题,即根据文本的单词序列来预测文本对应的情感对象BIO序列,达到情感对象识别的目的。
2.2 序列特征的构造
本教程介绍的的是传统的序列标记方法 - CRF。强烈建议你在继续阅读前找个CRF的原理介绍看看。
做过分类任务大家应该都很熟悉,是针对训练和测试样本提取特征,然后学习特征与类别直接的分布,传统ML的特征偏向人工统计的,而当下流行的神经网络则偏向与直接对数据做embedding抽象。
其实Tagging任务也是一样的,我们的目标是:通过观测序列来预测状态序列,那么要点也是特征,不过这里的特征不是文本本身的的特征,而是序列某个位置上的特征。
简单来说:分类任务里,你的目标是对文本(n个单词)构造特征,将文本转化为特征向量x = [f1, f2, f3, ..., fn]。而序列标注任务你的目标就对文本每一个位置(通常是单词)构造特征,将文本转化为位置特征列表的列表 x = [[f11,..,f1m], [f21,...,f2m], ,,, [fn1,...,fnm]]。这里的位置特征,传统ML里指的是单词词性,单词编号等,RNN里的位置特征就是某个位置对应的隐含向量。(其实还是和分类特征一样,ML靠手工,NN靠抽象)
例如下面这个样子(先别管图中那些特征是什么,待会会讲)

那么这里Aspect抽取任务的目标就很明确了:“对文本每个位置的单词,构造能够指导其是否为情感对象的特征”。比如情感对象Aspect大多是名词(物体),那么显然,词性就是一个强特征。
由于本教程介绍的是传统ML手段,那么自然后面的工作全是特征构造了 ...... (传统ML依赖人工特征质量,这也是一个槽点,这点和分类任务一样,特征选的好,模型预测才会好。)
------ 以下为我们后面会用到的位置特征 -------
PS 这里提取的特征大多数为效仿当年竞赛TOP选手的方案,建议阅读他们的论文 ,能够让你更加理解为什么这么做。
链接:http://alt.qcri.org/semeval2014/cdrom/pdf/SemEval038.pdf
单词小写:在文本序列标记问题中,单词本身是必须的位置特征之一。由于大小写信息需要单独考虑,单词仅取小写作为位置特征。
单词后缀:单词的后缀一定程度上也能指导单词是否为情感对象,例如,以“-ity”为结尾的单词,如“quality”和“quantity”等,作为文本中情感对象的可能性很大。因此本文提取了位置单词结尾的两个字符和结尾的三个字符作为两个位置特征。
开头是否大写:考虑当前词是否为开头大写,因为大写开头的单词通常以专有名词以及特指词居多,这些词作为情感表达对象的几率较高。
单词词性:由于情感表达对象多为名词等特定词性的单词,因此单词词性是很重要的位置特征之一。
词干特征:除了单词本身外,本文还提取了单词的词干作为CRF的位置特征,来获取单词更为紧凑的语义。
依存句法特征:依存句法分析是一个被广泛使用的文本语义分析方法,它将一个句子构造成一棵依存句法树,依存句法树中每个节点对应句子中的一个单词,其中,根节点为句子的中心词;分支节点的词与其叶子节点的词之间有直接的依赖关系,分别被称为支配词与被支配词。例如,现有一个英文句子“the brave police captured a cunning and tough criminal”,可下图所示的依存句法依赖树。其中句子的中心词(根节点)为“captured”,它直接支配“police”与“criminal”这两个单词。节点中的连线上的标记代表依赖关系的类型例如,(“police”, amod,“brave”)代表单词“police”支配“brave”,依赖关系为“amod”(修饰关系),可理解为“brave”是对“police”的修饰词。
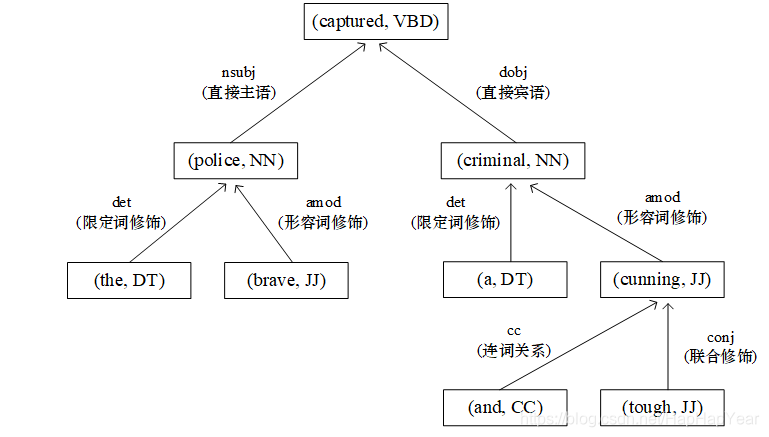
本文提取了与位置相关的几组有效的依存句法特征,分别为:1. 当前位置单词是否在依赖树中作为过“amod”(修饰)关系的支配词,即该单词是否被其他单词修饰过。2. 单词是否作为过“nsubj”(直接主语)关系的被支配词,即该单词是否作为过其他单词的主语。3. 单词是否作为过“dobj”(直接宾语)关系的被支配词,即该单词是否作为过其他单词的直接宾语。
以上三种依赖关系能一定程度上指导情感对象的识别,例如,被修饰(支配有其他修饰单词)过得单词作为情感对象的可能性更大。
Word2Vec聚类特征:这是当年竞赛TOP选手的核心做法(14年那会Word2Vec正是引爆潮流的时候勒。),
再次放上论文链接:http://alt.qcri.org/semeval2014/cdrom/pdf/SemEval038.pdf
简单来说,就是引入大量外部领域内的文本数据,来训练词向量,然后对词向量做聚类,构建每一个单词的语义类别,然后把这个类别作为单词位置特征。这里不会将词向量的知识,建议阅读博客 “Word2Vec数学原理” 并研读上面的论文。
3. 任务二:Aspect Term Classification 具体实现与代码
3.1 这个任务怎么做
当你定位了情感对象的位置后,下一步任务就是对情感对象进行“极性分析”了。事实性,这个任务的本质和篇章级文本情感分析没有太大差异。不同点在于,在篇章级任务中,你是对整篇文本做特征向量表示,而对情感对象做特征表示时,你应该考虑的是那些“与当前情感对象有直接关联的文本”。
当然,上面说的那种还是传统ML的做法,即抽取情感对象相关文本,然后对提取文本做特征表示。如果想了解当前AI领域使用端到端网络的处理方式,那就要自己去学习专研的,这只是个抛转引玉的ABSA入门教程。这里我根据指定位置的情感对象,提取了两种文本。
1. 窗口上下文:这个基本有点数据处理经验的都能想到,比如句子[W1,W2,W3,W4,W5,W6,W7,...],W3为情感对象,我们这里可以去窗口大小为2的上下文[W1,W2,W3, W4, W5]作为相关文本。
2. 文法关联词:窗口上下文有个很大的问题,那就是对情感对象表达了观点的词极可能在位置上离情感对象很远,那么这里我利用了前面提到的文法分析,对W3的上下文W1~W5,各种提取了其在文法树上有关系的单词。如下图:
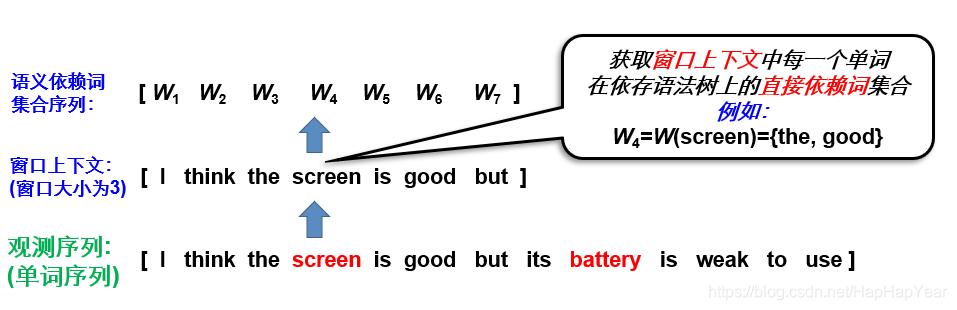
通过文法分析,screen这个单词和the与good具备依存关系,那么我们把它们提取出来做相关文本。但对screen做依存词抽取肯定是不够的,这里我对I,think,the,scree,is,good,but这7个单词都抽取了依存词作为相关文本。
好了,现在我们有了一些情感对象的相关文本了,那么对情感对象的情感分析任务就转变成了对情感对象相关文本的分析任务了,比如喜闻乐见的词向量平均大法,当然你也可以用text-CNN做分类。由于如果涉及NN,文章篇幅会指数上升,这里就只介绍万能词向量平均。
---------------------------------------------------------- 分割线,以下为实践代码讲解----------------------------------------------------
4. 代码实现
* 建议去把我的github源码下下来对照看(再次无耻暗示给星星):https://github.com/BladeCoda/ABSA_system
下面代码只是摘选讲解,贴出来的只是关键步骤的代码,具体内部的某些方法实现不可能在博客里一句句给你贴的 \ (-_-) /。
4.0 Step 0: 准备工作
1. 在运行代码前,你需要安装如下重要的python库(pip安装即可)
gensim, nltk, python-crfsuite,(其他sklearn,pandas什么的不列了,安个anaconda即可)
2. 其中python-crfsuite为crf模型依赖库,导入用import pycrfsuite。
3. nltk安好后并不能直接使用,需要在python里执行nltk.download()下载模型和语料,这是必须的,否则无法进行词性标注等任务。
4. 代码有用到stanford parser,nltk可以调用其接口,但是工具需要自行下载(链接见顶上),工程目录下有个空的stanford parser目录,将下载的stanford parser内容全部解压到该目录即可。
5. 代码总体执行分为5步走,见boot.py,建议每一步单独执行评估。后面的每一小节的介绍使用的代码与boot.py里的每个step是对应起来的。
# -*- coding: utf-8 -*-
from preProcessing import *
from word2vecProcessing import trainingEmbedding, createCluster
from exam_CRF import evaluate
from contextProcessing import createAllForPol
from polClassification_ML import examByML
if __name__ == '__main__':
print('#### Step1. Preprocessing')
# 对原始数据做预处理
transformJSONFiles(d_type='re')
transformJSONFiles(d_type='lp')
createAllDependence()
depend_list=loadDependenceInformation('dependences/re_train.dep')
print('#### Step1. Word2Vec and Clutering')
# 训练词向量与聚类
trainingEmbedding(300,'re',True)
createCluster(100,'re')
trainingEmbedding(300,'lp',True)
createCluster(200,'lp')
print('#### Step3 evaluate for Aspect Term Extraction')
all_terms,all_offsets,origin_text_test,true_offsets=evaluate(False,'re')
all_terms,all_offsets,origin_text_test,true_offsets=evaluate(False,'lp')
print('#### Step4 context Processing')
createAllForPol(d_type='re',context=5)
createAllForPol(d_type='lp',context=5)
print('#### Step5 evaluate for Aspect Term Classification')
examByML('re','SVM',0.8)
examByML('lp','SVM',0.8)
4.1 Step 1: 原始数据与预处理 (preProcessing.py)
首先第一步先不记得处理竞赛数据,我们先把附加的yelp和amzon数据预处理后,由json整成.统一形式csv方便后面处理。
#读取额外的数据并转化为CSV文件
def transformJSONFiles(d_type='re',all_text=False,text_num=200000):
if d_type=='re':
filepath='data/extra/yelp/yelp_academic_dataset_review.json'
outpath='data/extra/yelp/Restaurants_Raw.csv'
text_item='text'
else:
filepath='data/extra/amzon/Electronics_5.json'
outpath='data/extra/amzon/LapTops_Raw.csv'
text_item='reviewText'
print('开始加载JSON并获取其文本.....')
review_list=[]
if d_type=='re':
with open(filepath,'r') as f:
items_list=f.readlines()
#是否获取所有的文本
if all_text==False:
items_list=items_list[:text_num]
#一个个解析
for item in items_list:
json_dict=json.loads(item)
review_list.append(' '.join(nltk.word_tokenize(json_dict[text_item])))
else:
count = 0
with open(filepath,'r') as f:
items_list=f.readlines()
#一个个解析
for item in items_list:
json_dict=json.loads(item)
words=nltk.word_tokenize(json_dict[text_item])
words1=[word.lower() for word in words]
if 'notebook' in words1 or 'laptop' in words1:
review_list.append(' '.join(words))
count += 1
if all_text==False and count > text_num:
break
print('评价文本加载完毕,转化为CSV文件')
output=pandas.DataFrame({'text':review_list})
output.to_csv(outpath,index=False)
print('转化完成!!')由于文件很大,可以只选部分文本。amzon的文本处理有点不同,因为评论是“电子产品”的评论,而竞赛需要的是“笔记本”的文本,因此简单地去包含“notebook”和“laptop”的评论。该步骤会比较慢,完成后,会生成Restaurants_Raw.csv和LapTops_Raw.csv文件。
然后预处理第二步,我们用stanford parser提取竞赛数据的“语义依赖关系”,这里先得对竞赛数据构造entity, 我参照了semeval当年的baseline。我的github工程有注释标注过得baseline,可以看看但是这里不会细讲,里面就是简单的数学统计,效果很差,这里只是借用了其实体构造部分,具体内容见entity.py。将原始数据整成Corpus对象后,就可以用nltk调用stanford parser,做依赖分析了。
def createDependenceInformation(inputfile,outputfile):
corpus=loadXML(inputfile)
texts=corpus.texts
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
sent_num=[]
all_sents=[]
print('分句开始')
for text in texts:
#对文本分句
sents=tokenizer.tokenize(text)
sents=[nltk.word_tokenize(sent) for sent in sents]
all_sents.extend(sents)
sent_num.append(len(sents))
print('解析开始')
eng_parser = StanfordDependencyParser(r"stanford parser/stanford-parser.jar",
r"stanford parser/stanford-parser-3.6.0-models.jar")
res_list=list(eng_parser.parse_sents(all_sents))
res_list=[list(i) for i in res_list]
depends=[]
#遍历每组关联
for item in res_list:
depend=[]
for row in item[0].triples():
depend.append(row)
depends.append(depend)
print('解析完成,开始切分')
index=0
depend_list=[]
for num in sent_num:
depend_list.append(depends[index:index+num])
index+=num
print('切分完成,开始保存')
with open(outputfile,'wb') as f:
pickle.dump(depend_list,f)
print('完成。')完成后会在dependences目录下生成.dep文件,用preProcessing.py里的loadDependenceInformation方法读取一个看看,大致效果如下:
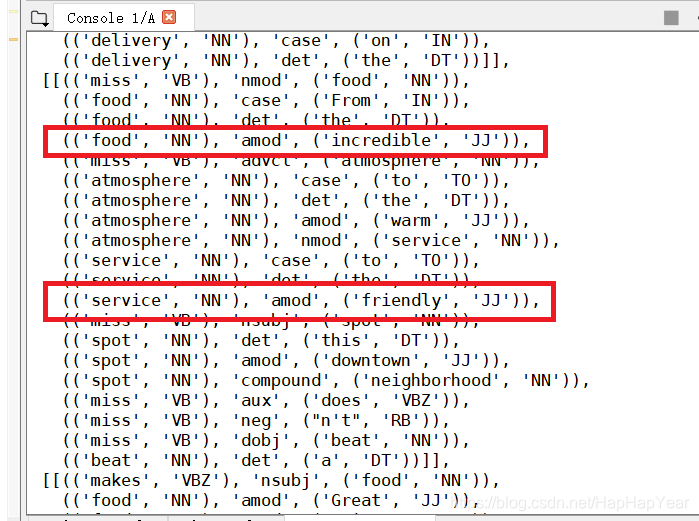
比如上面解析后,可以知道service和friendly是"amod"(被修辞)关系。当然还有很多其他有用的信息,上面stanford parser里各个标签的含义,建议自己去官网学习下。
4.2 Step2: 词向量训练与单词聚类 (word2vecProcessing.py)
上面无论哪个任务,都用到了词向量,由于竞赛数据数量实在太少,拿它做训练当然不够。这里边会要用到前面整理的额外文本了。
#训练词向量
def trainingForWords(texts,fnum,filepath,sg,hs):
#设定词向量参数
sentences=[text.lower().split(' ') for text in texts]
print('分词完成,开始训练')
num_features=fnum #词向量的维度
min_word_count=3 #词频数最低阈值
num_workers=8 #线程数,想要随机种子生效的话,设为1
context=10 #上下文窗口大小
downsampling=1e-3 #与自适应学习率有关
num_iter=15 #没有加额外数据时,设置为100最佳(添加额外数据后30最佳)
hs=hs
sg=sg#是否使用skip-gram模型
model_path=filepath
model=Word2Vec(sentences,workers=num_workers,hs=hs,
size=num_features,min_count=min_word_count,seed=77,iter=num_iter,
window=context,sample=downsampling,sg=sg)
model.init_sims(replace=True)#锁定训练好的word2vec,之后不能对其进行更新
model.save(model_path)#讲训练好的模型保存到文件中
print('训练完成')
return model
def trainingEmbedding(vector_len=150,d_type='re',add_extra=False):
if d_type=='re':
d_name='Restaurants'
extraFile='data/extra/yelp/Restaurants_Raw.csv'
else:
d_name='LapTops'
extraFile='data/extra/amzon/LapTops_Raw.csv'
print('------训练%s数据的Word2Vec------'%d_name)
train_corpus=preProcessing.loadXML('data/origin/%s_Train_v2.xml'%d_name)
test_corpus=preProcessing.loadXML('data/origin/%s_Test_Data_PhaseA.xml'%d_name)
print('数据集合并完成')
corpus=train_corpus.corpus
corpus=train_corpus.corpus+test_corpus.corpus
del train_corpus
del test_corpus
bio_entity=entity.BIO_Entity(corpus,d_type)
texts=bio_entity.texts
if add_extra==True:
print('添加额外语料:%s'%extraFile)
extra_csv=pandas.read_csv(extraFile,encoding='gbk')
extra_texts=list(extra_csv['text'])
texts=texts+extra_texts
del extra_csv
del extra_texts
print('额外语料加载完成')
print('创建WordEmbedding')
trainingForWords(texts,vector_len,'model/%s.w2v'%d_name,1,0)
print('创建WordEmbedding_CBOW')
trainingForWords(texts,vector_len,'model/%s.w2v_cbow'%d_name,0,0)训练完成后会在model下生成.w2v和w2v_cbow文件,前者为skipgram模型,后者为cbow模型。虽然两者都是词向量,但之所以训练两组是为了丰富后面的特征。
在后面要进行特征抽取任务中,我们当然不能直接把单词的词向量丢到CRF里去学习(这可不是LSTM这种NN模型,要CRF学习词向量的每一维的转换关系,消耗上是不能接受的,且没有意义),这里合理做法是我之前提到的TOP选手的做法,将全体单词词向量做Kmeans聚类,每一个单词都会得到一个聚类类别,反映了其大体语义,我们将单词的类别作为CRF的位置特征。
#对词向量进行聚类处理
def kmeansClusterForW2V(filepath,outpath,cluster_num):
W2Vmodel=loadForWord(filepath)
vocab=list(W2Vmodel.wv.vocab.keys())
vectors=[W2Vmodel[vocab[i]] for i in (range(len(vocab)))]
print('开始聚类')
clf=KMeans(n_clusters=cluster_num,random_state=77)
clf.fit(vectors)
print('聚类完成,开始讲词典转化为类别字典')
dict_re={vocab[i]:clf.labels_[i] for i in range(len(vocab))}
print('保存字典。。。。')
with open(outpath,'wb') as f:
pickle.dump(dict_re,f)
return dict_re这里就是为什么要训练skipgram和cbow两个模型的原因了,对两套词向量做聚类可以抽出两个CRF位置特征来。聚类完成后会在cluster目录下生成聚类保存结果。
这两步是整体流程了最耗时间的,如果电脑吃不消,可以把词向量训练的迭代次数调低一点。
4.3 Step3: Aspect Term抽取任务实现(exam_CRF.py)
前面准备工作都做充分了,终于可以开始进行Aspect Term抽取任务了。这里的代码依赖太多,实在不好贴,这里放上大体的流程,建议对应源码一个个看看里面方法的具体实现:
def evaluate(detail=False,d_type='re'):
if d_type=='re':
d_name='Restaurants'
else:
d_name='LapTops'
print('加载并处理训练数据集')
train_corpus=preProcessing.loadXML('data/origin/%s_Train_v2.xml'%d_name)
train_bio=preProcessing.createBIOClass(train_corpus.corpus,d_type)
dep_path='dependences/%s_train.dep'%d_type
train_bio.createDependenceFeature(dep_path)
train_X,train_Y=train_bio.getFeaturesAndLabels()
print('加载并处理测试数据集')
test_corpus=preProcessing.loadXML('data/origin/%s_Test_Data_phaseB.xml'%d_name)
test_bio=preProcessing.createBIOClass(test_corpus.corpus,d_type)
dep_path='dependences/%s_test.dep'%d_type
test_bio.createDependenceFeature(dep_path)
test_X,test_Y=test_bio.getFeaturesAndLabels()
true_offsets=[]
for i in range(len(test_bio.instances)):
offset=[a.offset for a in test_bio.instances[i].aspect_terms]
true_offsets.append(offset)
origin_text_test=test_bio.origin_texts
train_X,test_X=crfFormat_X(train_X,test_X)
train_CRF(train_X,train_Y)
predict_Y,tagger=tag_CRF(test_X)
report=report_CRF(test_Y,predict_Y)
print('\n--------结果报告如下(BIO基准)---------')
print(report)
if detail==True:
print('\n--------其他关键信息(BIO基准)---------')
info=tagger.info()
print("可能性最高的状态转移:")
print_transitions(Counter(info.transitions).most_common(10))
print("\n可能性最低的状态转移:")
print_transitions(Counter(info.transitions).most_common()[-10:])
print("\n最强的特征关联:")
print_state_features(Counter(info.state_features).most_common(10))
print("\n最弱的特征关联:")
print_state_features(Counter(info.state_features).most_common()[-10:])
all_terms=[]
for i in range(len(origin_text_test)):
all_terms.append(getTermsFromYSeq(predict_Y[i],origin_text_test[i]))
all_offsets=[]
for i in range(len(origin_text_test)):
all_offsets.append(getOffestFromText(all_terms[i],origin_text_test[i]))
print('\n--------SemEval基准报告如下---------')
semEvalValidate(all_offsets,true_offsets, b=1)
return all_terms,all_offsets,origin_text_test,true_offsets逻辑上其实非常简单:第一步,加载训练/测试数据,按照2.2介绍的步骤构造文本的位置特征序列(train_X, test_X),与对应的BIO训练(train_Y,test_Y);第二步,把train_X和train_Y喂给CRF学习(自豪的调包侠);第三步,把test_X喂给训练好的CRF,然后用真实的标签test_Y做评估即可。标准的机器学习流程,只不过这里多了一步在原始数据里检索Aspect Term的步骤,这是任务评估需要和训练每关系(检索写的不是很完美,待会讲)。
训练完成,返回all_terms(预测的所有测试文本对应的情感对象),all_offsets(预测情感对象在文本中的位置),origin_text_test(原始测试文本集)和true_offsets(测试文本真实的情感对象位置)。我们先看看all_terms里的内容:

可以看到,效果还行,大多数抽出来的词(如food, prices)都是能反映餐厅某一方面的"情感对象", 下面是一个完美预测的案例,可以看到预测的情感对象的文本序列范围和真实值是完全一样的:

最后,分别针对“餐厅”(上图)和“笔记本”(下图)数据集,我们可以输出评估报告,如下:
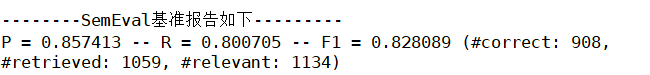

可以看到,识别的查准率还是可以得,但是在“笔记本”数据集上,识别的查重率还是不够看,只有66.2%的对象被抽取处理。对比下当年比赛的结果:
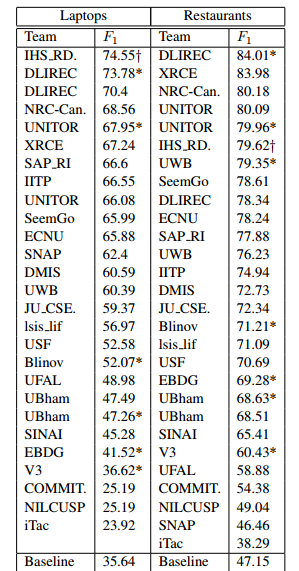
DLIREC就是本博客复现的方法(即上面论文链接的方法),可以看到餐厅数据集的F1值没能复现出当年的效果,但是笔记本数据集基本持平当年结果了(甚至好一丢丢,不过这毕竟自己线下跑的结果,不能完全信,玩过数据比赛都懂的)。这也说明笔记本数据的对象相对更难抽取一点,毕竟评论电脑和评论餐厅,考虑的东西就更多了,这大概也是这个比赛设置此两组数据的初衷把
**这份代码的缺陷 **:
如果看看运行的打印你会发现这份代码会输出下面的错误信息:

这是由于当前代码分词直接调的nltk的英文分词,它对标点等特殊符号的切分很玄学,如果你抽取的AspectTerm和分词的结果标点上存在偏差。比如上面的文本切词"(appetizer)" 是一个单词,但是实际抽取"(","appetizer",")"是3个单词,于是在原始文本里就找不到offset了。
这里大家可以直接自己写个分词(毕竟英文,分词比中文容易多了),或者尝试其他修复,我就不修复了,问就是懒。。。。。。毕竟也不是很多。
4.4 Step4: Aspect Term相关上下文构建(contextProcessing.py)
现在知道到文本的情感对象,下一步就是判断它就是“是好是坏”了。参照第三小节,我们抽取分别抽取train和test数据集每个Aspect Term对于的上下文。注意,比赛为了方便评估,Aspect Term给出的都是真实值,也就是说,后面评估分类的效果,你不需要考虑前面抽取做的好不好,因为比赛这两个榜时分开打的。
def createFeatureFileForPol(inputpath,deppath,outpath,context,d_type):
print('加载数据')
corpus=preProcessing.loadXML(inputpath)
dep_list=preProcessing.loadDependenceInformation(deppath)
instances=corpus.corpus
aspectTermList=[]
texts_list=[]
aspectContextList=[]
bio_entity=entity.BIO_Entity(instances,d_type)
bio_entity.createPOSTags()
bio_entity.createLemm()
print('获取基础信息')
for i in range(len(bio_entity.texts)):
texts_list.append(bio_entity.texts[i])
aspectTermList.append(bio_entity.instances[i].aspect_terms)
for i in range(len(texts_list)):
for term in aspectTermList[i]:
aspectContext=AspectContext()
aspectContext.createBasic(term.term,term.pol,context)
aspectContext.createContext(texts_list[i].split(' '))
aspectContext.createDepContext(dep_list[i])
if aspectContext.isvalid==True:
aspectContextList.append(aspectContext)
print('切分完成,开始保存')
with open(outpath,'wb') as f:
pickle.dump(aspectContextList,f)
print('完成。')这部分没什么好将的,就是去情感对象前后单词,和与情感对象存在语义依赖的单词,具体实现还需见源码。完成后会在contextFiles目录下生成.cox的文件。
4.5 Step5. Aspect Term分类任务实现 (polClassification_ML.py)
最后,我们便可以使用Aspect Term的相关上下文来用各种各样的机器学习算法做分(diao)类(bao)预测了。还需注意一下,这里我用到的是CV校验(即交叉验证),即把训练数据里的Aspect Term抽一部分(80%)处理训练,然后预测剩下的Aspect Term的情感倾向。
为咋?因为你看看Test文件里,是没有Aspect Term的真实情感标记的,这里我们实验没法用到Test数据集。而之前的抽取任务因为Test数据集含有真实的Aspect Term信息因此才能做到模拟线上打分。换言之,本小节的评估结果和原始竞赛的评估会有较明显的出入(CV不见得的反响线上成绩,做过数据竞赛的都懂的*2)。
def trainClassifier(trainX,trainY,classifier='SVM'):
if classifier=='SVM':
print('使用SVM进行分类器训练')
clf=LinearSVC()
clf=clf.fit(trainX,trainY)
print('训练完成')
else:
print('使用逻辑斯蒂')
lr=LogisticRegression()
lr=lr.fit(trainX,trainY)#用训练数据来拟合模型
print('训练完成')
clf=lr
return clf
def predict(testX,testY,clf):
print('开始预测')
true_result=clf.predict(testX)
pre_result=testY
print('分类报告: \n')
print(classification_report(true_result, pre_result,digits=4))
clf.score(testX,testY)
def examByML(d_type='re',classifier='SVM',per=0.8):
if d_type=='re':
filepath='contextFiles/re_train.cox'
else:
filepath='contextFiles/lp_train.cox'
trainX,trainY,testX,testY=getFeaturesAndPolsFromFile(filepath,d_type,per)
clf=trainClassifier(trainX,trainY,classifier)
predict(testX,testY,clf)这里我用的方法就比较水了,SVM,LR套一套用用就完事了。下面是“餐厅”(上图)和“笔记本”(下图)的CV分类效果(使用SVM分类器):
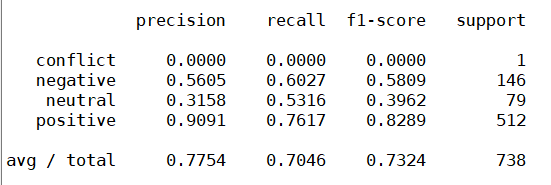
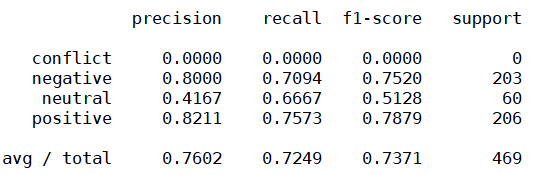
可以看到效果很渣,conflict的Aspect Term太少(基本没有),这里就不提了,中性(neutral)评估的Aspect Term识别效果也很差,这里观察下可发现笔记本的数据集里pos的对象和neg的对象相对均匀一定,实际上如果要用机器学习手段,笔记本数据集上的效果反而看着要跟好一点。但是这个结果真的很差吗?那也不见得,看当年的榜:
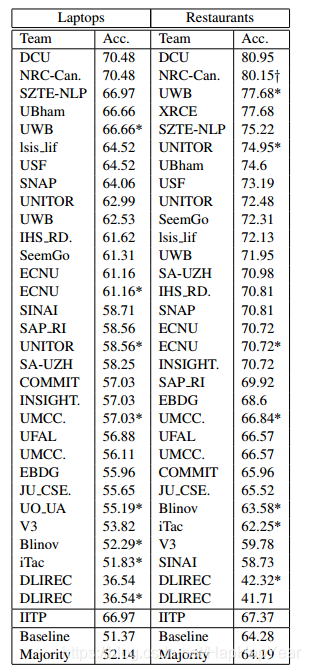
餐厅数据确实比人家差了一大截,但笔记本数据集上好像还挺好?不用在意,上面提过CV和线上是两码事。
那么,为咋任务效果会这么差勒?个人感觉一个主要原因在于当年比赛的数据集实在太少,Aspect Term就那么点点,不太适合机器学习,事实当年该任务的TOP大量使用的是专家数据和外部语料来分析的,这就造成了它们结果十分依赖于外部数据,可能笔记本相关的语料不是那么好找吧,于是造成榜单上两个数据集出现结果两极分化。
但是机器学习方法似乎在两个数据集上,效果差异不会很明显,这也算个优势把,虽然在餐厅数据上,和高度专家经验的方法比,效果实在差太大。
当年课题研究时,用过text-CNN,然后对网络结构做了些魔改,能得到更好的效果,你可以在这些下下功夫继续改善。这里就抛转引玉了,私认为Aspect Term的倾向分析比抽取更难,是个可以深入的坑。
* 题外话,上面榜单可以看到DLIREC队伍很任性啊,抽取拿了第一后直接就弃坑了,甚至提交成绩比不上baseline。-_- !!!
结语
这篇博客是搬砖之余用零零散散的休息时间慢慢磨出来的,代码部分多为之前课题研究时写的,重里面把基础的部分重构了下,虽然后续还想把一些当年写的text-CNN方法,和附加了更多特征的CRF模型分享下,但是想想懒得改了,\ (-_-) / ,后续如果兴致来了再说吧。
总之,吧这破代码重新跑起来的那刻那是蛮多感慨的,希望能帮到那些想入坑NLP的人吧。

















 9353
9353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









