






# Compression and Expansion
## 题面翻译
你有一个数字串,开始为空,每轮你可以进行下面两个操作中的一个:
1. 从末尾删除若干个数字(可以为 $0$ 个)然后把删除后的数字串的最后一个元素加一。
2. 将数字 $1$ 加入到数字串的末端。
现在告诉你你一共进行了 $n$ 次这样的操作,并且告诉你每一次操作完后数字串末尾的数字,让你找到一种可行的方案,并输出每次操作后的数字串。
翻译来自 @$\color{red}\texttt{Macesuted}$
## 题目描述
William is a huge fan of planning ahead. That is why he starts his morning routine by creating a nested list of upcoming errands.
A valid nested list is any list which can be created from a list with one item "1" by applying some operations. Each operation inserts a new item into the list, on a new line, just after one of existing items $ a_1 \,.\, a_2 \,.\, a_3 \,.\, \,\cdots\, \,.\,a_k $ and can be one of two types:
1. Add an item $ a_1 \,.\, a_2 \,.\, a_3 \,.\, \cdots \,.\, a_k \,.\, 1 $ (starting a list of a deeper level), or
2. Add an item $ a_1 \,.\, a_2 \,.\, a_3 \,.\, \cdots \,.\, (a_k + 1) $ (continuing the current level).
Operation can only be applied if the list does not contain two identical items afterwards. And also, if we consider every item as a sequence of numbers, then the sequence of items should always remain increasing in lexicographical order. Examples of valid and invalid lists that are shown in the picture can found in the "Notes" section.When William decided to save a Word document with the list of his errands he accidentally hit a completely different keyboard shortcut from the "Ctrl-S" he wanted to hit. It's not known exactly what shortcut he pressed but after triggering it all items in the list were replaced by a single number: the last number originally written in the item number.
William wants you to help him restore a fitting original nested list.
## 输入格式
Each test contains multiple test cases. The first line contains the number of test cases $ t $ ( $ 1 \le t \le 10 $ ). Description of the test cases follows.
The first line of each test case contains a single integer $ n $ ( $ 1 \le n \le 10^3 $ ), which is the number of lines in the list.
Each of the next $ n $ lines contains a single integer $ a_i $ ( $ 1 \le a_i \le n $ ), which is what remains of William's nested list.
It is guaranteed that in each test case at least one fitting list exists.
It is guaranteed that the sum of values $ n $ across all test cases does not exceed $ 10^3 $ .
## 输出格式
For each test case output $ n $ lines which represent a valid nested list, which could become the data provided to you by William.
If there are multiple answers, print any.
## 样例 #1
### 样例输入 #1
```
2
4
1
1
2
3
9
1
1
1
2
2
1
2
1
2
```
### 样例输出 #1
```
1
1.1
1.2
1.3
1
1.1
1.1.1
1.1.2
1.2
1.2.1
2
2.1
2.2
```
## 提示
In the second example test case one example of a fitting list is:
1
1.1
1.1.1
1.1.2
1.2
1.2.1
2
2.1
2.2
This list can be produced by using the sequence of operations shown below: 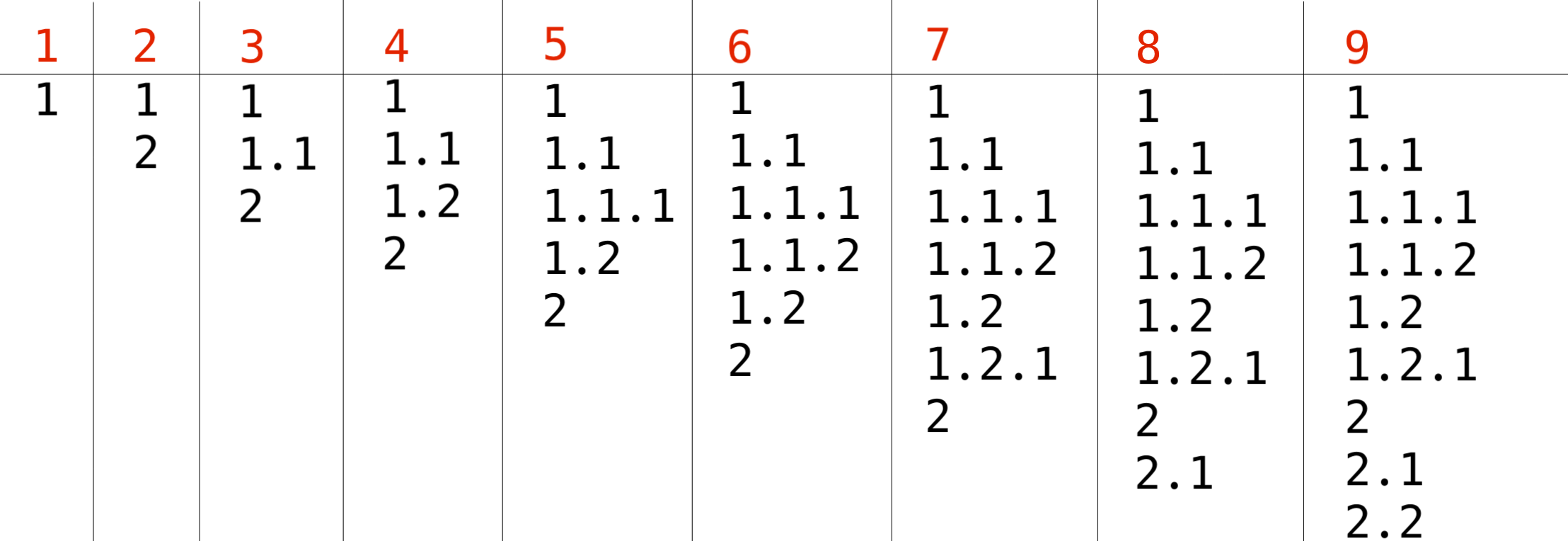
1. Original list with a single item $ 1 $ .
2. Insert item $ 2 $ by using the insertion operation of the second type after item $ 1 $ .
3. Insert item $ 1.1 $ by using the insertion operation of the first type after item $ 1 $ .
4. Insert item $ 1.2 $ by using the insertion operation of the second type after item $ 1.1 $ .
5. Insert item $ 1.1.1 $ by using the insertion operation of the first type after item $ 1.1 $ .
6. Insert item $ 1.1.2 $ by using the insertion operation of the second type after item $ 1.1.1 $ .
7. Insert item $ 1.2.1 $ by using the insertion operation of the first type after item $ 1.2 $ .
8. Insert item $ 2.1 $ by using the insertion operation of the first type after item $ 2 $ .
9. Insert item $ 2.2 $ by using the insertion operation of the second type after item $ 2.1 $ .
因为储存类型搞错在这栽了3个多小时,无语死了.......后面细说
先将思路,这道题核心思想就是对“1”的理解,我们可以把问题简化成这样一个模型,当输入x==1时,在数列的后接上1,这毫无疑问,关键就是删除加一的操作,那么我们可以这么想,只要不是1的数都来自删除若干数加1得来的(若干数包括0),那么从后往前数就数列中一定存在x-1这个数等待被加,然后将这个数之后的全部删除,至于为什么要从后往前数,我们举个例子,1.3.2.2,如果输入3,从后往前数就有1.3.2.3,而从前往后数就有1.3.3,少了一个分支,因此根据题意我们了解到从后往前得到最优解。在存储结构上,一定不要选择字符串类型(我在这迷了好长时间),因为会出现10、11这样的两位数,而串只能一个一个处理,所以最好用vector,这里说一下他的优点:
1.操作方便,vector中提供了pop,方便我们在遍历的同时删除元素,且提供了back和push_back让我们访问修改添加尾部元素,这正是我们需要的。
2.逻辑清晰,在写的时候可以发现相比数组vector要考虑的更少,逻辑结构更加清新。
下面给出代码:
// 蓝桥杯.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <iostream>
#include <algorithm>
#include <cmath>
#include<vector>
#include <string>
using namespace std;
void ssprintf(vector<int> s)//按照格式打印
{
for (int i = 0; i < s.size(); i++)
{
cout << s[i];
if (i != s.size() - 1) cout << ".";
}
cout << endl;
}
void find(vector<int>& s,int x)//从后往前找到x-1的数字,将它后面的数字删除
{
while (s.back() != x - 1 && s.size() ) s.pop_back();
if (s.size() == 0) s.push_back(x);
else s.back()=x;
}
int main()
{
vector<int> s;
int t;
cin >> t;
while (t--)
{
int n;
int x;
cin >> n;
for (int i = 0; i < n; i++)
{
cin >> x;
if (x == 1) s.push_back(1);
else
{
find(s, x);
}
ssprintf(s);
}
s.clear();
}
return 0;
}
顺便说一下,在输出结果我们发现与样例不同,因为题上说了不止一种解。















 174
174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









