







 本文深入解析DenseCap模型,该模型结合了Image Caption与Faster R-CNN,实现密集字幕生成。通过Localisation Layer的双线性插值方法处理不同大小的提案,使得误差可反向传播,优化特征映射。DenseCap能从图像中生成多个目标的描述,推进了图像理解和自然语言处理的融合。
本文深入解析DenseCap模型,该模型结合了Image Caption与Faster R-CNN,实现密集字幕生成。通过Localisation Layer的双线性插值方法处理不同大小的提案,使得误差可反向传播,优化特征映射。DenseCap能从图像中生成多个目标的描述,推进了图像理解和自然语言处理的融合。
先来看看denesecap的效果,
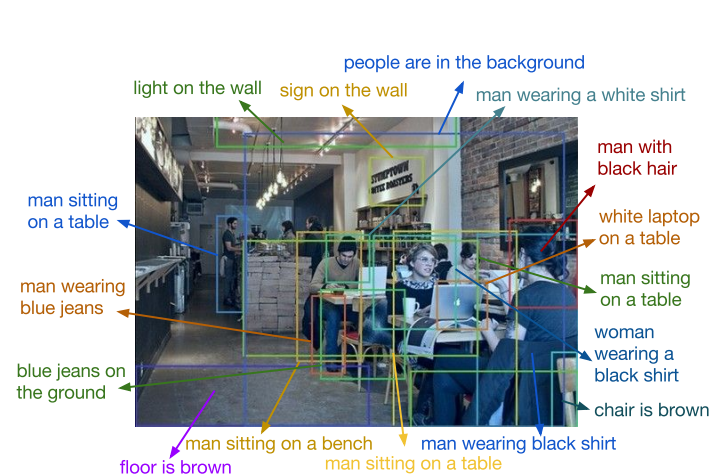
对比之前的Image Caption

由单目标变成了多目标。
就好比之前的Image Classfication 发展到 Object Detection
其实Image Caption发展到densecap本质上也是借鉴了Faster RCNN进行Object Detection的手法。在一个前向运算中就完成了 Proposal 和 Caption的工作。
来看下Image Caption的结构
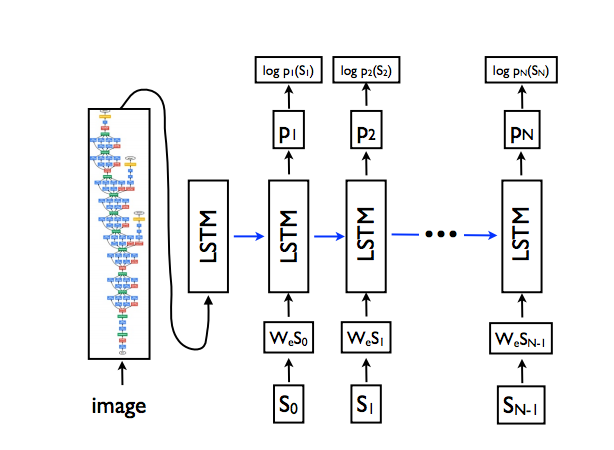
本质上是将Image经过卷积后得到的向量作为LSTM的输入,最后得到一个词的序列。
Faster-RCNN的结构可参考我的博客
http://blog.csdn.net/sunyiyou9/article/details/52434541,较为详细的介绍了Faster RCNN中的关键部分RPN网络的工作机理。
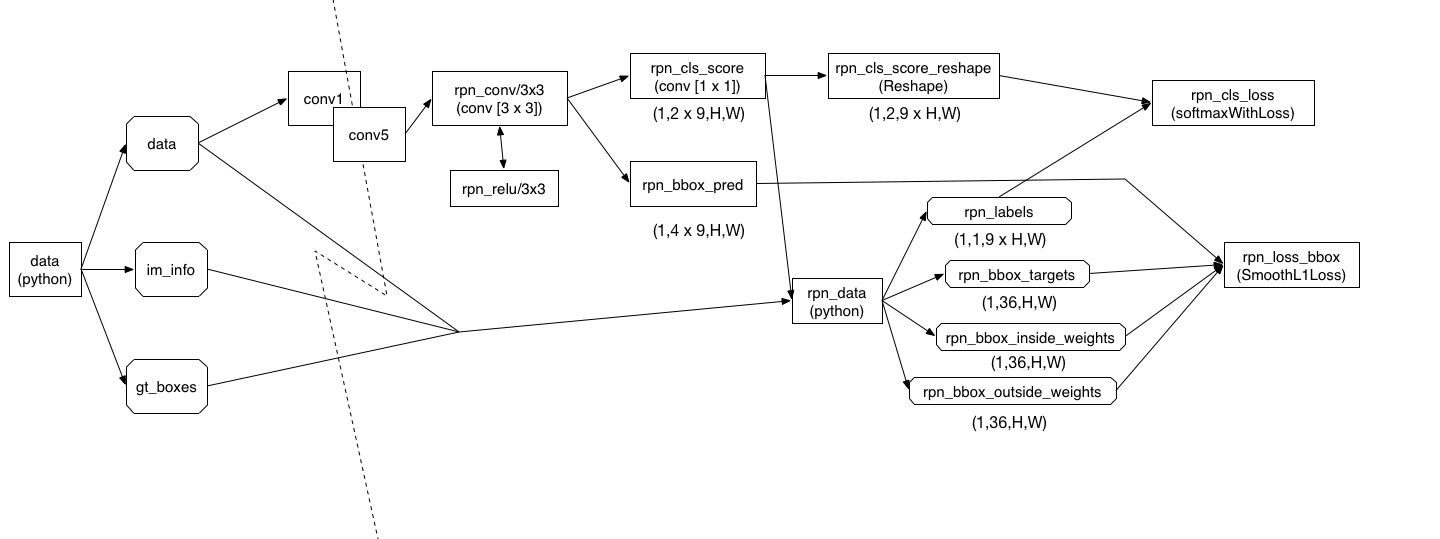
而RPN网络便是将单目标任务变成多目标任务的大杀器。
Image Caption + Faster RCNN = densecap
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









