









 本文深入探讨PostgreSQL中的Vacuum机制,包括其作用原理、执行阶段、自动Vacuum配置及统计信息收集方法。此外,还提供了如何有效管理和优化Vacuum过程的实用建议。
本文深入探讨PostgreSQL中的Vacuum机制,包括其作用原理、执行阶段、自动Vacuum配置及统计信息收集方法。此外,还提供了如何有效管理和优化Vacuum过程的实用建议。
一、 作用与原理
page pruning执行速度很快,但它们的作用范围毕竟只有单页、且不包含索引,因此,我们还需要更有效的清理机制。
常规vacuum是最常用的一种,作用范围可以是整张表,清理过期元组及索引项,并且不阻塞读和写。为提高效率,vacuum会结合前面提到的.vm文件,跳过不需清理的页。清理之后,还会更新前面提到的fsm(空闲空间映射)文件。
另外还可以用vacuum analyze顺便收集统计信息。
二、 vacuum案例
CREATE TABLE vac(id integer,s char(100)) WITH (autovacuum_enabled = off);
CREATE INDEX vac_s ON vac(s);
INSERT INTO vac(id,s) VALUES (1,'A');
UPDATE vac SET s = 'B';
UPDATE vac SET s = 'C';
SELECT * FROM heap_page('vac',0);
SELECT * FROM index_page('vac_s',1);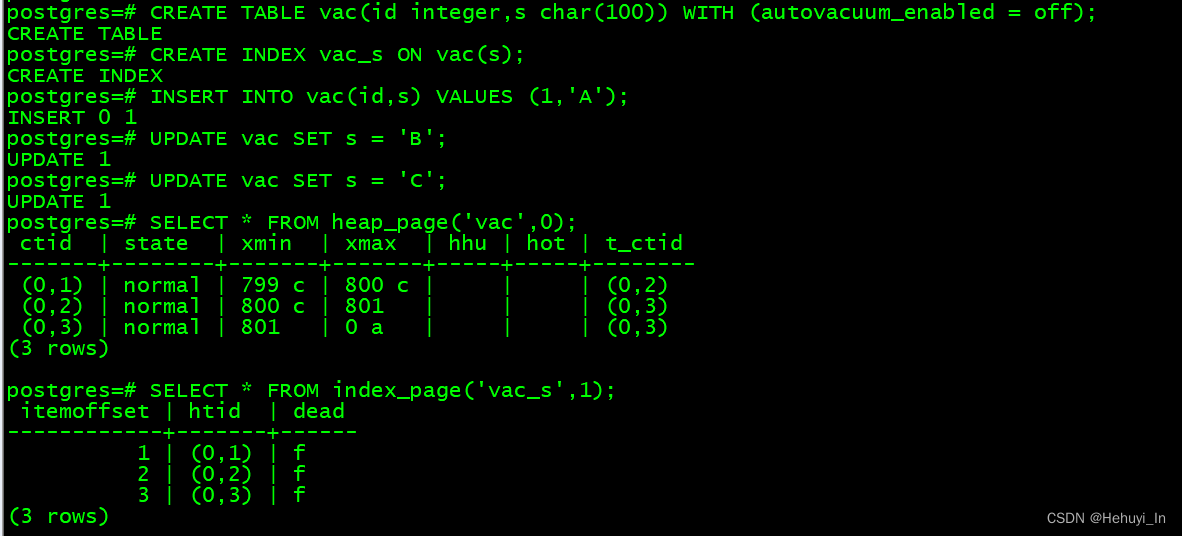
Vacuum基于database horizon检查和清理表和索引中的死元组,尚未过期的元组不能清理。
VACUUM vac;
SELECT * FROM heap_page('vac',0);
SELECT * FROM index_page('vac_s',1);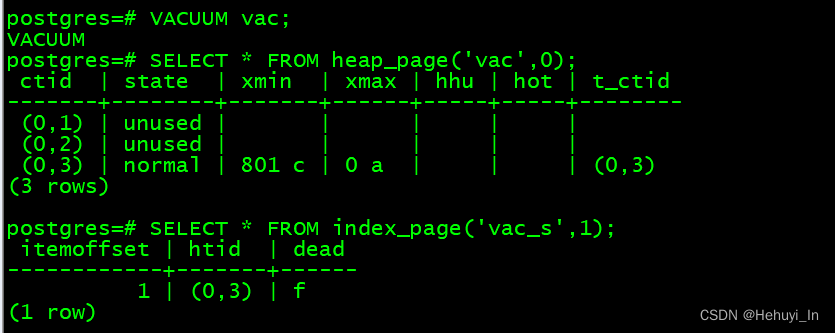
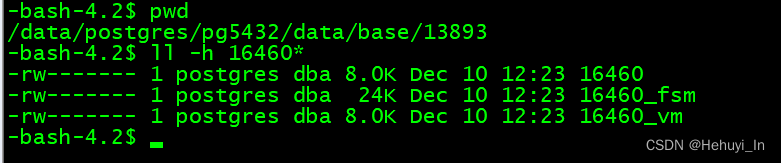
Vacuum之后pg会为vac表创建vm和fsm文件

安装插件可以看到某页中的元组是否均可见
CREATE EXTENSION if not exists pg_visibility;
SELECT all_visible FROM pg_visibility_map('vac',0);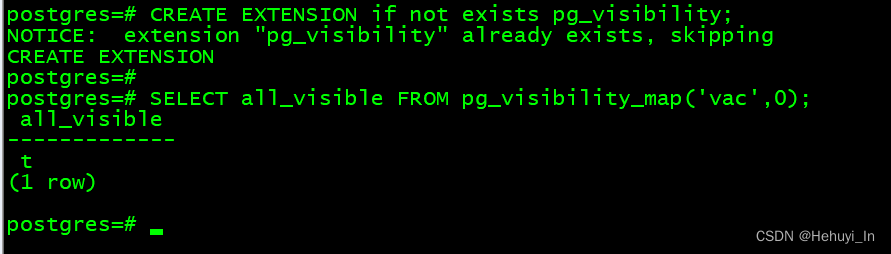
如果不想安装,从页头信息也可以看到
SELECT flags & 4 > 0 AS all_visible FROM page_header(get_raw_page('vac',0));
三、 vacuum阶段
1. 查看vacuum详情
postgres=# VACUUM VERBOSE vac;
INFO: vacuuming "public.vac"
INFO: scanned index "vac_s" to remove 1 row versions
DETAIL: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
INFO: table "vac": removed 1 dead item identifiers in 1 pages
DETAIL: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s
INFO: index "vac_s" now contains 2 row versions in 2 pages
DETAIL: 1 index row versions were removed.
0 index pages were newly deleted.
0 index pages are currently deleted, of which 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: table "vac": found 1 removable, 2 nonremovable row versions in 1 out of 1 pages
DETAIL: 1 dead row versions cannot be removed yet, oldest xmin: 808
Skipped 0 pages due to buffer pins, 0 frozen pages.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
VACUUM
它列出了扫描的表和索引、cpu及耗时、删除了多少项、不能删除的有多少项、database horizon(红色部分)、跳过多少项、冻结多少个页,非常详细,根据它也可以大致推断vacuum的执行阶段。
查看vacuum进度
SELECT * FROM pg_stat_progress_vacuum \gx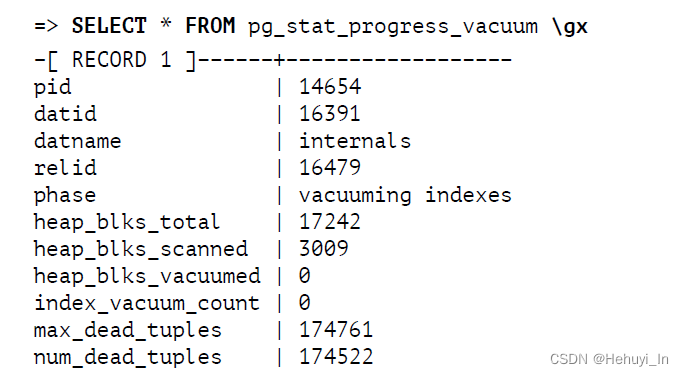
2. 主要阶段
1)表扫描
- 读取vm文件,跳过其中页面
- 根据database horizon扫描死元组,并将还需要被索引引用的元组id加入一个特殊的tid数组,这些元组暂时不能清理
- 这部分可用内存取决于maintenance_work_mem
2)索引vacuum
- 表上的所有索引被完整扫描,找到引用tid数组中元组的对应索引项
- 从索引页中删除这些索引项
- 如果索引大小超过min_parallel_index_scan_size,将会启用并行
- 更新fsm文件并收集统计信息
- 如果只对表进行过insert,会直接跳过本阶段
3)表vacuum
- 删除tid数组中的元组及对应指针(此时所有索引引用已被删除)
- 更新fsm和vm文件
- 清理tid数组
4)表截断(heap truncation)
- 特殊场景:如果清空的页刚好在文件末尾,vacuum可以将这些空间归还给操作系统
- heap truncation会短暂持有排它锁
- 由于排它锁会影响业务,pg只在文件末尾有至少1000个页,或者达到表大小的1/16时,才执行截断。这两个参数是硬编码,不能修改。
- 如果确实怕被排它锁影响业务,可以在表级设置vacuum_truncate和toast.vacuum_truncate参数,禁用该功能:ALTER TABLE some_table SET (vacuum_truncate = off);
四、 自动vacuum与统计信息收集
1. autovacuum简介
对应进程:autovacuum launcher,需要启用autovacuum才会有这个进程。

主要参数:
- autovacuum:是否启用该功能
- autovacuum_naptime:进程运行间隔。假如有N个db,则会在间隔内启动n个对应worker
- autovacuum_max_workers:autovacuum 最大worker数,假如超过那么多个db,则后面的要等待
- autovacuum_work_mem:用于autovacuum的内存大小,默认是-1,即与maintenance_work_mem一致。如果max_workers设的比较大,可能需要加大该内存参数
表级参数:
- autovacuum_enabled 和 toast.autovacuum_enabled:针对表启/禁用autovacuum
autovacuum worker启动后会创建两个list:
- 需要vacuum的所有表、物化视图、toast表
- 需要analyze的所有表、物化视图(toast表不需要收集统计信息)
- 然后逐一对这些对象进行vacuum和analyze
- 不同表之间可以并发autovacuum,相同表不能并行执行autovacuum
2. 什么样的表需要vacuum
1)死元组堆积
- autovacuum_vacuum_threshold:表中死元组数阈值,默认为50
- autovacuum_vacuum_scale_factor:死元组在表中占比,默认为0.2
计算公式:pg_stat_all_tables.n_dead_tup > autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor × pg_class.reltuples
其实就是死元组在表中占比(考虑大表)+一个数量值(考虑小表)
这两个参数针对普通表和toast表均有对应表级同名参数,可以针对各表调整。
2)行插入(pg 13引入以下参数)
如果只有插入和没有更新删除,表中则不会包含死元组,但这些表也需要执行vacuum以冻结元组,并更新.vm文件。它的参数和计算公式跟上面非常类似:
- autovacuum_vacuum_insert_threshold:表插入行数阈值,默认为1000
- autovacuum_vacuum_insert_scale_factor:表插入行数占比,默认为0.2
计算公式:pg_stat_all_tables.n_ins_since_vacuum(自上次vacuum以来插入的行数) > autovacuum_vacuum_insert_threshold + autovacuum_vacuum_insert_scale_factor × pg_class.reltuples
同样它也有对应表级同名参数,可以针对各表调整。
3. 什么样的表需要analyze
Automatic analysis只考虑被修改的行数,因此它更简单一些,参数和计算公式还是类似:
- autovacuum_analyze_threshold:表被修改行数阈值,默认50
- autovacuum_analyze_scale_factor:表被修改行数比例,默认0.1
计算公式:pg_stat_all_tables.n_mod_since_analyze (自上次analyze以来被修改的行数)> autovacuum_analyze_threshold + autovacuum_analyze_scale_factor × pg_class.reltuples
它也有对应普通表的表级同名参数,可以针对各表调整。toast表无需收集统计信息,因此没有针对它的参数。
4. 查看方法
当前哪些表需要vacuum,哪些需要analyze,我们可以创建两个函数查看
CREATE FUNCTION p(param text, c pg_class) RETURNS float
AS $$
SELECT coalesce(
-- use storage parameter if set
(SELECT option_value
FROM pg_options_to_table(c.reloptions)
WHERE option_name = CASE
-- for TOAST tables the parameter name is different
WHEN c.relkind = 't' THEN 'toast.' ELSE ''
END || param
),
-- else take the configuration parameter value
current_setting(param)
)::float;
$$ LANGUAGE sql;need_vacuum函数
CREATE VIEW need_vacuum AS
WITH c AS (
SELECT c.oid,
greatest(c.reltuples, 0) reltuples,
p('autovacuum_vacuum_threshold', c) threshold,
p('autovacuum_vacuum_scale_factor', c) scale_factor,
p('autovacuum_vacuum_insert_threshold', c) ins_threshold,
p('autovacuum_vacuum_insert_scale_factor', c) ins_scale_factor
FROM pg_class c
WHERE c.relkind IN ('r','m','t')
)
SELECT st.schemaname || '.' || st.relname AS tablename,
st.n_dead_tup AS dead_tup,
c.threshold + c.scale_factor * c.reltuples AS max_dead_tup,
st.n_ins_since_vacuum AS ins_tup,
c.ins_threshold + c.ins_scale_factor * c.reltuples AS max_ins_tup,
st.last_autovacuum
FROM pg_stat_all_tables st
JOIN c ON c.oid = st.relid;need_analyze函数
CREATE VIEW need_analyze AS
WITH c AS (
SELECT c.oid,
greatest(c.reltuples, 0) reltuples,
p('autovacuum_analyze_threshold', c) threshold,
p('autovacuum_analyze_scale_factor', c) scale_factor
FROM pg_class c
WHERE c.relkind IN ('r','m')
)
SELECT st.schemaname || '.' || st.relname AS tablename,
st.n_mod_since_analyze AS mod_tup,
c.threshold + c.scale_factor * c.reltuples AS max_mod_tup,
st.last_autoanalyze
FROM pg_stat_all_tables st
JOIN c ON c.oid = st.relid;改小阈值进行试验(默认1分钟)
ALTER SYSTEM SET autovacuum_naptime = '1s';
SELECT pg_reload_conf();
-- 记得我们的vac表在创建时是关闭了autovacuum的,所以它还不会触发vacuum
TRUNCATE TABLE vac;
INSERT INTO vac(id,s) SELECT id, 'A' FROM generate_series(1,1000) id;
SELECT * FROM need_vacuum WHERE tablename = 'public.vac' \gx
开启vac表的autovacuum
ALTER TABLE vac SET (autovacuum_enabled = on);
SELECT * FROM need_vacuum WHERE tablename = 'public.vac' \gx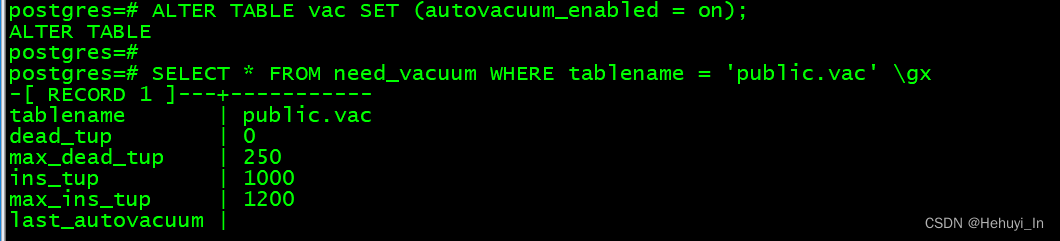
可以看到:
- 当前没有死元组(因为全是插入)
- 死元组vacuum阈值是50+0.2*1000=250
- 插入vacuum阈值是1000+0.2*1000=1200
另外,运行时长超过log_autovacuum_min_duration(0则所有都记录)的autovacuum会被记录到pg日志中,例如
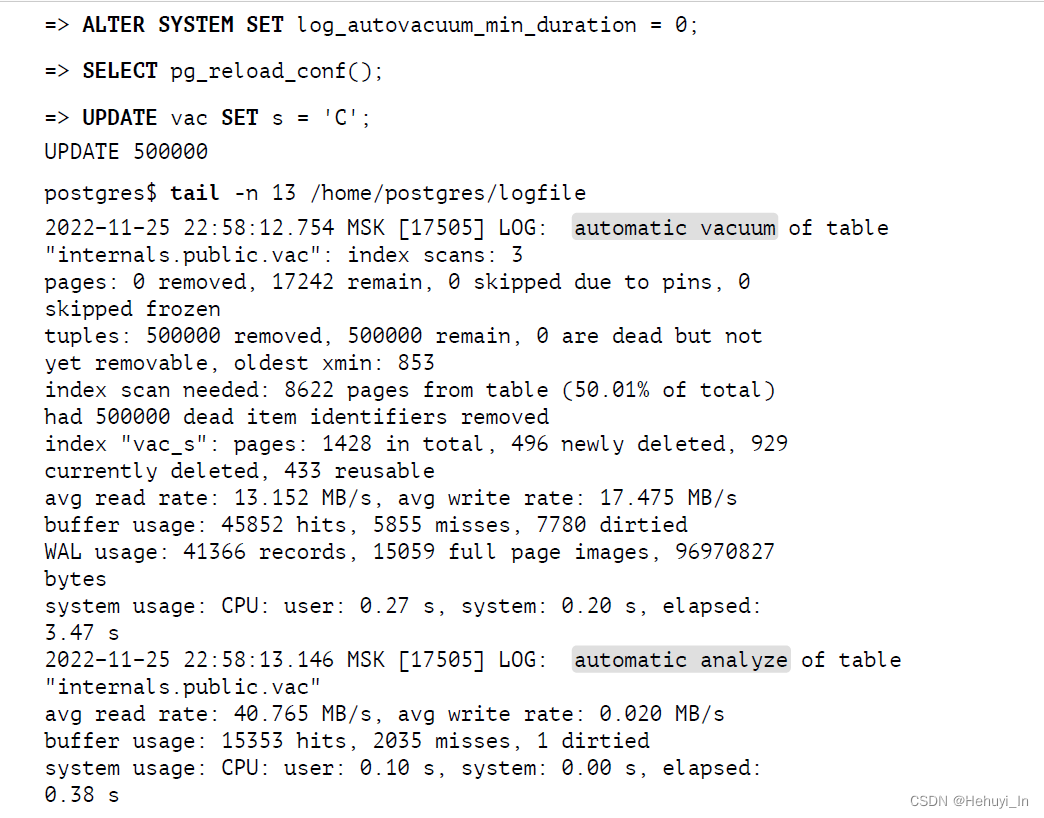
再看统计信息
SELECT * FROM need_analyze WHERE tablename = 'public.vac' \gx
可以看到:
- 元组修改analyze阈值是50+0.1*1000=150
- 当前插入1000行超过了该阈值,所以已经自动analyze了一次
- analyze后mod_tup重新计数,因此为0
我们来更新251行,这样vac表的死元组数会变成251,超过250,触发vacuum
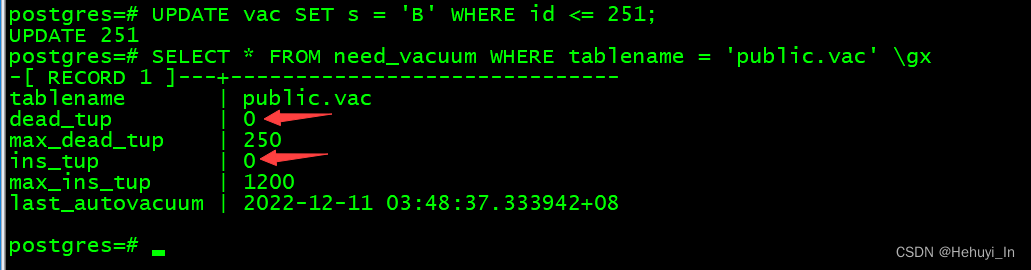
可以看到,vacuum已经触发,dead_tup和ins_tup重新计数
五、 负载管理
1. vacuum参数
主要是防止vacuum占用资源过多的一些参数
- vacuum_cost_limit:当进程vacuum cost达到此限制时会暂停,默认200
- vacuum_cost_delay:每次暂停的时间,默认0(ms数,0表示不限制)
- vacuum_cost_page_hit :vacuum时page在buffer命中的代价。默认1
- vacuum_cost_page_miss:vacuum时page未在buffer命中,需要从磁盘读入的代价,默认10
- vacuum_cost_page_dirty:vacuum时需要刷脏页到磁盘的代价,默认20
这些cost值相加如果超过limit,则会触发暂停。因此默认参数下,每次vacuum最多可以处理200个page,最少只能处理10个
2. autovacuum参数
- autovacuum_vacuum_cost_limit:含义同vacuum,默认值为-1,表示与vacuum一致
- autovacuum_vacuum_cost_delay:含义同vacuum,默认值为2ms
这两个参数针对普通表和toast表均有对应表级同名参数,可以针对各表调整。
六、 vacuum使用建议
1. 开启全局autovacuum
postgresql.conf设置autovacuum=on
2. 表级计划性vacuum
查询需要vacuum的表,即表dead tuple的量或比例,默认情况下可能有少于20%的dead tuple.
select relname,n_live_tup,n_dead_tup from pg_stat_all_tables where n_dead_tup<>0 order by n_dead_tup desc;3. 可以使用vacuumdb或者vacuumlo工具(安装目录bin下)手动清理
- vacuumdb工具清理数据库并对执行analyze操作
- vacuumlo工具清理数据库中无效的大对象
4. 适当调大maintenance_work_mem,可加快vacuum的执行速度
5. 对于有大量update的表,vacuum full一般没有必要,因为它的空间还会再次增长。定期监控数据量变化较大的表,确认其磁盘页面占有量接近临界值时,可考虑vacuum full。
参考
PGCE课程《维护管理》


















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











