






1,Elasticsearch的简介
简称ES,是一个基于Lucene的开源的分布式、RESTful风格的搜索和数据分析引擎。Java语言开发,是一个流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到接近实时搜索,稳定,可靠,快速,安装使用方便。
2,Lucene核心库(内核)
Lucene是当下最先进、高性能、全功能的搜索引擎库(内核)。
Elasticsearch内部采用Lucene做索引与搜索,对Lucene 做了一层封装,它提供了一套简单一致的RESTful API来帮助我们实现存储和检索。
3, ES和solr的对比的区别
Solr利用Zookeeper进行分布式管理,而ES自身就带有分布式协调管理功能。
ES仅支持JSON格式的数据。
ES动态查询非常快,并且稳定。solr动态查询慢,会IO阻塞。
4, Elasticsearch的安装
1,windows安装
1,解压文件到目标文件夹
2,打开bin目录下的elasticsearch.bat,启动程序
3,访问localhost:9200
2,linux安装
1,拉取镜像
docker pull elasticsearch:7.6.2
2,运行docker容器
docker run -d --name es --net=host -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms256m -Xmx256m" elasticsearch:7.6.2
3,开放端口
firewall-cmd --zone=public --add-port=9200/tcp --permanent
firewall-cmd --reload
4,访问192.168.40.128:9200
5,启动,关闭和重启es
docker start es
docker stop es
docker restart es
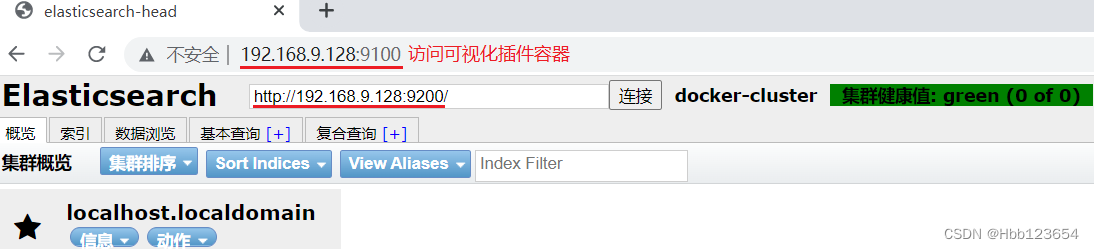
5, Elasticsearch可视化插件安装
1,window安装
在谷歌浏览器中的扩展程序里添加自定义的压缩文件,并启动

处理跨域问题:
打开config文件下的elasticsearch.yml添加
http:cors.enabled: true
http.cors.allow-origin: "*"

即可实现访问linux系统开启的可视化插件容器eshead的服务器
2,linux安装
1,docker镜像安装
docker run --name eshead -p 9100:9100 -d mobz/elasticsearch-head:5
2,开放9100端口
firewall-cmd --zone=public --add-port=9100/tcp --permanent
firewall-cmd --reload
3,处理跨域问题
进入elasticsearch容器:docker exec -it es bash
进入config文件目录:cd /usr/share/elasticsearch/config
修改配置文件elasticsearch.yml:vi elasticsearch.yml
文件尾部添加如下两行内容:a,i,o进入编辑状态,esc退出编辑状态,:wq修改完毕
http:
cors:
allow-origin: "*"
enabled: true
4,重启elasticsearch容器和可视化插件容器eshead
docker restart es
docker restart eshead
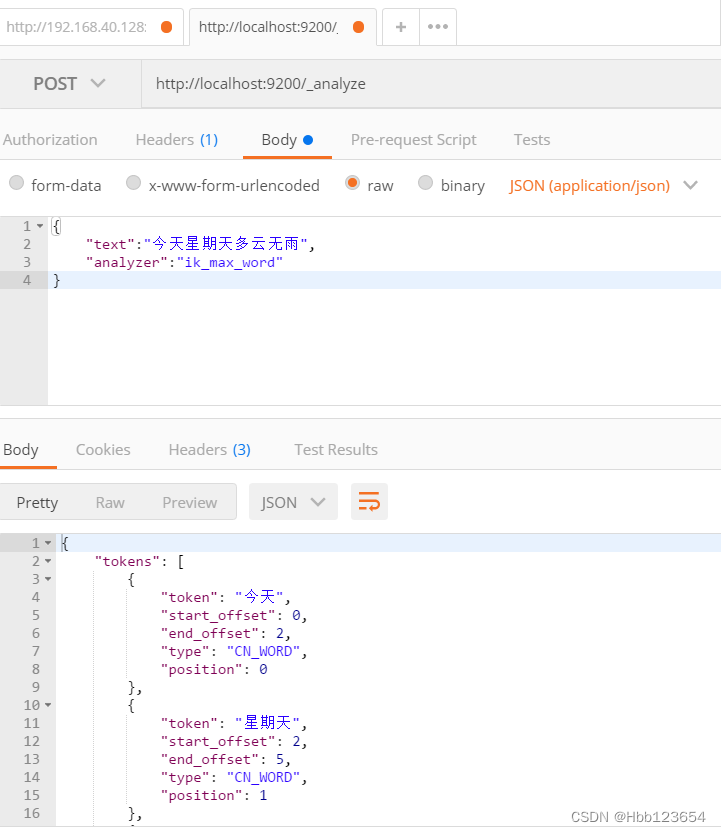
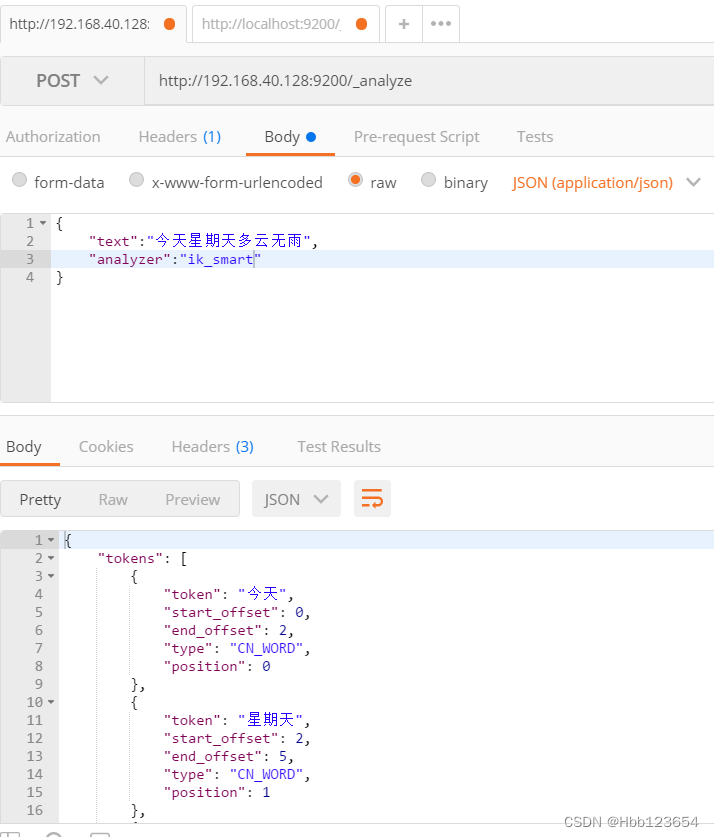
6, ik分词插件安装
ik分词的两种方式:
ik_smart:分词的粒度较小,也叫智能分词。
ik_max_word:分词的粒度较大,也叫最大力度分词。
1,window安装
将相关压缩包解压放在plugins文件夹内,用Postman软件进行测试
2,linux安装
1,在linux系统根目录上创建opt文件夹,上传压缩包到此文件夹
cd /
mkdir opt
2,将zip安装包拷贝到elasticsearch容器的plugins目录:
docker cp /opt/elasticsearch-analysis-ik-7.6.2.zip es:/usr/share/elasticsearch/plugins
3,进入elasticsearch容器:
docker exec -it es bash
4,进入plugins目录:
cd /usr/share/elasticsearch/plugins
5,解压zip安装包并删除zip安装包:
unzip elasticsearch-analysis-ik-7.6.2.zip -d ./ik/
rm -f elasticsearch-analysis-ik-7.6.2.zip
6,重启elasticsearch容器:
docker restart es
7,测试
7,倒排索引
1.将用户输入的文字进行分词,比如得到分词[关键词1,关键词4]
2.对于关键词1,根据倒排索引,命中[商品1,商品2]
3.对于关键词4,根据倒排索引,命中[商品1,商品3]
4.那么符合条件的商品就包括[商品1,商品2,商品3]
5.然后使用正排索引来对它们进行排序。假设定义的匹配度计算公式为目标关键词出现次数的总和(当然真实场景不可能只有匹配度这么一个维度这么简单粗暴,可能要关联数十上百个正排索引,比如匹配度、热度、好评率、给的广告费的多少等等很多指标综合决定)
6.对于商品1,使用正排索引计算得到匹配度为3+1=4
7.对于商品2,使用正排索引计算得到匹配度为1
8.对于商品3,使用正排索引计算得到匹配度为3
9.根据匹配度从高到低,最终搜索的排序结果为:[商品1,商品3,商品2]
8,手写倒排索引
1,引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!--引入结巴分词器的依赖-->
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>2,主程序类
@SpringBootApplication
public class InvertedIndexApplication {
public static void main(String[] args) {
SpringApplication.run(InvertedIndexApplication.class, args);
}
//添加结巴分词器到IOC容器
@Bean
public JiebaSegmenter jiebaSegmenter(){
return new JiebaSegmenter();
}
}3,实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Goods {
private Integer id;//商品id
private String name;//商品名称
private Double price;//商品价格
}4,Dao类
public class GoodsDao {
/*
Map<Integer, Goods>充当数据库,键商品id,值商品对象;
*/
private static Map<Integer, Goods> db = new HashMap<>();
//添加商品的方法
public static void addGoods(Goods goods){
db.put(goods.getId(), goods);
}
//根据id查询商品的方法
public static Goods getGoodsById(Integer id){
return db.get(id);
}
//根据ids查询商品的方法
public static List<Goods> queryGoodsByIds(Set<Integer> ids){
List<Goods> goodsList = new ArrayList<>();
for (Integer id : ids) {
Goods goods = getGoodsById(id);
goodsList.add(goods);
}
return goodsList;
}
}5,倒排索引数据结构
public class InvertedIndexData {
/*
Map<String, Set<Integer>>作为倒排索引数据结构,键是分词,
值是包含该分词的所有商品的id;
*/
public static Map<String, Set<Integer>> index = new HashMap<>();
}6,service类
@Service
public class GoodsService {
//注入结巴分词器
@Autowired
private JiebaSegmenter jiebaSegmenter;
/*
对商品名称进行分词的方法:
参数商品名称,返回值保存了商品名称分词后的所有分词的List;
*/
public List<String> getWords(String name){
/*
调用分词器的process()方法进行分词:
参数一分词的内容 -- 商品名称
参数二分词模式 -- JiebaSegmenter.SegMode.SEARCH检索模式
返回值List<SegToken>中每个SegToken对象就代表一个分词;
*/
List<SegToken> segTokens = jiebaSegmenter.process(name, JiebaSegmenter.SegMode.SEARCH);
List<String> wordList = new ArrayList<>();
for (SegToken segToken : segTokens) {
//拿到每个分词对象SegToken对象表示的分词,添加到List<String>
wordList.add(segToken.word);
}
return wordList;
}
/*
添加商品的业务方法:
1.将商品存入数据库
2.对商品名称进行分词
3.将所有分词以 分词--Set<商品ids> 存入倒排索引中
*/
public void addGoodsService(Goods goods){
//将商品存入数据库
GoodsDao.addGoods(goods);
//对商品名称进行分词
List<String> wordList = getWords(goods.getName());
/*
将所有分词以 分词--Set<商品ids> 存入倒排索引中
*/
//拿到倒排索引
Map<String, Set<Integer>> index = InvertedIndexData.index;
//遍历wordList拿到每个分词
for (String word : wordList) {
//根据当前的分词,先从倒排索引中去拿包含该分词的所有商品的id的Set<Integer>
Set<Integer> ids = index.get(word);
if(ids!=null){//如果Set<Integer>不为null,说明该分词在倒排索引中已存在
//将当前新增的商品的id追加到该分词对应的Set<Integer>
ids.add(goods.getId());
}else{//如果Set<Integer>为null,说明该分词在倒排索引中不存在
//新建个Set<Integer>存入当前新增的商品的id,并将当前分词以 分词--Set<Integer>
//存入倒排索引中
Set<Integer> newIds = new HashSet<>();
newIds.add(goods.getId());
index.put(word, newIds);
}
}
}
/*
根据商品名称查询商品的业务方法:
1.对商品名称进行分词
2.根据分词从倒排索引中拿到包含该分词的所有商品的id
3.根据ids查询出所有商品
*/
public List<Goods> queryGoodsService(String name){
//对商品名称进行分词
List<String> wordList = getWords(name);
/*
根据分词从倒排索引中拿到包含该分词的所有商品的id
*/
Set<Integer> ids = new HashSet<>();
//拿到倒排索引
Map<String, Set<Integer>> index = InvertedIndexData.index;
//遍历wordList拿到每个分词,再从倒排索引中拿到每个分词对应的Set<Integer>,
//最后将所有的商品id保存到Set<Integer> ids中
for (String word : wordList) {
Set<Integer> idSet = index.get(word);
ids.addAll(idSet);
}
//根据ids查询出所有商品
List<Goods> goodsList = GoodsDao.queryGoodsByIds(ids);
return goodsList;
}
}7,测试类
@SpringBootTest
class InvertedIndexApplicationTests {
//注入GoodsService
@Autowired
private GoodsService goodsService;
@Test
void contextLoads() {
//添加几个商品
goodsService.addGoodsService(new Goods(1, "苹果手机11", 6666.6));
goodsService.addGoodsService(new Goods(2, "苹果手机12", 7777.7));
goodsService.addGoodsService(new Goods(3, "苹果手机13", 8888.8));
goodsService.addGoodsService(new Goods(4, "华为手机meta30", 7777.7));
goodsService.addGoodsService(new Goods(5, "华为手机meta40", 9999.9));
/*
搜索手机:
[Goods(id=1, name=苹果手机11, price=6666.6),
Goods(id=2, name=苹果手机12, price=7777.7),
Goods(id=3, name=苹果手机13, price=8888.8),
Goods(id=4, name=华为手机meta30, price=7777.7),
Goods(id=5, name=华为手机meta40, price=9999.9)]
*/
List<Goods> goodsList = goodsService.queryGoodsService("手机");
System.out.println(goodsList);
/*
搜索苹果:
[Goods(id=1, name=苹果手机11, price=6666.6),
Goods(id=2, name=苹果手机12, price=7777.7),
Goods(id=3, name=苹果手机13, price=8888.8)]
*/
goodsList = goodsService.queryGoodsService("苹果");
System.out.println(goodsList);
/*
搜索华为:
[Goods(id=4, name=华为手机meta30, price=7777.7),
Goods(id=5, name=华为手机meta40, price=9999.9)]
*/
goodsList = goodsService.queryGoodsService("华为");
System.out.println(goodsList);
}
}9,Elasticsearch基本使用
Elasticsearch是基于Restful风格的http应用。
Restful风格就是使用http动词形式对url资源进行操作(GET、POST、PUT、DELETE...)。
操作格式为:
请求类型 http://ip:port/索引名/_doc/文档id(行的主键id)
{
请求体
}
1,新建索引
新建一个名称为user的索引(表),有字段(列)name类型text、age类型integer、birthday类型date、price类型double。
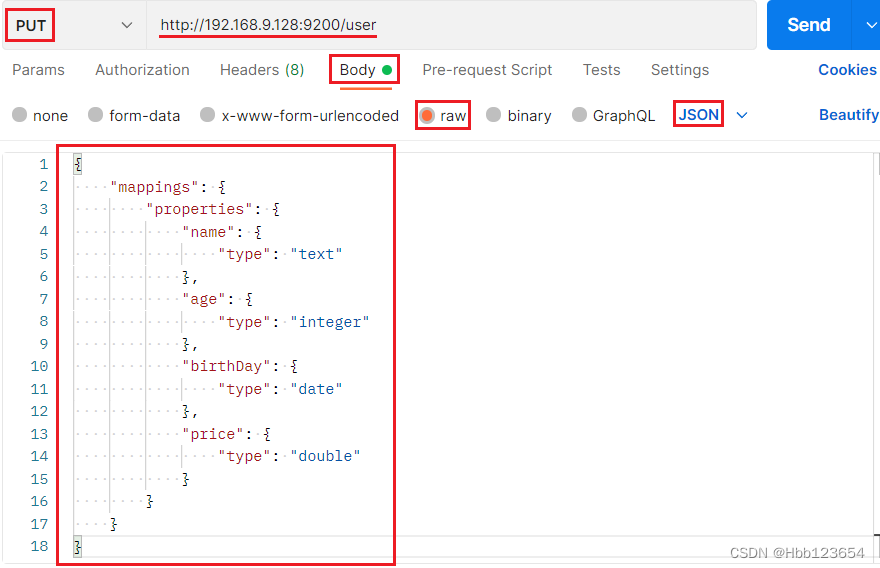
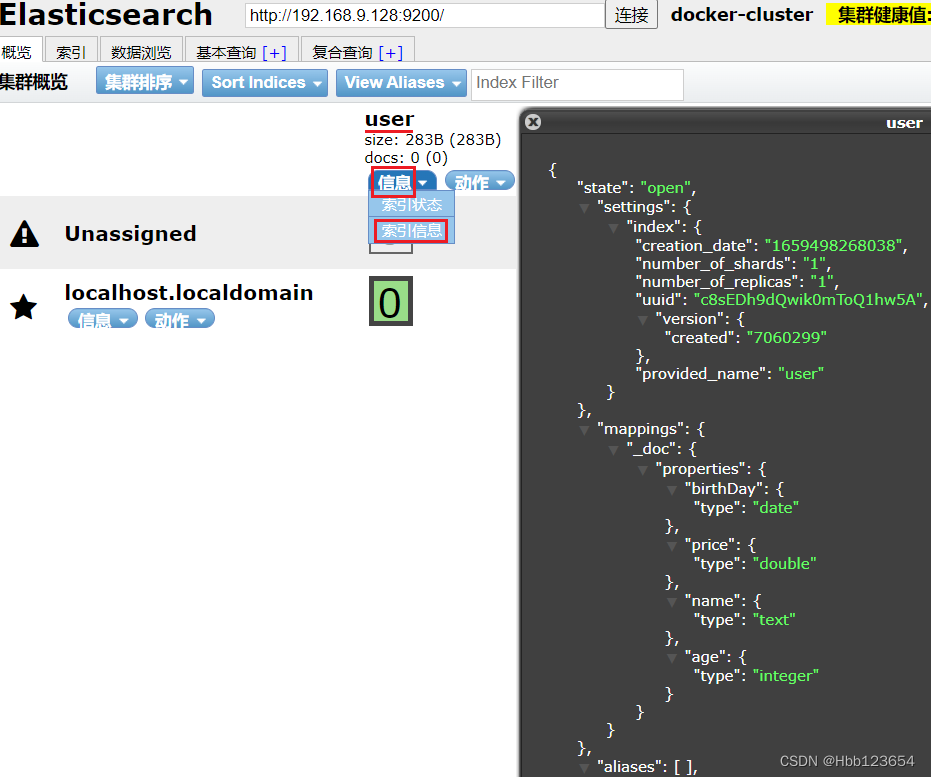
2,删除索引
删除名称为user的索引(表)。索引只能增删,无法修改。

3, 索引中添加数据
向索引中添加数据,即向表中添加行。user索引名称,_doc类型(固定),1文档id(行的主键id)。

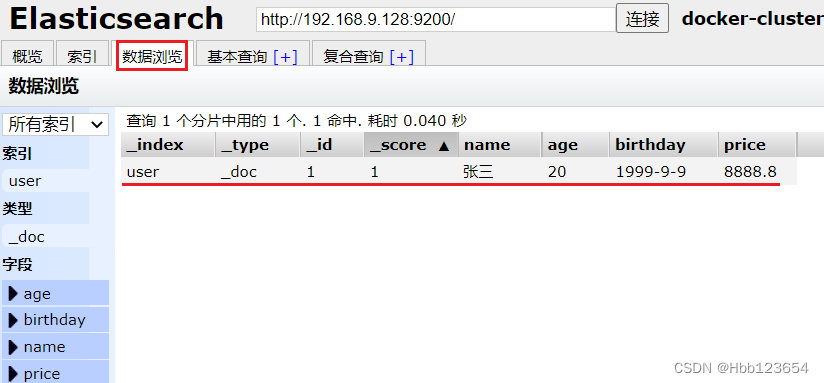 4,删除索引中数据
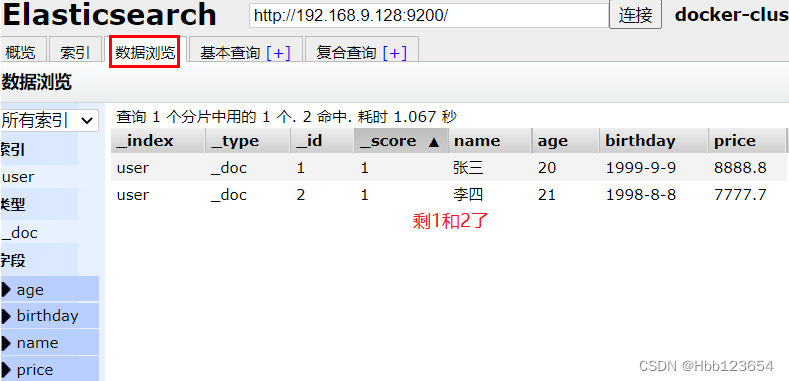
4,删除索引中数据
删除索引(表)user中文档id(主键id)为3的数据(行)。

 5,修改索引中的数据
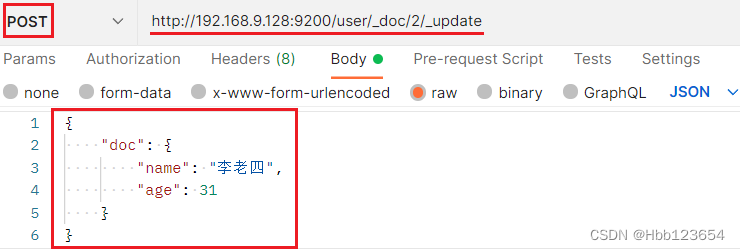
5,修改索引中的数据
对索引(表)user中文档id(主键id)为2的数据(行)进行修改,将name字段值改为李老四、age字段值改为31。注意:如果不加后缀_update,那么没有被修改的字段默认会被删除。
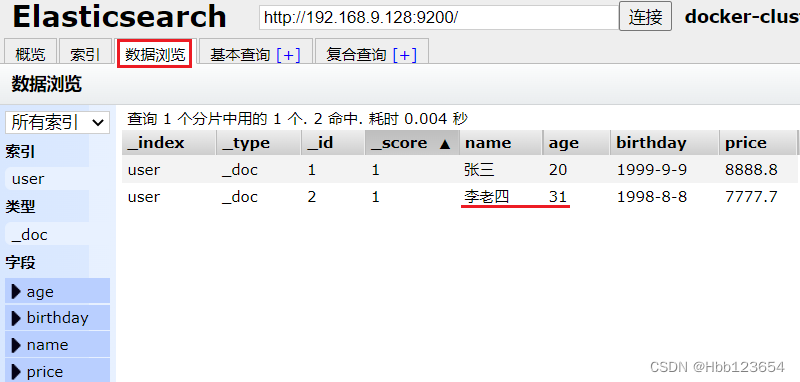
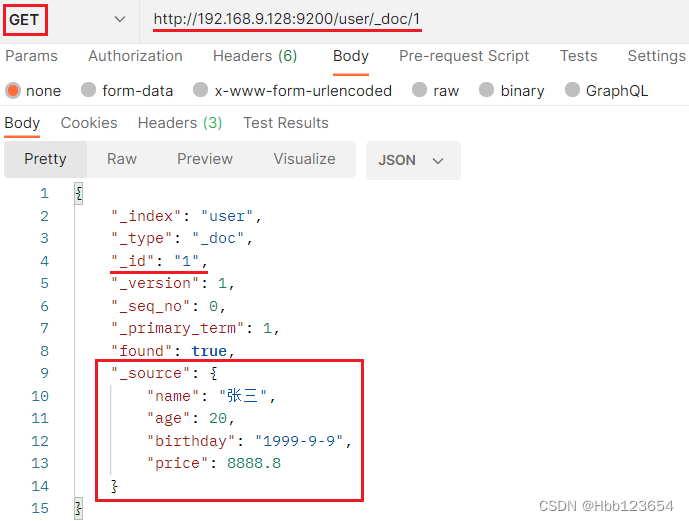
6, 查询索引中一个数据
查询索引(表)user中文档id(主键id)为1的数据(行)。
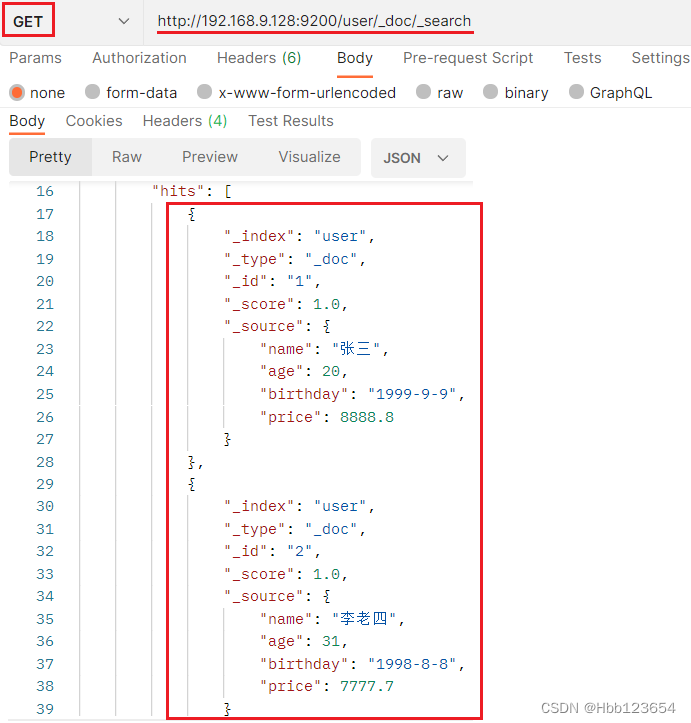
7, 查询索引中全部数据
查询索引(表)user中所有数据(行)。
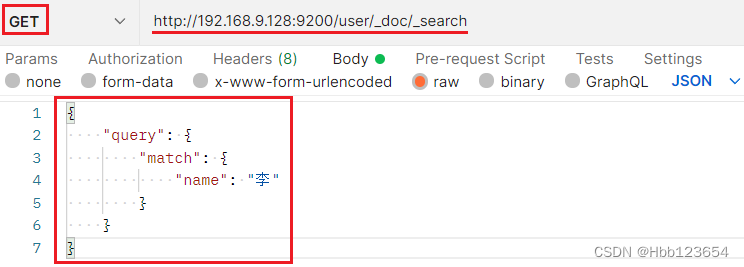
8, DSL查询
ES中的查询叫DSL查询,表现形式就是查询条件是放在发送的请求体里面的。
从索引(表)user中查询name字段包含李的数据(行)。
10, SpringBoot使用ES
1,引入依赖
<!--elasticsearch的依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>2,配置文件
#应用名称
spring.application.name=boot-es
#应用服务WEB访问端口
server.port=8080
#连接ES
spring.elasticsearch.rest.uris=http://192.168.9.128:92003,实体类
/*
Goods类上标注@Document注解,表示依据Goods类来创建索引。
1)indexName属性:索引名;
2)shards属性:分片个数,值为2表示索引存储在两个分片上;
3)replicas属性:每个分片的副本个数,值为1表示每个分片1个副本;
4)refreshInterval属性:刷新数据的时间,默认值就是1秒;
*/
@Document(indexName = "goods_index", shards = 2, replicas = 1, refreshInterval = "1s")
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Goods {
/*
@Field(type = FieldType.Keyword):
表示Goods类的goodsId属性对应索引的goodsId字段;
type=FieldType.Keyword 字段类型为关键字,则不做分词;
@Id:
表示使用Goods类的goodsId属性同时作为索引的文档id(主键id);
*/
@Id
@Field(type = FieldType.Keyword)
private Integer goodsId;//商品id
/*
表示Goods类的goodsName属性对应索引的goodsName字段;
type=FieldType.Text 字段类型为字符串类型;
searchAnalyzer="ik_max_word" 表示goodsName字段被搜索时使用ik_max_word方式分词;
analyzer="ik_max_word" 表示goodsName字段导入时也使用ik_max_word方式分词;
*/
@Field(type = FieldType.Text, searchAnalyzer = "ik_max_word", analyzer = "ik_max_word")
private String goodsName;//商品名称
/*
表示Goods类的goodsDesc属性对应索引的goodsDesc字段;
type=FieldType.Text 字段类型为字符串类型;
searchAnalyzer="ik_max_word" 表示goodsDesc字段被搜索时使用ik_max_word方式分词;
analyzer="ik_max_word" 表示goodsDesc字段导入时也使用ik_max_word方式分词;
*/
@Field(type = FieldType.Text, searchAnalyzer = "ik_max_word", analyzer = "ik_max_word")
private String goodsDesc;//商品描述
/*
表示Goods类的goodsPrice属性对应索引的goodsPrice字段;
type=FieldType.Double 字段类型为Double类型;
*/
@Field(type = FieldType.Double)
private Double goodsPrice;//商品价格
/*
表示Goods类的goodsBrand属性对应索引的goodsBrand字段;
type=FieldType.Text 字段类型为字符串类型;
*/
@Field(type = FieldType.Text)
private String goodsBrand;//商品品牌
/*
表示Goods类的goodsStock属性对应索引的goodsStock字段;
type=FieldType.Long 字段类型为Long类型;
*/
@Field(type = FieldType.Long)
private Long goodsStock;//商品库存
/*
表示Goods类的goodsTags属性对应索引的goodsTags字段;
type=FieldType.Text 字段类型为字符串类型;
*/
@Field(type = FieldType.Text)
private List<String> goodsTags;//商品标签
//默认处理
private Date goodsUpTime;//商品上架时间
}4,Dao接口
/*
继承ElasticsearchRepository接口来定义dao接口,那么在boot应用启动的时候
索引就自动创建了;
*/
@Repository
public interface GoodsDao extends ElasticsearchRepository<Goods, Integer> {
}5,向索引中添加数据
@SpringBootTest
class BootEsApplicationTests {
//注入GoodsDao
@Autowired
private GoodsDao goodsDao;
//向索引中添加数据
@Test
void contextLoads() {
List<Goods> goodsList = new ArrayList<>();
for (int i = 1; i < 101; i++) {
Goods goods = new Goods(
i,
i%2==0 ? "惠普电脑"+i : "联想电脑"+i,
i%2==0 ? "轻薄,办公好,女生喜欢" : "游戏本,性能高,男生喜欢",
i%2==0 ? 6999D+i : 8999D+i,
i%2==0 ? "惠普D"+i : "联想Y"+i,
i%2==0 ? 600L+i : 800L+i,
i%2==0 ? Arrays.asList("上新","延保","双11") :
Arrays.asList("有赠品","秒杀","618"),
new Date());
goodsList.add(goods);
}
goodsDao.saveAll(goodsList);
}
}6,从索引中删除数据
@SpringBootTest
class BootEsApplicationTests {
//注入GoodsDao
@Autowired
private GoodsDao goodsDao;
//根据id删除数据
@Test
void contextLoads2() {
goodsDao.deleteById(1);
}
}7,根据id从索引中查询数据
SpringBootTest
class BootEsApplicationTests {
//注入GoodsDao
@Autowired
private GoodsDao goodsDao;
//根据id查询数据
@Test
void contextLoads3() {
Goods goods = goodsDao.findById(4).get();
System.out.println(goods);
}
}8,查询索引中所有数据
@SpringBootTest
class BootEsApplicationTests {
//注入GoodsDao
@Autowired
private GoodsDao goodsDao;
//查询所有数据
@Test
void contextLoads4() {
Iterable<Goods> allGoods = goodsDao.findAll();
for (Goods goods : allGoods) {
System.out.println(goods);
}
}
}9,修改索引中数据
@SpringBootTest
class BootEsApplicationTests {
//注入GoodsDao
@Autowired
private GoodsDao goodsDao;
//修改数据
@Test
void contextLoads5() {
//没有更新操作,只能是先查、再改、再保存
Goods goods = goodsDao.findById(2).get();
goods.setGoodsName("华硕电脑2");
goodsDao.save(goods);
goods = goodsDao.findById(2).get();
System.out.println(goods);
}
}11,ES复杂查询(DSL查询)
1,相关说明
1,查询条件
match:会通过分词器对查询内容进行分词,然后再通过分词进行查询。
term:不做分词,通过Keyword类型的关键字进行精确查找。(id)
matchPhrase:不做分词,通过指定内容进行精确查找。(包含查询数据)
range:范围查询。例如:查询价格在5000到8000的商品。
match 和 rang 如果同时使用,需要通过bool将二者组合起来查询。
2, 查询常用类
QueryBuilders:
用于构造条件对象,如match条件对象matchQuery、range条件对象rangeQuery、matchPhrase条件对象matchPhrase()、boolQuery等。
NativeSearchQueryBuilder:
用于组装条件(对象),组装后使用build()构建出查询对象NativeSearchQuery。
HighlightBuilder:
用于设置高亮的字段,需使用到它的静态内部类Field。
FunctionScoreQueryBuilder:
用于权重查询,需使用它的静态内部类FilterFunctionBuilder。
2, match分词查询
@SpringBootTest
public class EsTest {
//注入Es模板
@Autowired
private ElasticsearchRestTemplate esTemplate;
/*
搜索联想电脑:
分词查询
*/
@Test
public void testA(){
//构建一个match条件对象--对搜索内容'联想电脑'分词,然后查询名称包含联想和电脑的所有商品
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("goodsName", "联想电脑");
//创建条件组装器NativeSearchQueryBuilder对象
NativeSearchQueryBuilder nativeSearchQueryBuilder =
new NativeSearchQueryBuilder();
//组装match条件
nativeSearchQueryBuilder.withQuery(matchQuery);
//构建出查询对象NativeSearchQuery
NativeSearchQuery nativeSearchQuery = nativeSearchQueryBuilder.build();
//查询
SearchHits<Goods> searchHits = esTemplate.search(nativeSearchQuery, Goods.class);
//提取查询结果
List<SearchHit<Goods>> searchHitList = searchHits.getSearchHits();
for (SearchHit<Goods> searchHit : searchHitList) {
Goods goods = searchHit.getContent();
System.out.println(goods);
}
}
}3,term关键字精确查询
@SpringBootTest
public class EsTest {
//注入Es模板
@Autowired
private ElasticsearchRestTemplate esTemplate;
/*
精确搜索商品id为5的商品
*/
@Test
public void testB(){
//构建一个term条件对象--搜索商品id为5的商品
TermQueryBuilder termQuery = QueryBuilders.termQuery("goodsId", 5);
//创建条件组装器NativeSearchQueryBuilder对象,组装term条件,并构建出
//查询对象NativeSearchQuery
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(termQuery)
.build();
//查询
SearchHits<Goods> searchHits = esTemplate.search(nativeSearchQuery, Goods.class);
//提取查询结果
List<SearchHit<Goods>> searchHitList = searchHits.getSearchHits();
for (SearchHit<Goods> searchHit : searchHitList) {
Goods goods = searchHit.getContent();
System.out.println(goods);
}
}
}4,matchPhrase指定内容精确查询
@SpringBootTest
public class EsTest {
//注入Es模板
@Autowired
private ElasticsearchRestTemplate esTemplate;
/*
精确搜索商品名称包含联想电脑的商品
*/
@Test
public void testC(){
//构建一个matchPhrase条件对象--搜索商品名称包含联想电脑的商品
MatchPhraseQueryBuilder matchPhraseQuery =
QueryBuilders.matchPhraseQuery("goodsName", "联想电脑");
//创建条件组装器NativeSearchQueryBuilder对象,组装matchPhrase条件,并构建出
//查询对象NativeSearchQuery
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(matchPhraseQuery)
.build();
//查询
SearchHits<Goods> searchHits = esTemplate.search(nativeSearchQuery, Goods.class);
//提取查询结果
List<SearchHit<Goods>> searchHitList = searchHits.getSearchHits();
for (SearchHit<Goods> searchHit : searchHitList) {
Goods goods = searchHit.getContent();
System.out.println(goods);
}
}
}5,组合查询
@SpringBootTest
public class EsTest {
//注入Es模板
@Autowired
private ElasticsearchRestTemplate esTemplate;
/*
搜索联想电脑:
分词查询、范围查询、分页、排序
*/
@Test
public void testD(){
//构建一个match条件对象--对搜索内容'联想电脑'分词,然后查询名称包含联想和电脑的所有商品
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("goodsName", "联想电脑");
//构建一个range条件对象--商品价格在7050到9050
RangeQueryBuilder rangeQuery =
QueryBuilders.rangeQuery("goodsPrice").from(7050D).to(9050D);
//构建一个bool将match条件和range条件组合起来
BoolQueryBuilder boolQuery =
QueryBuilders.boolQuery().must(matchQuery).must(rangeQuery);
//创建条件组装器NativeSearchQueryBuilder对象
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
//组装match条件和range条件
nativeSearchQueryBuilder.withQuery(boolQuery);
//组装分页条件--从第一行开始共查询10行
nativeSearchQueryBuilder.withPageable(PageRequest.of(0, 10));
//组装排序条件--按照商品价格goodsPrice字段降序排序
nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort("goodsPrice")
.order(SortOrder.DESC));
//构建出查询对象NativeSearchQuery
NativeSearchQuery nativeSearchQuery = nativeSearchQueryBuilder.build();
//查询
SearchHits<Goods> searchHits = esTemplate.search(nativeSearchQuery, Goods.class);
//提取查询结果
List<SearchHit<Goods>> searchHitList = searchHits.getSearchHits();
for (SearchHit<Goods> searchHit : searchHitList) {
Goods goods = searchHit.getContent();
System.out.println(goods);
}
}
}6,高亮查询
@SpringBootTest
public class EsTest {
//注入Es模板
@Autowired
private ElasticsearchRestTemplate esTemplate;
/*
搜索联想:
分词查询,将商品名称中的联想高亮显示;
*/
@Test
public void testE(){
//构建一个match条件对象--查询名称包含联想的所有商品
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("goodsName", "联想");
//设置高亮的字段--商品名称goodsName中的联想高亮,给其两端加上span标签
HighlightBuilder.Field field = new HighlightBuilder.Field("goodsName");
field.preTags("<span style='color:red;'>");
field.postTags("</span>");
//创建条件组装器NativeSearchQueryBuilder对象
NativeSearchQueryBuilder nativeSearchQueryBuilder =
new NativeSearchQueryBuilder();
//组装match条件
nativeSearchQueryBuilder.withQuery(matchQuery);
//组装高亮
nativeSearchQueryBuilder.withHighlightFields(field);
//构建出查询对象NativeSearchQuery
NativeSearchQuery nativeSearchQuery = nativeSearchQueryBuilder.build();
//查询
SearchHits<Goods> searchHits = esTemplate.search(nativeSearchQuery, Goods.class);
//提取查询结果
List<SearchHit<Goods>> searchHitList = searchHits.getSearchHits();
for (SearchHit<Goods> searchHit : searchHitList) {
Goods goods = searchHit.getContent();
//做了个替换--拿到商品名称中高亮处理的联想替换商品名称中的联想
String HighlightGoodsName = searchHit.getHighlightField("goodsName").get(0);
goods.setGoodsName(HighlightGoodsName);
System.out.println(goods);
}
}
}7,权重查询
@SpringBootTest
public class EsTest {
//注入Es模板
@Autowired
private ElasticsearchRestTemplate esTemplate;
/*
权重查询:
*/
@Test
public void testF(){
//搜索的内容包含商品名称和描述--惠普是惠普电脑的名称的分词,游戏是联想电脑描述的分词
String keyWords = "惠普游戏";
//创建权重数组
FunctionScoreQueryBuilder.FilterFunctionBuilder[] functionBuilders =
new FunctionScoreQueryBuilder.FilterFunctionBuilder[2];
//设置商品名称的权重为5
functionBuilders[0] = (new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.matchQuery("goodsName", keyWords),
ScoreFunctionBuilders.weightFactorFunction(5)
));
//设置商品描述的权重为10
functionBuilders[1] = (
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.matchQuery("goodsDesc", keyWords),
ScoreFunctionBuilders.weightFactorFunction(10)
));
FunctionScoreQueryBuilder functionScoreQueryBuilder =
new FunctionScoreQueryBuilder(functionBuilders);
functionScoreQueryBuilder.setMinScore(2)//设置最小分数
.scoreMode(FunctionScoreQuery.ScoreMode.FIRST);//设置计分方式
//构建出查询对象NativeSearchQuery
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(functionScoreQueryBuilder)
.build();
//查询
SearchHits<Goods> searchHits = esTemplate.search(nativeSearchQuery, Goods.class);
//提取查询结果
List<SearchHit<Goods>> searchHitList = searchHits.getSearchHits();
for (SearchHit<Goods> searchHit : searchHitList) {
Goods goods = searchHit.getContent();
System.out.println(goods);
}
}
}商品名称的权重为5,商品描述的权重为10,所以优先以商品描述去查询商品,优先查询出了联想电脑。
12,Elasticsearch的集群
1,创建三个es节点
2, 修改配置文件
1,Node1的配置文件
#设置集群名称,集群内所有节点的名称必须一致
cluster.name: my-esCluster
#设置节点名称,集群内节点名称必须唯一
node.name: node1
#表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
#当前节点是否用于存储数据,是:true、否:false
node.data: true
#是否锁住物理内存,是:true、否:false
bootstrap.memory_lock: true
#监听地址,0.0.0.0表示谁都可以访问
network.host: 0.0.0.0
#对外暴露的http端口,node1为9200
http.port: 9200
#集群内部通讯端口,node1的为9300
transport.tcp.port: 9300
#告诉当前节点其它有作为master主机资格的节点的个数。默认为1,最优值节点总数/2+1
discovery.zen.minimum_master_nodes: 2
#候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
#节点之间通讯的超时时长
discovery.zen.fd.ping_timeout: 1m
#节点之间通讯失败,再次尝试通讯的次数
discovery.zen.fd.ping_retries: 5
#初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]
#是否支持跨域,是:true
http.cors.enabled: true
#*表示支持所有域名
http.cors.allow-origin: "*"
action.destructive_requires_name: true
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.graph.enabled: false
xpack.watcher.enabled: false
xpack.ml.enabled: false2,Node2的配置文件
#设置集群名称,集群内所有节点的名称必须一致
cluster.name: my-esCluster
#设置节点名称,集群内节点名称必须唯一
node.name: node2
#表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
#当前节点是否用于存储数据,是:true、否:false
node.data: true
#是否锁住物理内存,是:true、否:false
bootstrap.memory_lock: true
#监听地址,0.0.0.0表示谁都可以访问
network.host: 0.0.0.0
#对外暴露的http端口,node1为9201
http.port: 9201
#集群内部通讯端口,node1的为9301
transport.tcp.port: 9301
#告诉当前节点其它有作为master主机资格的节点的个数。默认为1,最优值节点总数/2+1
discovery.zen.minimum_master_nodes: 2
#候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
#节点之间通讯的超时时长
discovery.zen.fd.ping_timeout: 1m
#节点之间通讯失败,再次尝试通讯的次数
discovery.zen.fd.ping_retries: 5
#初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]
#是否支持跨域,是:true
http.cors.enabled: true
#*表示支持所有域名
http.cors.allow-origin: "*"
action.destructive_requires_name: true
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.graph.enabled: false
xpack.watcher.enabled: false
xpack.ml.enabled: false3,Node3的配置文件
#设置集群名称,集群内所有节点的名称必须一致
cluster.name: my-esCluster
#设置节点名称,集群内节点名称必须唯一
node.name: node3
#表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
#当前节点是否用于存储数据,是:true、否:false
node.data: true
#是否锁住物理内存,是:true、否:false
bootstrap.memory_lock: true
#监听地址,0.0.0.0表示谁都可以访问
network.host: 0.0.0.0
#对外暴露的http端口,node1为9202
http.port: 9202
#集群内部通讯端口,node1的为9302
transport.tcp.port: 9302
#告诉当前节点其它有作为master主机资格的节点的个数。默认为1,最优值节点总数/2+1
discovery.zen.minimum_master_nodes: 2
#候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302"]
#节点之间通讯的超时时长
discovery.zen.fd.ping_timeout: 1m
#节点之间通讯失败,再次尝试通讯的次数
discovery.zen.fd.ping_retries: 5
#初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]
#是否支持跨域,是:true
http.cors.enabled: true
#*表示支持所有域名
http.cors.allow-origin: "*"
action.destructive_requires_name: true
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.graph.enabled: false
xpack.watcher.enabled: false
xpack.ml.enabled: false3,启动es
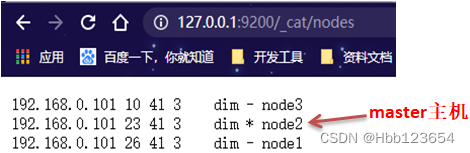
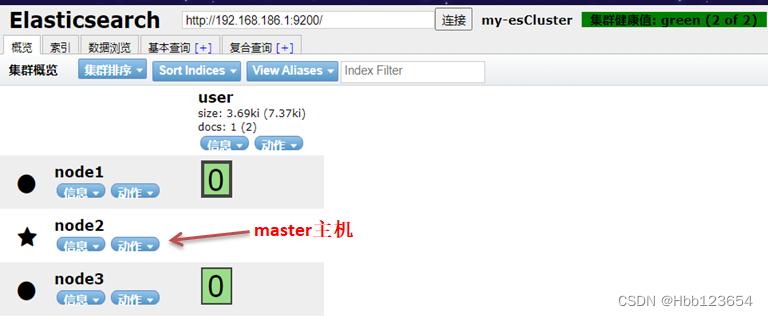
4, 访问查看集群信息和状态
http://127.0.0.1:9200/_cat/nodes
5, SpringBoot连接es集群
spring.elasticsearch.rest.uris=http://127.0.0.1:9200,http://127.0.0.1:9201,http://127.0.0.1:92026,添加数据测试
@SpringBootTest
class BootEsApplicationTests {
//注入GoodsDao
@Autowired
private GoodsDao goodsDao;
//向索引中添加数据
@Test
void contextLoads() {
List<Goods> goodsList = new ArrayList<>();
for (int i = 1; i < 101; i++) {
Goods goods = new Goods(
i,
i%2==0 ? "惠普电脑"+i : "联想电脑"+i,
i%2==0 ? "轻薄,办公好,女生喜欢" : "游戏本,性能高,男生喜欢",
i%2==0 ? 6999D+i : 8999D+i,
i%2==0 ? "惠普D"+i : "联想Y"+i,
i%2==0 ? 600L+i : 800L+i,
i%2==0 ? Arrays.asList("上新","延保","双11") :
Arrays.asList("有赠品","秒杀","618"),
new Date());
goodsList.add(goods);
}
goodsDao.saveAll(goodsList);
}
}读写问题:
master主机负责写,通过路由算法将数据路由保存到从机中去。
















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











