







-
什么是哈希?
哈希是一种数据结构,它和数组的相似之处在于可以容纳任意多的值并能按需取用,而它和数组的不同在于索引方式,数组是以数字来索引,哈希则以名字来索引。也就是说,哈希的索引值,此处称为键(key),并不是数字、而是任意唯一的字符串。
键总会被转换为字符串
哈希的值可以是数字、字符串、undef,或是这些类型的组合。
哈希的键则必须全部是唯一的字符串。 -
为何使用哈希?
事实上只要问题中带有"找出重复"、“唯一”、“交叉引用”、"查表"之类的字眼,实现时就很有可能会用到哈希。 -
访问哈希元素
$hash{$some_key}
(1)在挑选哈希名的时候,最好使得哈希名和键之间能放进去一个 “for” 字。
比如"family_name for fred是flintstone",因此把哈希命名为family_name能清晰地反映出键和值之间的关系。
my %family_name;
$family_name{'fred'} = 'flintstone';
$family_name{'barney'} = 'rubble';
foreach my $person (qw< fred barney>){
print "I've heard of $person $family_name{$person}.\n";
}

(2)哈希键可以是任意的表达式:
$foo = 'bar';
print "barney => $family_name{ $foo . 'ney'}";

(3)若对某个已存在的哈希元素赋值,就会覆盖之前的值:
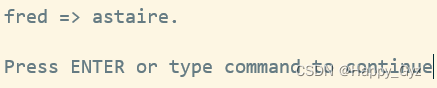
$family_name{'fred'} = 'astaire';
print "fred => $family_name{'fred'}.\n";
(4)哈希元素会因赋值而诞生:
$family_name{'wilma'} = 'flintstone';
$family_name{'betty'} = $family_name{'barney'};
my @family_name = %family_name;
print "@family_name\n";

(5)访问哈希表里不存在的值会得到 undef
- 访问整个哈希
要指代整个哈希,可以用百分号(%)作为前缀。
哈希可以转换为列表,反之亦然。对哈希赋值时,列表中的元素应该为键-值对;展开(unwinding)哈希时,即将哈希变成键-值对列表,得到的键-值对不一定是按照当初赋值时的顺序展开。因此选择使用哈希的场合,要么元素存储顺序无关紧要,要么可以容易地在元素输出时进行排序。当然,即使键-值对的顺序被打乱,列表里的每个键还是会"黏着"相应的值。
my %some_hash;
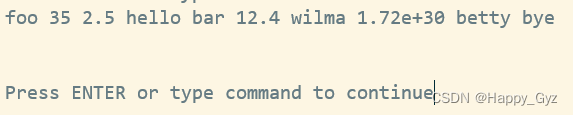
%some_hash = ('foo',35,'bar',12.4,2.5,'hello','wilma',1.72e30,'betty',"bye\n");
my @any_array = %some_hash;
print "@any_array\n";
-
哈希赋值
(1)用一般的赋值语法来复制哈希:my %new_hash = %some_hash;
(2)建立一个反序的哈希:my %inverse_hash = reverse %any_hash;
只能在哈希值不重复的情况下使用,否则就会导致重复的键。 -
胖箭头
对Perl而言,=>是逗号的另一种写法,即在任何需要逗号(,)的地方都可以用胖箭头(=>)代替。
胖箭头左边的任何裸宇(一连串的字母、数字和下划线,但不得以数字开头)都会自动加上引号,因此胖箭头左边的裸字不需要加引号。
另外,在作为哈希键使用时如果花括号内只有裸字时,则两边的引号也可以省略。
my %last_name = (
'fred' => 'flintstone' ,
'dino' => undef ,
'barney' => 'rubble' ,
'betty' => 'rubble', #请注意,列表结尾有一个额外的逗号,这种写法不但无伤大雅,而且便于维护。
);
my %last_name = (
fred => 'flintstone' ,
dino => undef ,
barney => 'rubble' ,
betty => 'rubble',
); #使用胖箭头的时候可以省略键的引号,左边的部分会被自动引起
#当然,也不是所有情况都可以这么做,因为哈希的键可以是任意形式的字符串,
#所以要是某个键的内容含有Perl的操作符,就会偏离我们的预想甚至编译出错
- 哈希函数
keys和values函数
(1)keys 函数能返回哈希的键列表,而values 函数能返回对应的值列表。如果哈希没有任何成员,则两个函数都返回空列表。只要在取得键与取得值这两个动作之间不修改哈希,则返回的键列表和值列表的顺序是一致的。
my @k = keys %some_hash;
my @v = values %some_hash;
(2)在标量上下文中,这两个函数都会返回哈希中元素(键-值对)的个数。
my $count1 = keys %some_hash;
my $count2 = values %some_hash;
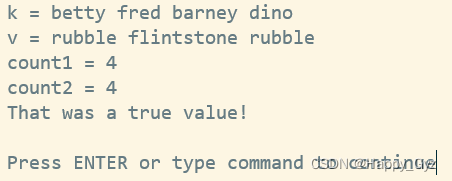
print "k = @k\n" .
"v = @v\n" .
"count1 = $count1\n" .
"count2 = $count2\n";
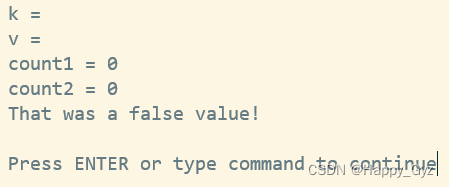
(3)把哈希当成布尔表达式来判断真假(少见):只要哈希中至少有一个键-值对,就返回真
if (%some_hash) {
print "That was a true value! \n" ;
}else{
print "That was a false value! \n" ;
}
each函数(该函数的详细运行过程请看书本 P125 )
(1)实际使用时,唯一适合使用 each 的地方就是在 while 循环中:
while ( ($key,$value) = each %some_hash ){
printf "%10s => %-10s\n",$key,$value;
}
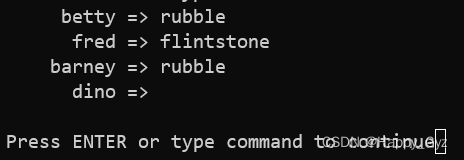
(2)假如你需要依次处理哈希,只要对键排序就行了。方法如下所示:
foreach $key (sort keys %some_hash) {
printf "%10s => %-10s\n",$key,$some_hash{$key};
}
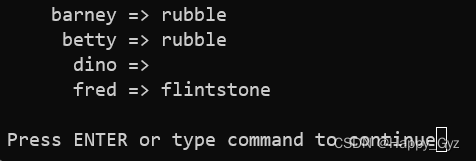
-
哈希的典型应用
-
exists函数
若要检查哈希中是否存在某个键,可以使用exists函数,它能返回真或假,分别表示键存在与否,和键对应的值无关: -
delete函数
delete函数能从哈希中删除指定的键及其相对应的值。假如没有这样的键,它就会直接结束,而不会出现任何警告或错误信息。 -
哈希元素内插
可以将单一哈希元素内插到双引号引起的字符串中,就和你想要的一样:(但这种方式不支持内插整个哈希)
my %some_hash = (
fred => 'flintstone' ,
dino => undef ,
barney => 'rubble' ,
betty => 'rubble',
july => '0',
);
foreach $key (sort keys %some_hash) {
if ($some_hash{$key}) { #两种判断,两种结果,看截图
#if (exists $some_hash{$key}) {
print "$key has $some_hash{$key} items\n";
}
}
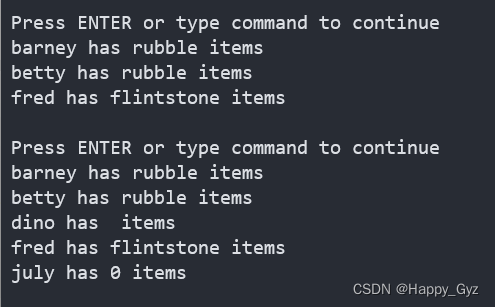
%ENV哈希
访问Perl程序外的任意环境变量
print "PWD is $ENV{PWD}\n";

















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









