









1 公司某部门大哥 会写一点代码,叫我帮他看看为什么发票中的项目提取不出来
2:我一顿操作,直接重写,并给他写了一个可视化界面,如下所示:
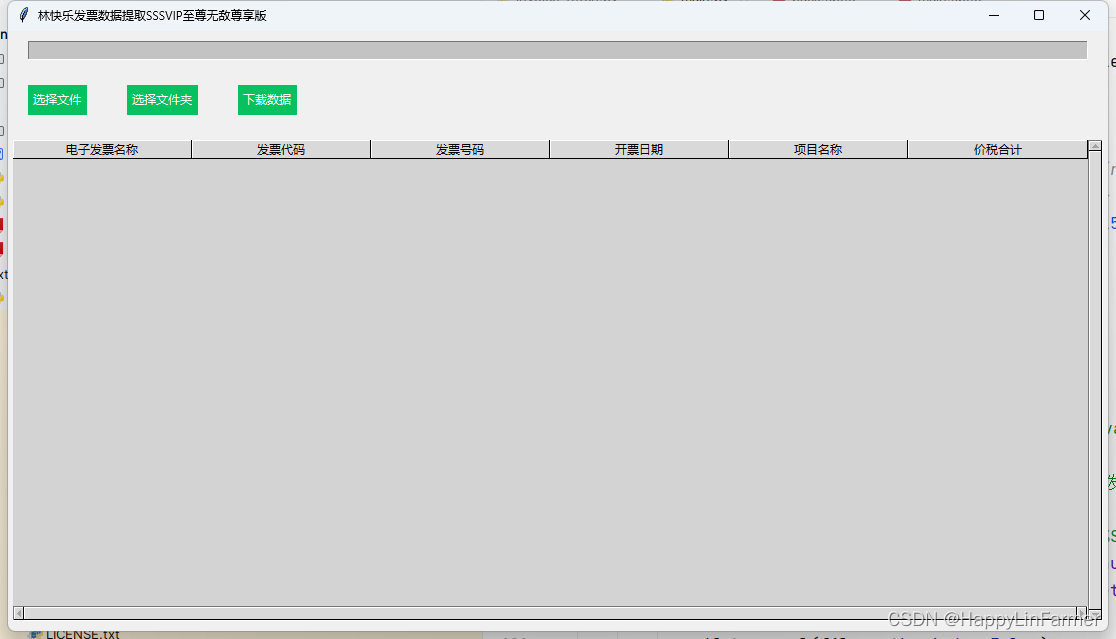
能提取pdf格式的电子普通和专用发票
核心代码请看:
#!/usr/bin/env python
# coding:utf-8
"""
@version: 1.0.0
@author: Happylin
@file: re_fetch.py
@time: 2024/5/15 9:25
"""
import os
import re
import pandas as pd
import pdfplumber
class InvoiceExtract():
def extract_invoice_infos(self, pdf_paths):
"""
从给定的PDF路径列表中提取发票信息。
参数:
- pdf_paths: 包含多个PDF文件路径的列表,这些PDF文件预期为发票。
返回值:
- invoice_infos: 一个列表,包含从每个PDF文件中提取到的发票信息。每个发票信息是通过extract_invoice_info函数提取的。
"""
invoice_infos=[]
for path in pdf_paths:
invoice_info = self.extract_invoice_info(path)
invoice_infos.append(invoice_info)
return invoice_infos
def extract_invoice_info(self, pdf_path):
"""
从PDF文件中提取电子发票信息。
参数:
- pdf_path: string,表示PDF文件的路径。
返回值:
- invoice_info: dict,包含以下键值对:
- "电子发票名称": string,PDF文件的基名。
- "发票代码": string,发票代码(如果存在)。
- "发票号码": string,发票号码(如果存在)。
- "开票日期": string,开票日期(如果存在),格式为"YYYY/MM/DD"。
- "项目名称": string,服务名称,多个名称以分号分隔(如果存在)。
- "价税合计": string,发票金额(如果存在)。
"""
invoice_info = {
"电子发票名称": os.path.basename(pdf_path),
"发票代码": None,
"发票号码": None,
"开票日期": None,
"项目名称": None,
"价税合计": None
}
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
text = page.extract_text()
if not text:
continue
# 提取发票代码
if not invoice_info["发票代码"]:
code_match = re.search(r'发票代码[::]?\s*(\d+)', text)
if code_match:
invoice_info["发票代码"] = code_match.group(1).strip()
# 提取发票号码
if not invoice_info["发票号码"]:
number_match = re.search(r'发票号码[::]?\s*(\d+)', text)
if number_match:
invoice_info["发票号码"] = number_match.group(1).strip()
# 提取开票日期
if not invoice_info["开票日期"]:
# print(text)
# date_match = re.search(r'开票日期[::]?\s*(\d{4}年\d{2}月\d{2}日|\d{4}-\d{2}-\d{2})', text)
date_match = re.findall('开票日期\s*[::]\s*(.*?)\n', text, re.DOTALL)
# print(date_match)
if date_match:
invoice_info["开票日期"] = date_match[0].replace(' ', '').replace('年', '/').replace('月', '/').replace('日','').strip()
# 提取服务名称
if not invoice_info["项目名称"]:
tables = page.extract_tables()
# 确保所有行都检查
service_names = []
for row in tables[0]:
if not row:
continue
# print(row)
# heji_collect=False
for cell in row:
if "货物或应税劳务" in str(cell) or "项目名称" in str(cell):
# print(cell)
# 普票'项目名称 规格型号 单 位 数 量 单 价 金 额 税率/征收率 税 额\n*文具*工位牌 件 15 29.7821782178218 446.73 1% 4.47\n合 计 ¥446.73 ¥4.47'
# 专票 '货物或应税劳务、服务名称\n*经营租赁*经营租赁*车辆停放服务\n合 计'
# 分割普票
for item in cell.split('\n')[1:-1]:
# 专票格式不一样 '*文具*工位牌 件 15 29.7821782178218 446.73 1% 4.47'
# 普票\n分割
zhuanpiao_item = item.split(' ')
if len(zhuanpiao_item) > 1:
for z_item in zhuanpiao_item:
if '*' in z_item:
service_names.append(z_item)
else:
service_names.append(item)
if "小写" in str(cell):
cost=cell.split("¥")[-1].strip()
# print(cost)
invoice_info["价税合计"]=cost
invoice_info["项目名称"] = '\n'.join(service_names)
# 一旦所有信息都提取完毕,就可以停止循环
if all(invoice_info.values()):
break
return invoice_info
def extract_from_directory(directory_path):
data = []
for filename in os.listdir(directory_path):
if filename.endswith(".pdf"):
pdf_path = os.path.join(directory_path, filename)
invoice_info = InvoiceExtract().extract_invoice_info(pdf_path)
if invoice_info:
data.append(invoice_info)
df = pd.DataFrame(data)
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 2000)
print(df)
return data
directory_path = ""
if __name__ == '__main__':
extract_from_directory(directory_path)














 8769
8769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









