









设样本均值为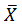
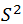
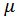
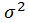
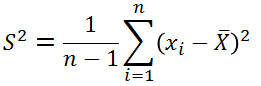
很多人可能都会有疑问,为什么要除以n-1,而不是n,但是翻阅资料,发现很多都是交代到,如果除以n,对样本方差的估计不是无偏估计,比总体方差要小,要想是无偏估计就要调小分母,所以除以n-1,那么问题来了,为什么不是除以n-2、n-3等等。所以在这里彻底总结一下,首先交代一下无偏估计。
无偏估计
以例子来说明,假如你想知道一所大学里学生的平均身高是多少,一个大学好几万人,全部统计有点不现实,但是你可以先随机挑选100个人,统计他们的身高,然后计算出他们的平均值,记为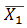
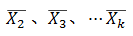
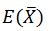
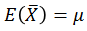
介绍无偏估计的意义就是,我们计算的样本方差,希望它是总体方差的一个无偏估计,那么假如我们的样本方差是如下形式:
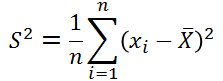
那么,我们根据无偏估计的定义可得:

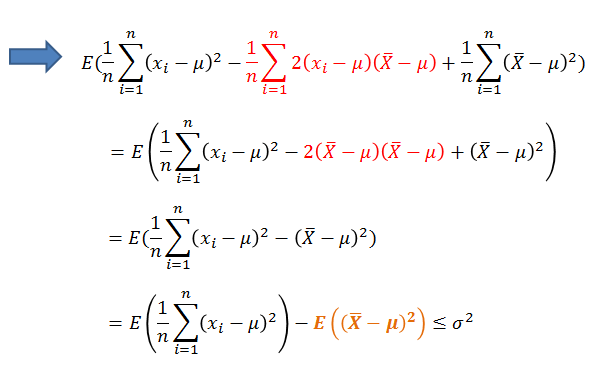
由上式可以看出如果除以n,那么样本方差比总体方差的值偏小,那么该怎么修正,使得样本方差式总体方差的无偏估计呢?我们接着上式继续化简:
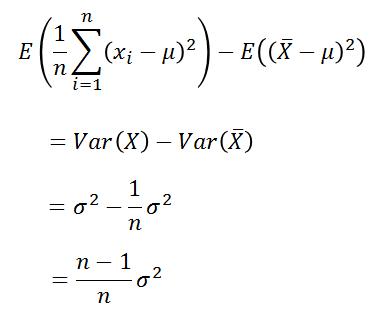
到这里得到如下式子,看到了什么?该怎修正似乎有点眉目。
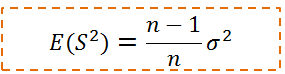
如果让我们假设的样本方差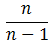
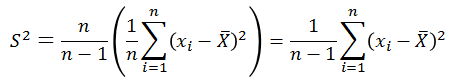
则:
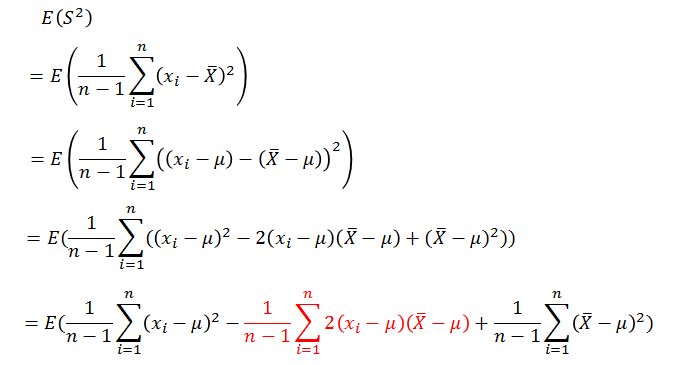
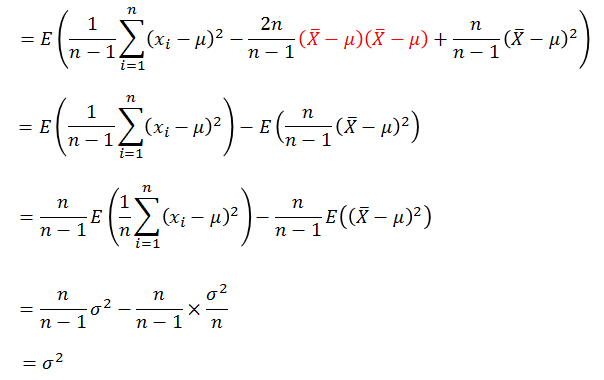
因此修正之后的样本方差的期望是总体方差

















 5364
5364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









