




 本文介绍了DenseCap模型,它整合了目标检测和图像描述,提出Fully Convolutional Localization Network (FCLN)。FCLN由卷积网络、密集定位层和RNN语言模型组成,用于图像中区域的定位和自然语言描述。通过新的定位层,实现了端到端训练和区域级预测,提高了图像理解和描述的准确性。
本文介绍了DenseCap模型,它整合了目标检测和图像描述,提出Fully Convolutional Localization Network (FCLN)。FCLN由卷积网络、密集定位层和RNN语言模型组成,用于图像中区域的定位和自然语言描述。通过新的定位层,实现了端到端训练和区域级预测,提高了图像理解和描述的准确性。
Abstract:文中介绍了密集字幕任务,它包含定位及利用自然语言描述定位物体两个主要任务。为了同时解决物体定位和对其进行描述这两个任务,文中提出Fully Convolutional Localization Network,简称FCLN。它由一个卷积网络,一种新的密集定位层,和一个产生标签序列的RNN语言模型组成。
一. 介绍
在过去的几年中, 图像分类已经取得了很大的进展。进一步的研究工作主要沿着两个完全正交的方向进行,其一是在object detection领域模型的发展,其二是在image captioning领域标签复杂度的提升(从固定的分类描述到能表达更丰富内容的序列文字)。
本文将上面提到的两个方向进行了结合从而得到一个统一的框架。文章先介绍dense captioning task,
它要求模型能够描述图片中一系列区域(也就是说不止单个object)
。在这种情况下单一的object detection和image captioning只能被视为其中较为特别的例子。(见Figure1)。
其次,文章的主要贡献在于介绍了一种新的
密集定位层( dense localization layer)
,它完全可微并且可以将其单独插入其他任何图像处理的网络中来达到区域水平的训练和预测。实际上这个定位层预测了图片中的一系列感兴趣的区域(ROI)并使用了双线性插值来较为平滑得提取区域中的激活值。
二. 相关研究工作
Object Detection:介绍了从R-CNN到RPN网络(对anchor box到感兴趣的region做了回归)的发展和不同点,
本文中并没有训练这个途径( training pipeline),并且将ROI pooling 机制替换成了可微的, spatial soft attention机制。
这一改变使得我们可以在RPN网络中使用BP算法,并且对整个网络进行联合训练。
Image Captioning:最早图片描述技术到RNN的变迁。最新则使用soft attention mechanism。
三. 模型
模型结构纵览:(支持单步优化的端对端训练,以及对图片高效和实际的的描述)
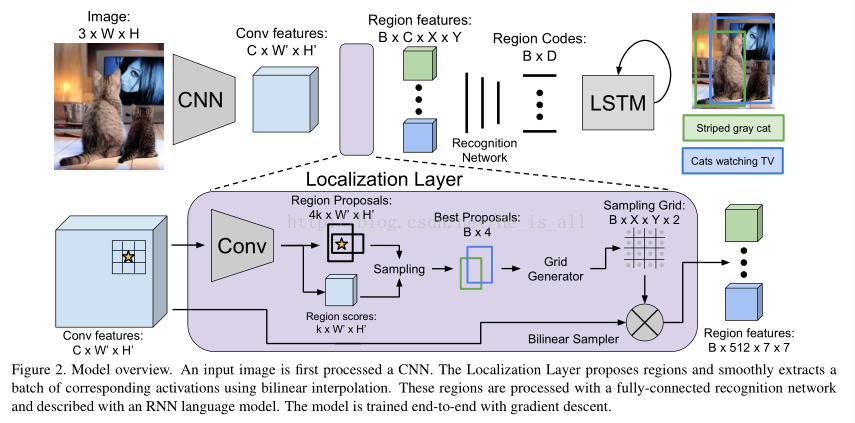
3.1. 模型结构
3.1.1 Convolutional Network
文中使用VGG-16结构。它由13个3×3卷积层和嵌入其中的5个2×2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5101
5101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









