







一.概念
文本情感分析:又称意见挖掘、倾向性分析等,也就是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
细粒度情感分析是一种文本分析技术,旨在对文本中的情感进行更细致和详尽的分类。与传统的情感分析(积极、消极、中性)相比,细粒度情感分析将情感划分为更多的类别,例如喜欢、愤怒、悲伤、惊讶等,以更准确地捕捉文本中的情感细微差别。在分析的粒度上,可以分为文章级(document level)、句子级(sentence level)和单词级(word level)情感分析。其中句子级情感分析在前沿领域有细粒度的情感分析。细粒度的情感分析在完成传统任务情感分类的基础上,还可以确定观点(情感)针对了对象的哪一方面。例如,“这家店的毛衣容易起球,但是店家很快就帮我解决了问题”这句话,通过细粒度的分析可以提取出(质量,-),(服务,+)。
我研究的时候发现,网购的评价会有关键词的提取,还会根据评价的正向分配不同的颜色,例如好评就是红色,差评就是灰色,而不是仅仅通过打星的颗数来判断好评或是差评。这也是细粒度情感分析的一个实际应用。

PDD某商品评价页截图
二.细化
细粒度的情感分析可以进一步细分为三个小任务,分别是对象抽取(aspect extraction),对象级情感分类(aspect-level sentiment analysis)以及通过单个模型完成上述两个任务的方法(协同训练)。
上面链接讲的很清楚,不多赘述
三.具体流程
1. 数据预处理: 首先需要对原始数据进行预处理,包括文本清洗、分词、去除停用词等操作。预处理的目标是将文本转化为适合模型输入的形式。
2. 特征提取: 接下来,从经过预处理的文本中提取特征,用于表示文本内容。常用的特征提取方法包括词袋模型、TF-IDF、word2vec、BERT等。这些方法可以将文本转化为向量表示,能够保留词语的语义和上下文信息。
3. 构建分类模型: 在特征提取完成后,需要选择合适的算法或模型来进行情感分类。常用的分类模型包括朴素贝叶斯、支持向量机(SVM)、逻辑回归、深度学习模型(如卷积神经网络、循环神经网络、Transformer等)。这些模型能够学习从特征到情感类别的映射关系。
4. 训练模型: 使用已标注好的情感分类数据集,将数据集划分为训练集和验证集,使用训练集对分类模型进行训练。训练过程中,模型通过调整内部参数来最小化分类误差或最大化分类准确度。
5. 模型评估和调优: 在训练完成后,需要使用验证集对模型进行评估,计算模型的分类准确率、召回率、F1值等指标,判断模型的性能。如果模型表现不佳,可以进行参数调优、特征选择、模型结构改进等操作,以提高模型性能。
6. 模型应用: 训练好的模型可以用于对新的未标注数据进行情感分类。对于未知的文本数据,可以使用训练好的模型预测其情感类别。
四.代码实现
代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载数据集
data = pd.read_excel(r'C:\Users\123\Desktop\导师任务\2023-12-7-0-4-28-37934748651400-封神第一部:朝歌风云的影评 (7999)-采集的数据-后羿采集器.xlsx')
# 划分训练集和测试集
train_data, test_data, train_labels, test_labels = train_test_split(data['short-content'], data['sentiment'], test_size=0.2, random_state=42)
# 特征提取
vectorizer = CountVectorizer()
train_features = vectorizer.fit_transform(train_data)
test_features = vectorizer.transform(test_data)
# 构建并训练模型
model = LogisticRegression()
model.fit(train_features, train_labels)
# 预测并评估模型
predictions = model.predict(test_features)
accuracy = accuracy_score(test_labels, predictions)
print('准确率:', accuracy)
数据集:数据集是我用后羿采集器采集的豆瓣评论,但是最后准确率不是很高,只有33.333%
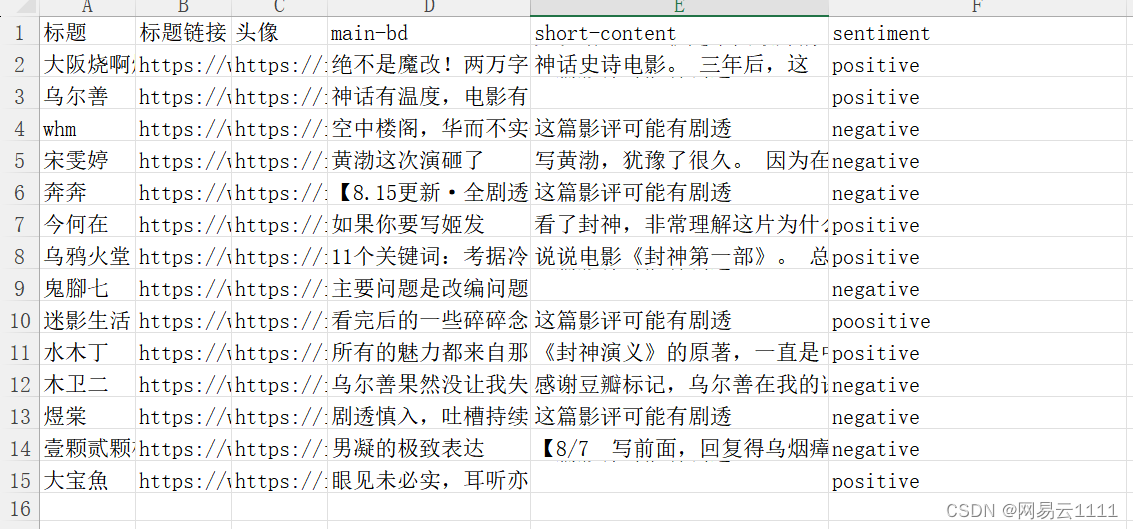
运行结果:
准确率: 0.3333333333333333五.问题
该如何改进让它准确率变高?数据集的sentiment列是我自己手动判断,如果数据量更大可能无法去处理?

















 9269
9269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









