






数据结构与算法期末复习总结一
前言
最近期末考试,我整理了这个学期数据结构与算法所学到的代码与知识点,供自己复习,也供大家参考。文中所有代码均使用C++编写。
作者水平有限,若各位发现代码有误或者有可以改进的地方,欢迎在评论区留言告诉我,谢谢!
文中所有代码已经同步上传到我的GitHub上,大家也可以去这里看:
第一章 绪论
一些定义(考选择题)
数据结构:一组具有特定关系的同类数据元素的集合。它包括三个要素数据的逻辑结构 、数据的存储结构及其操作定义与实现。
数据的逻辑结构:集合(无关系)、线性结构(一对一)、树形结构(一对多)、图形结构(多对多)
数据的存储结构:顺序存储(连续的空间)、链式存储(任意位置:可相邻、可不相邻)、索引存储(关键字和地址)、散列存储(关键字和哈希函数算出的存储位置)
数据的操作(运算或算法):算法:正确性、易读性、鲁棒性、高效性
时间复杂度的度量

习题
- 下面程序段的时间复杂度为( C )。
for(int i=0;i<m;i++)
for(int j=0;j<n;j++)
a[i][j]=i*j;
A、O(m2) B、O(n2) C、O(m*n) D、O(m+n)
两层for循环,m和n未知,时间复杂度相乘
- 线性表采用链式存储时,其地址( D ) 。
A、必须是连续的 B、部分地址必须是连续的 C、一定是不连续的 D、连续与否均可以
链式存储时存储的元素连续与否均可以。
顺序存储时存储的元素必须从空间的首位置开始储存,而且必须是连续存放,中间不能有空的空间。
第二章 线性表
基本操作:创建、求长度、查找(按值)、插入、删除、显示。
一、顺序表
元素的物理顺序和逻辑顺序一致。 查插删都是O(n)
·特点:按数据元素的序号随机存取。
·优点:节约存储空间。
·缺点:
插入O(n)和删除O(n)操作耗时。
预先分配最大空间,存储空间浪费。
表的容量难以扩充。
顺序表的基本操作
#include<iostream>
using namespace std;
#define MaxSize 10
struct SeqList
{
int *Data;
int length;
};
//顺序表的初始化
void InitList(SeqList *L){
L=new SeqList;
L->Data=new int[MaxSize];
L->length=0;
}
//顺序表的查找
int Search(SeqList* L,int x){
int i=0;
while(i<=L->length&&L->Data[i]!=x){
i=i+1;
}
if(i>L->length){
i=NULL;
}
return i;
}
//顺序表的插入
void Insert(SeqList* L,int i,int x){
if(L->length==MaxSize){
cout<<"表满"<<endl;
return;
}
if(i<1||i>L->length+1){
cout<<"插入位置不合法"<<endl;
return;
}
for(int j=L->length-1;j>i-1;j--){
L->Data[j+1]=L->Data[j];
}
L->Data[i-1]=x;
L->length++;
}
//顺序表的删除
void Remove(SeqList* L,int i){
if(i<1||i>L->length+1){
cout<<"删除位置不合法"<<endl;
return;
}
for(int j=i;j<L->length-1;j++){
L->Data[j-1]=L->Data[j];
}
L->length--;
}
//顺序表的反转 删除+插入
void Reverse1(SeqList* L){
int n=L->length;
for(int i=1;i<n-1;i++){
int data=L->Data[n-1];
Remove(L,n);
Insert(L,i,data);
}
}
//顺序表的反转 顺序交换
void Reverse2(SeqList* L){
int n=L->length;
for(int i=1;i<n/2;i++){
int j=n-i+1;
int data=L->Data[i-1];
L->Data[i-1]=L->Data[j-1];
L->Data[j-1]=data;
}
}
大整数处理


二、链表
1、单向链表
单向链表:一个数据域和一个指针域
单向链表的基本操作
求表长、查找、插入、删除都是O(n)
#include<iostream>
using namespace std;
// 单向链表
struct ListNode {
int val; //存储数据
ListNode *next; //next指针
ListNode() : val(0), next(NULL) {} //类似构造函数
ListNode(int x) : val(x), next(NULL) {}
};
//求表长
int length(ListNode* head){
int res=0;
ListNode* tmp=head;
while(tmp){
tmp=tmp->next;
res++;
}
return res;
}
//按序号查找
ListNode* Get(ListNode* head,int index){
if(index>length(head)){
return nullptr;
}
ListNode* tmp=head;
for(int i=0;i<index;i++){
tmp=tmp->next;
}
return tmp;
}
//按值查找
ListNode* Search(ListNode* head,int val){
ListNode* tmp=head;
while (tmp->val!=val&&tmp)
{
tmp=tmp->next;
}
return tmp;
}
//插入
ListNode* Insert(ListNode* head,int index,int val){
ListNode* root=head;
for(int i=0;i<index-1;i++){
root=root->next;
}
ListNode* tmp=root->next;
ListNode* newnode=new ListNode(val);
root->next=newnode;
newnode->next=tmp;
return head;
}
//删除 index是从1开始
ListNode* Remove(ListNode* head,int index){
if(index<1||head==nullptr){
return head;
}
if(head->next==nullptr&&index==1){
return nullptr;
}
ListNode* tmp=new ListNode();
tmp->next=head;
ListNode* ptr=tmp;
for(int i=0;i<index-1;i++){
ptr=ptr->next;
}
ptr->next=ptr->next->next;
return tmp->next;
}
查找单链表倒数第k个结点
单指针法(两次遍历)O(n)、双指针法(1次遍历)O(n)
// 单指针法
ListNode* FindkthNodeReverse1(ListNode* head,int k){
ListNode* ptr=head;
int n=0;
while (ptr)
{
n=n+1;
ptr=ptr->next;
}
if(n>=k){
ptr=head;
for(int i=0;i<n-k;i++){
ptr=ptr->next;
}
}
return ptr;
}
//双指针法
ListNode* FindkthNodeReverse2(ListNode* head,int k){
ListNode* ptr1=head;
ListNode* ptr2=nullptr;
for(int j=0;j<k-1;j++){
if(ptr1){
ptr1=ptr1->next;
}
}
if(ptr1!=nullptr){
ptr2=head;
}
while (ptr1->next)
{
ptr1=ptr1->next;
ptr2=ptr2->next;
}
return ptr2;
}
链表的反转
// 头插法 O(n)
ListNode* reverseList2(ListNode* head){
if(head==nullptr || head->next==nullptr){
return head;
}
ListNode* cur=head;
ListNode* newhead=nullptr;
while (cur)
{
//next 保存当前cur所在结点的下一个结点的位置
ListNode* next=cur->next;
cur->next=newhead;//开始头插
newhead=cur;//更新头结点
cur=next;//cur指向下一个待插入的节点
}
return newhead;
}
2、双向链表
一个数据域和两个指针域
struct DoubleListNode{
int val; //存储数据
DoubleListNode *next=nullptr; //next指针指向下一结点
DoubleListNode *pre=nullptr;//pre指针指向上一结点
DoubleListNode() : val(0),next(nullptr),pre(nullptr){}
DoubleListNode(int x):val(x),next(nullptr),pre(nullptr){}
};
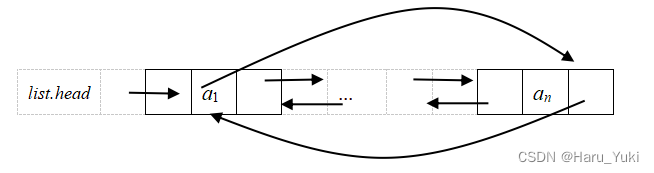
3、循环链表
循环单链表

循环双链表
龟兔赛跑
其实就是判断环,快慢指针即可
总时间:O(n) =O(L+R)
//判断是否有环,如果无环,返回null,如果有环,返回入环节点
ListNode* getLoopNode(ListNode* head){
if(head==nullptr|| head->next==nullptr||head->next->next==nullptr){
return nullptr; //三个节点以上才能形成环
}
ListNode* n1=head->next; //快慢指针
ListNode* n2=head->next->next;
while(n1!=n2){
if(n2->next==nullptr||n2->next->next==nullptr){
return nullptr;
}
n2=n2->next->next;
n1=n1->next;
}
n2=head;
while (n1!=n2) //n2 会到头节点重走一遍,最后n1、n2在入环结点相遇
{
n1=n1->next;
n2=n2->next;
}
return n1;
}
三、习题
1.若某线性表最常用的操作是存取任一指定序号的元素和在表尾进行插入和删除运算,则利用( )存储方式最节省时间。
A.顺序表 B.双向链表 C.带头结点的双向循环链表 D.单循环链表
A 注意顺序表的特性,序号存取。另外在表尾删除,顺序表最后一个元素删除不需要移动元素。
2.某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用( )存储方式最节省运算时间。
A.单链表 B.仅有头指针的单循环链表 C.双链表 D.仅有尾指针的单循环链表
D 链表特点,插入删除方便,修改指针即可。但注意,在最后一个元素插入删除,有顺序表就选顺序表,没有顺序表,选链表就选带尾指针的,因为链表也需要从头结点遍历到尾节点,因此带尾指针的单循环链表最省时间。
请添加图片描述
3.设一个链表最常用的操作是在末尾插入结点和删除尾结点,则选用( )最节省时间。
A. 单链表 B.单循环链表 C. 带尾指针的单循环链表 D. 带头结点的双循环链表
D 链表操作,末尾插入删除,选择带尾指针的单循环链表的话,插入操作得遍历一遍;选择带头结点的双循环链表,前后都能到达,时间复杂度O(1).
4.若某表最常用的操作是在最后一个结点之后插入一个结点或删除最后一个结点。则采用( )存储方式最节省运算时间。
A.单链表 B.双链表 C.单循环链表 D.带头结点的双循环链表
D 最后一个结点后插入删除,跟3类似。
5.在一个有n个结点的有序单链表中插入一个新结点并仍然有序的时间复杂性为( B ) 。
A、O(1) B、O(n) C、O(n2) D、O(log2n)
6.在一个单链表HL中,若要删除由指针q所指向结点的后继结点,则执行( D )。
A、 p=q->next;p->next=q->next; B、 p=q->next;q->next=p;
C、 p=q->next;p->next=q; D、 q->next=q->next->next;















 8786
8786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











