







目录
3.设置参数之后:将两张大表分别insert到两个分桶表中,分桶字段就是等值连接的字段
本篇文章是对我之前写的《Hive学习——企业级调优》的补充。
一、表设计优化
1.通过设计分区表,增加动态分区,查询时避免全表扫描
2.设计分桶表:适用于大表join大表的情况
当10万条数据的用户表join 1000万条数据的订单表时,通过设置分桶表,每个用户装在一个桶中,避免了全表扫描。这样的 join 称为 SMB map join (Sort Merge Bucket Map Join),核心思想是大表化成小表,分而治之。
-- 第一张普通表
select *
from dw_zipper;
dw_zipper.userid dw_zipper.phone dw_zipper.nick dw_zipper.gender dw_zipper.addr dw_zipper.starttime dw_zipper.endtime
001 186xxxx1234 laoda NULL sh 2021-01-01 9999-12-31
002 186xxxx1235 laoer 1 bj 2021-01-01 9999-12-31
003 186xxxx1236 laosan 0 sz 2021-01-01 9999-12-31
004 186xxxx1237 laosi 1 gz 2021-01-01 9999-12-31
005 186xxxx1238 laowu 0 sh 2021-01-01 9999-12-31
006 186xxxx1239 laoliu 1 bj 2021-01-01 9999-12-31
007 186xxxx1240 laoqi 0 sz 2021-01-01 9999-12-31
008 186xxxx1241 laoba 1 gz 2001-01-01 9999-12-31
009 186xxxx1241 laojiu 0 sh 2021-01-01 9999-12-31
010 186xxxx1234 laoshi 1 bj 2021-01-01 9999-12-31
-- 另一张大表
select *
from ods_zipper_update;
ods_zipper_update.userid ods_zipper_update.phone ods_zipper_update.nick ods_zipper_update.gender ods_zipper_update.addr ods_zipper_update.startitme ods_zipper_update.endtime
008 186xxxx1241 laoda 1 sh 2021-01-02 9999-12-31
011 186xxxx1244 laoshi 1 jx 2021-01-01 9999-12-31
012 186xxxx1245 laoshi 0 zj 2021-01-01 9999-12-31
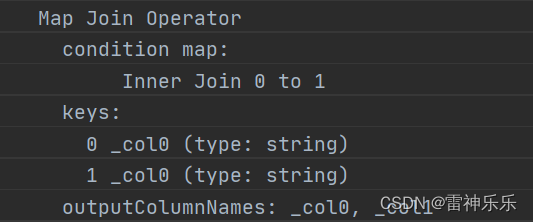
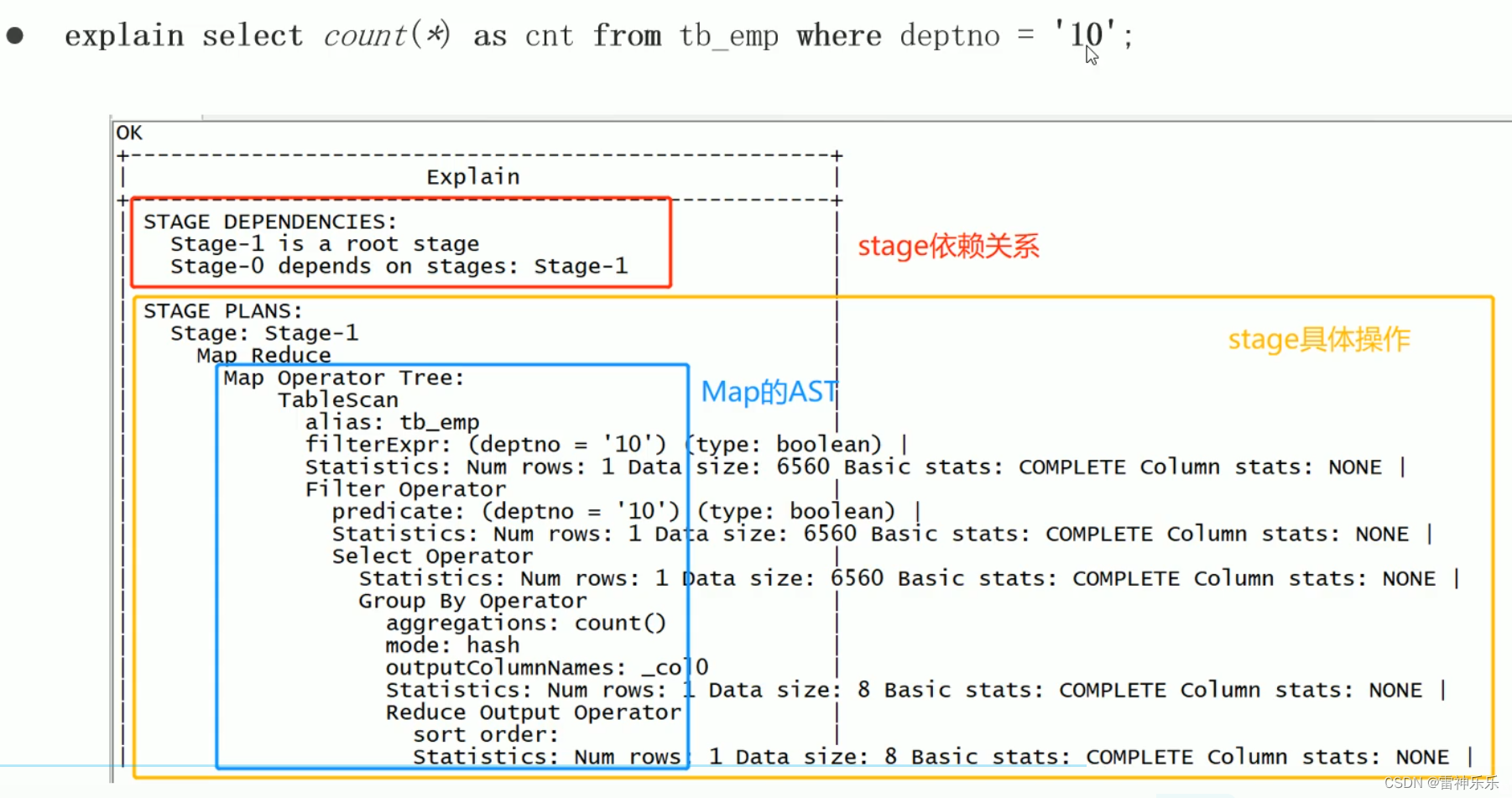
explain
select a.userid,
a.phone
from dw_zipper a
join ods_zipper_update b on a.userid = b.userid;设置参数之前,普通join相连:
3.设置参数之后:将两张大表分别insert到两个分桶表中,分桶字段就是等值连接的字段
-- todo 第一张分桶表
create table tb01
(
userid string,
phone string,
nick string,
gender int,
addr string,
startitme string,
endtime string
) clustered by (userid) sorted by (userid asc) into 3 buckets
row format delimited fields terminated by '\t';
-- todo 第二张分桶表
create table tb02
(
userid string,
phone string,
nick string,
gender int,
addr string,
startitme string,
endtime string
) clustered by (userid) sorted by (userid asc) into 3 buckets
row format delimited fields terminated by '\t';
-- todo 第一张分桶表赋值
insert into tb01 select * from dw_zipper;
select * from tb01;
-- todo 第二张分桶表赋值
insert into tb02 select * from ods_zipper_update;
select * from tb02;4.分桶后要设置下面三个参数:
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;5.最后,两张大表进行join转为两张分桶表进行join:
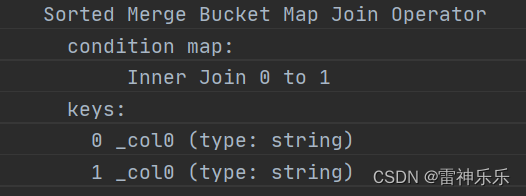
explain
select tb01.*
from tb01
join tb02 on tb01.userid = tb02.userid;6.执行计划变为bucket-mapJoin
二、文件存储
1.文件格式-概述
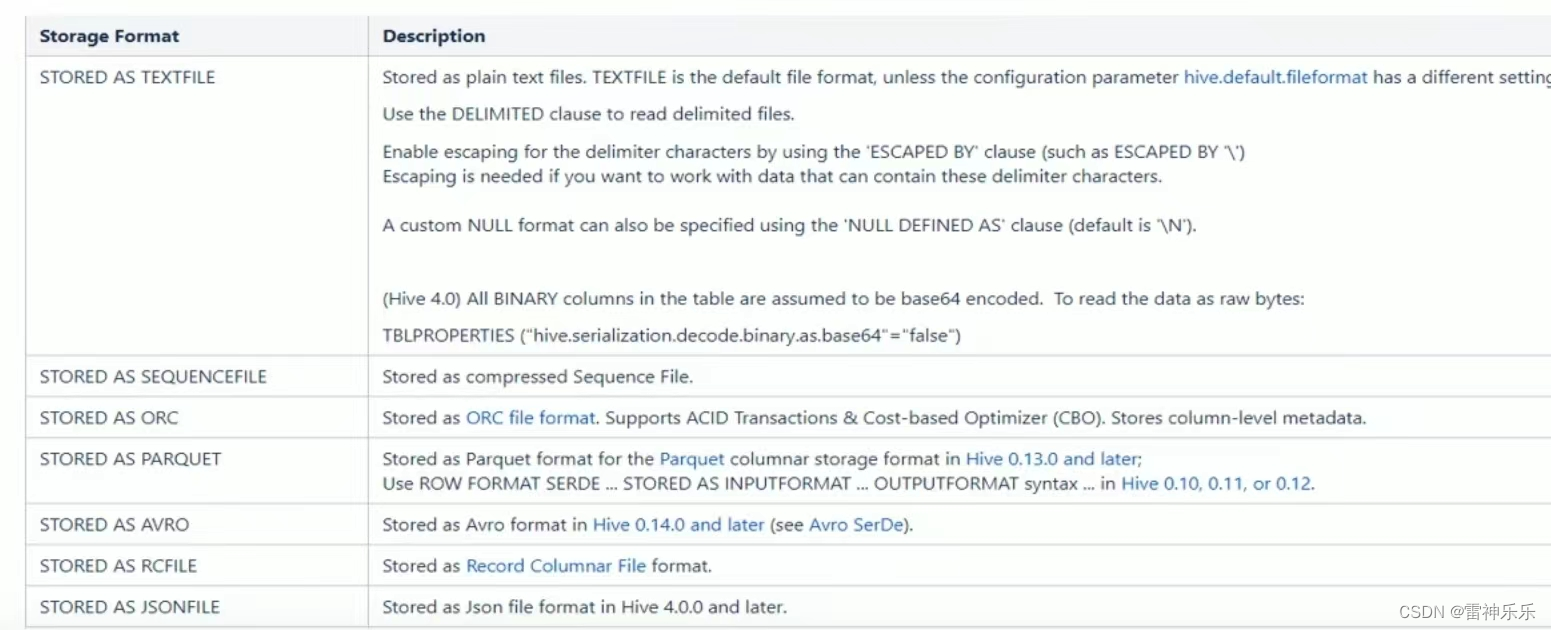
Hive数据存储的本质还是HDFS,所有的数据读写都基于HDFS的文件来实现;
为了提高对HDFS文件读写的性能,Hive提供了多种文件存储格式:TextFile、SequenceFile、ORC、Parquet等;
不同的文件存储格式具有不同的存储特点,有的可以降低存储空间,有的可以提高查询性能。
Hive的文件格式在建表时指定,默认是TextFile,建表时storted as 后面可以指定文件格式,该条语句不写,默认是TextFile:

2.文件格式——TextFile
- TextFile是Hive中默认的文件格式,存储形式为按行存储。
- 工作中最常见的数据格式就是TextFile文件,几乎多有的原始数据生成都是TextFile格式,所以Hive设计时考虑到了避免各种编码及数据错乱的问题,选用了TextFile作为默认的格式。
- 建表时不指定存储格式即为TextFile,导入数据时把数据文件拷贝到HDFS不进行处理。

案例:
文件大小不变:



3.文件格式——SequenceFile
- SequenceFile是Hadoop里用来存储序列化的键值对,即二进制的一种文件格式。
- SequenceFile文件也可以作为MapReduce作业的输入和输出,Hive也支持这种格式。
案例:
注意:指定存储格式时,直接将要存储的文件load到表中,数据并不能变为指定格式,必须要insert+select语法,底层走MR,才能将文件变为指定格式进行存储。create table tb_sogou_seq() row format delimited fields terminated by '\t' stored as sequencefile; insert into table tb_sogou_seq select * from tb_sogou_source;文件变小:
但是下载后是二进制文件:


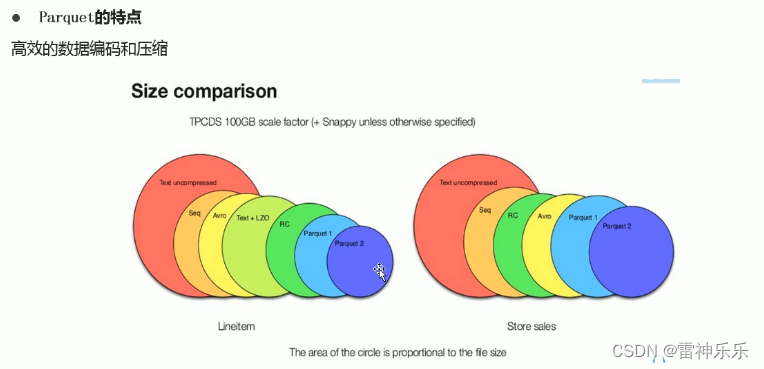
4.文件格式——Parquet
- Parquet是一种支持嵌套结构的列式存储文件格式
- 是一种支持嵌套数据模型对的列式存储系统,作为大数据系统中OLAP查询的优化方案,它已经被多种查询引擎原生支持,并且部分高性能引擎将其作为默认的文件存储格式。
- 通过数据编码和压缩,以及映射下推和谓词下推功能,Parquet的性能也较之其它文件格式有所提升。
案例:
create table tb_sogou_parquet() row format delimited fields terminated by '\t' stored as parquet; insert into table tb_sogou_parquet select * from tb_sogou_source;文件变小:


5.文件格式——ORC
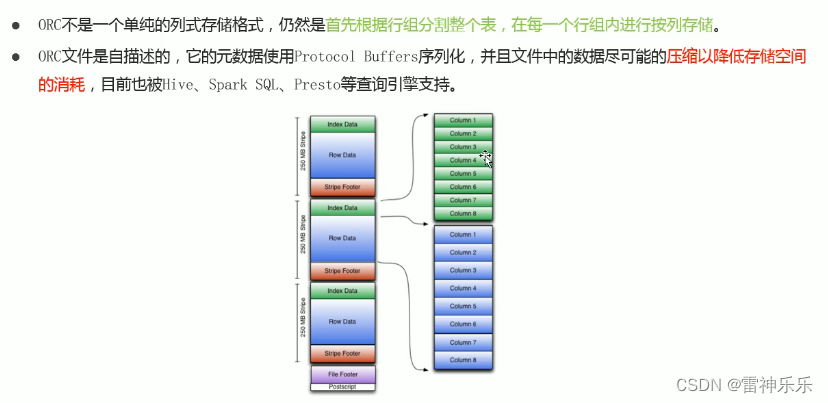
- ORC文件格式也是一种Hadoop生态圈中的列式存储格式;
- 它用于降低Hadoop数据存储空间和加速Hive查询速度;
案例:
create table tb_sogou_orc() row format delimited fields terminated by '\t' stored as orc; insert into table tb_sogou_orc select * from tb_sogou_orc;ORC文件格式将文件压缩地很小:
但是ORC底层为了降低存储空间,采用二进制序列化存储
总结:Hive推荐使用列式存储格式。



三、数据压缩
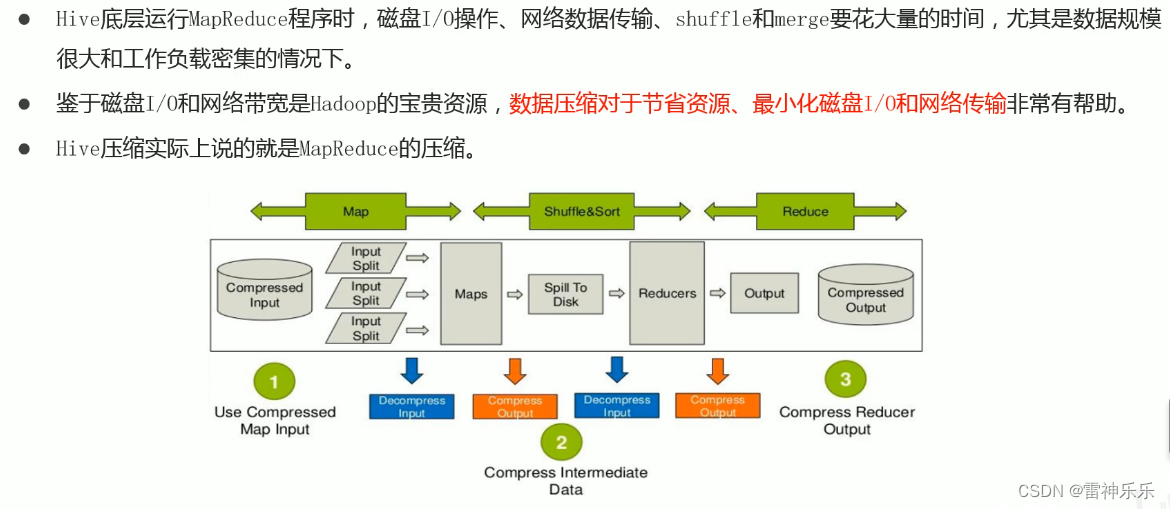
1.数据压缩概述

2.Hive中压缩
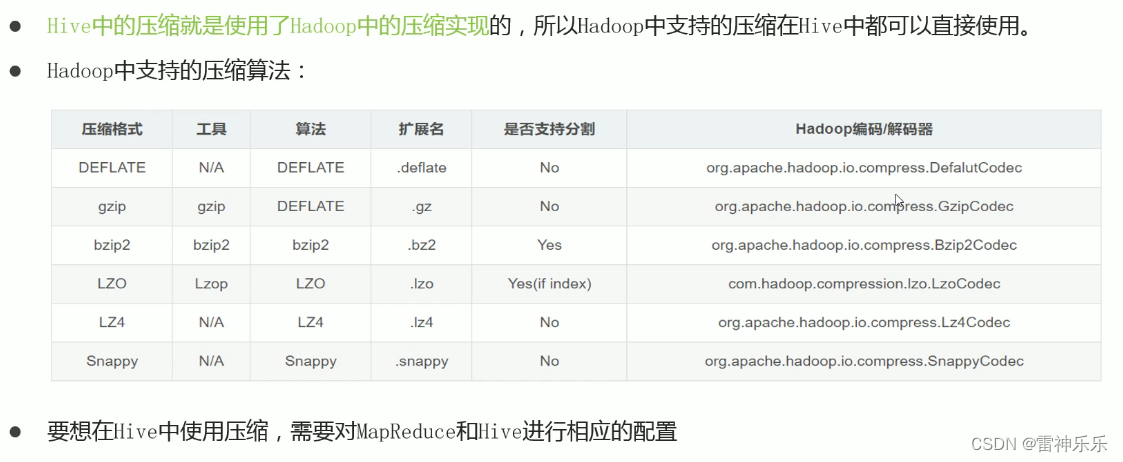
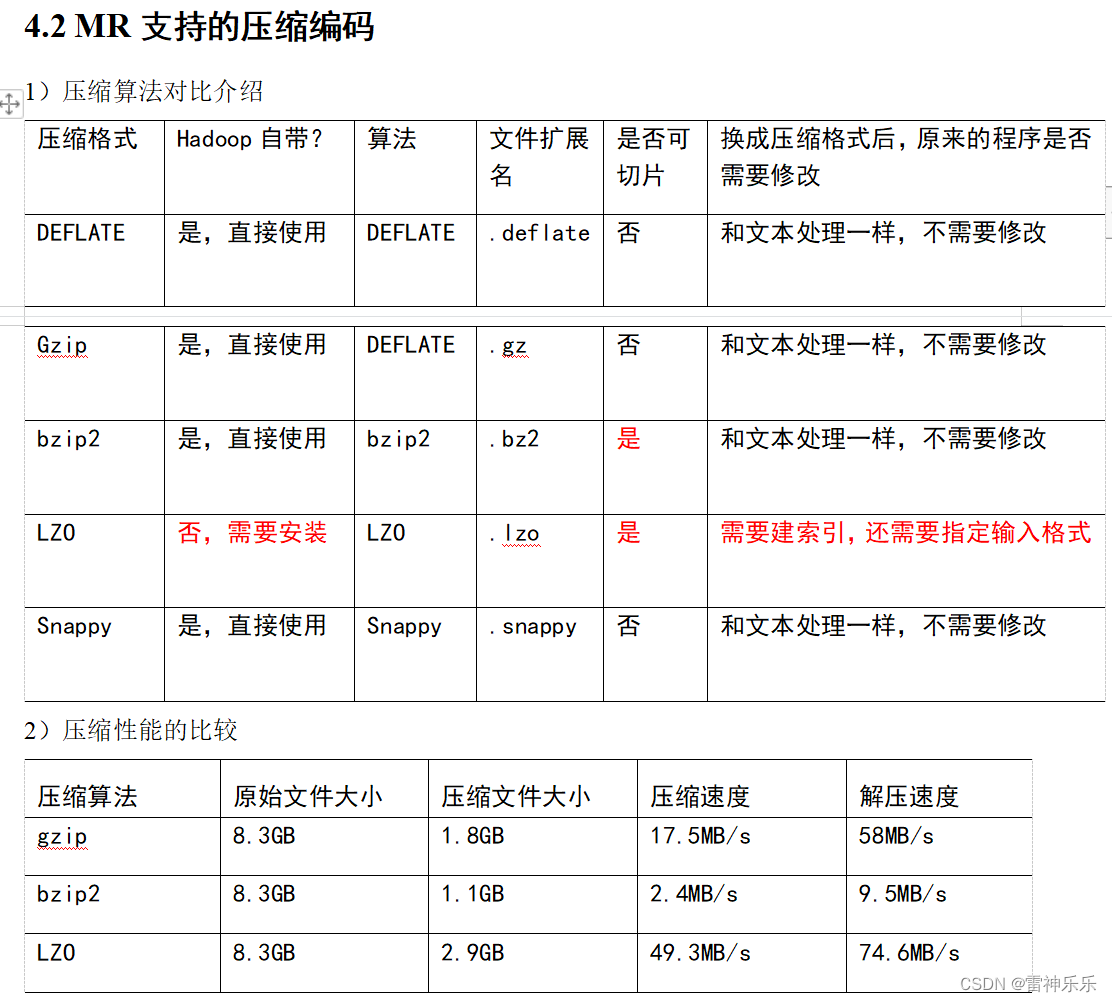
3.Hive中压缩配置
总结:实际工作中文件的压缩格式需要综合来选择。

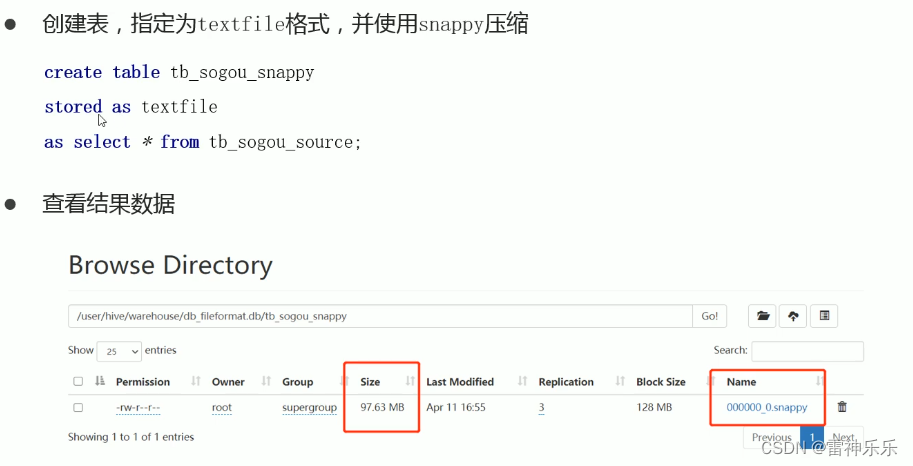
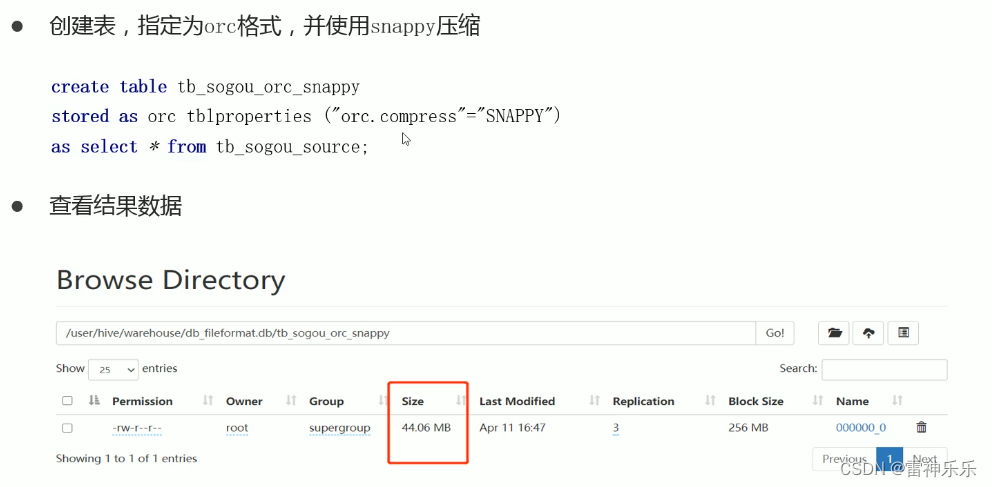
四、存储优化
1.避免小文件生成

2.合并小文件——当读取的数据就是小文件时
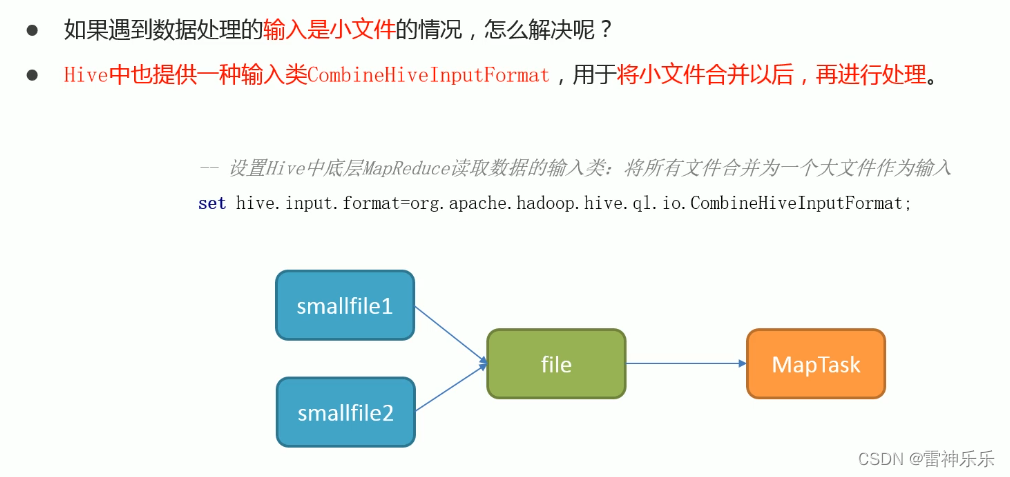
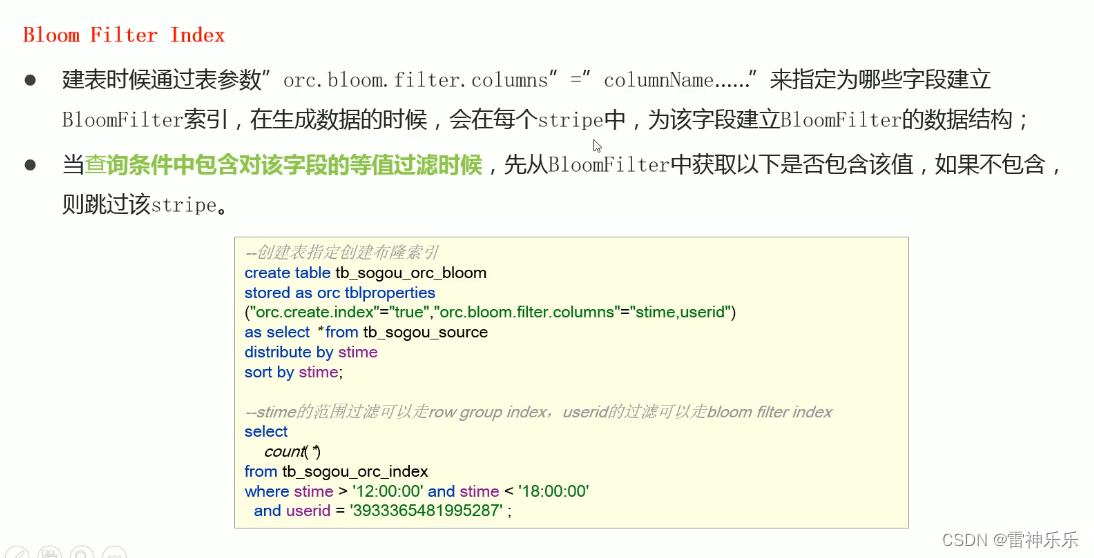
3.ORC文件索引
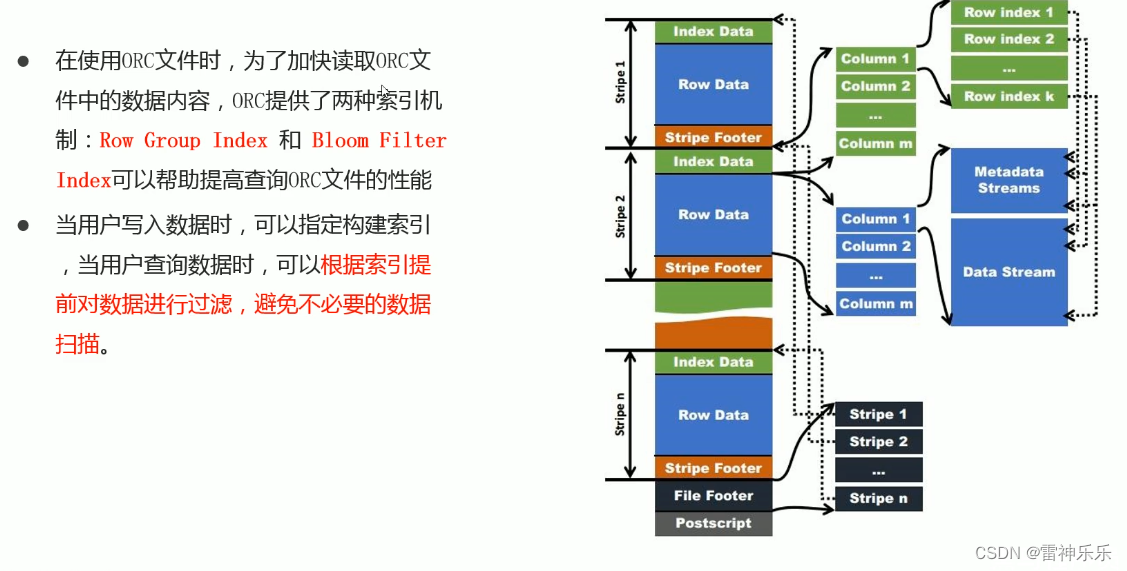

 Bloom过滤器:当它说一个值不存在时,一定不存在;当它说一个值存在时,可能存在。
Bloom过滤器:当它说一个值不存在时,一定不存在;当它说一个值存在时,可能存在。
4.ORC矢量化查询——按批读取

五、Explain执行计划


六、MR属性优化
1.本地模式

set hive.exec.mode.local.auto=true;注意:(1)当文件大小<128MB;
(2)mapTasks<4
(3)reduceTasks=1 or reduceTasks=0;
满足上面三个中的任意一个就能自动转换为本地模式,默认是false关闭状态。
2.并行执行

七、Job优化

hive可以自动判断用map端还是reduce端进行join。
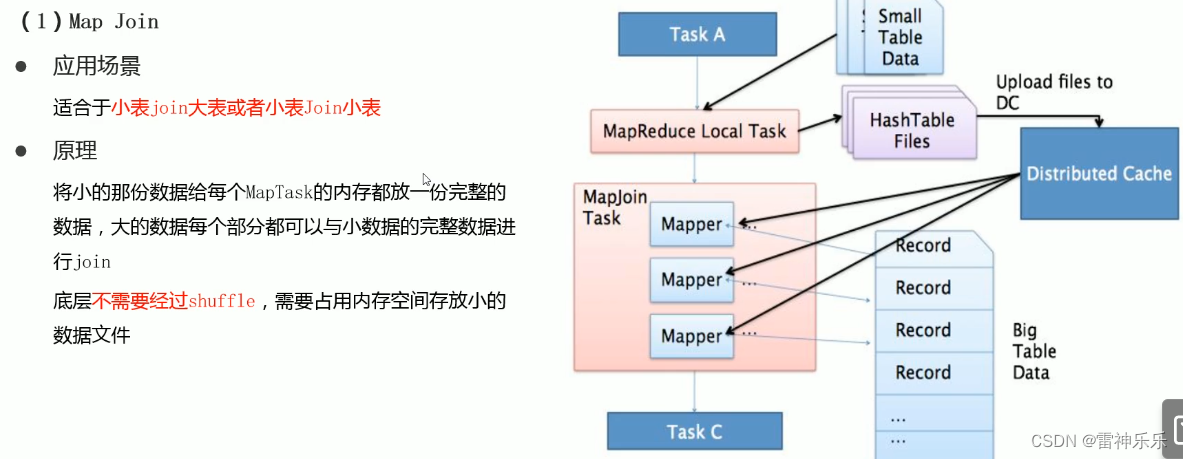
1.Map Join——小表join大表
在Map端进行join没有reduce,无需shuffle;
MapTask可以根据数据量大小自动调整并发度;
将小表数据做为分布式缓存,发送到各台机器上,再启动一个或多个MapTask读取大表数据,分别与缓存之间进行关联,关联结果输出。

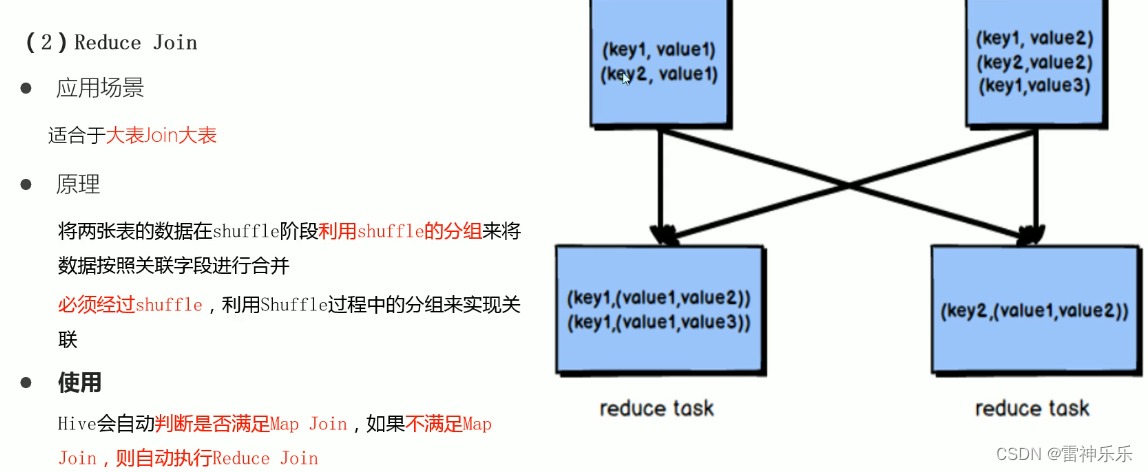
2.reduceJoin——大表join大表
分别读取两份大表的数据,在shuffle过程中,根据字段相同分到同一个reduce,将数据放在一起,在reduce阶段完成join操作。
3.Bucket Join——大表Join大表
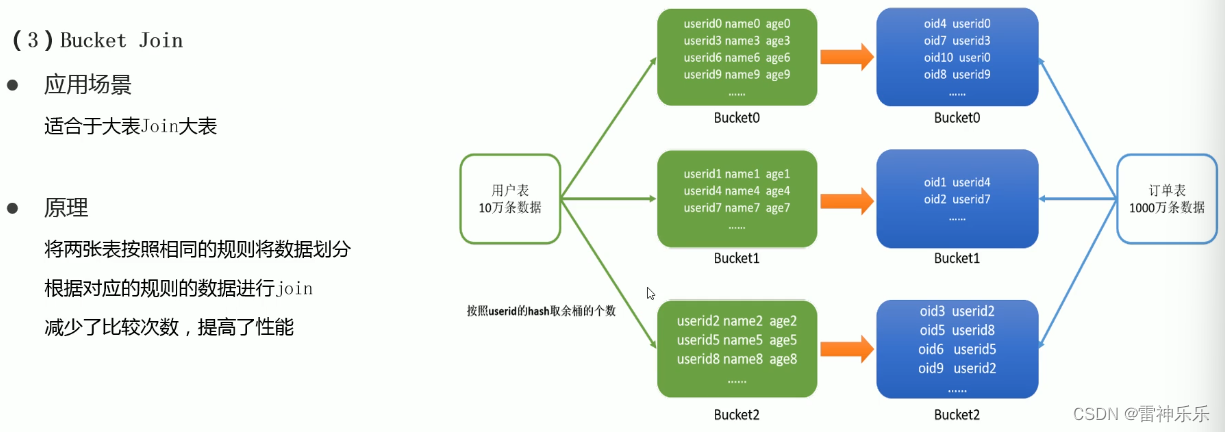
如果桶表join中,join的字段不是分桶的字段,将没有任何意义。
(1)桶表join优化

(2)SMB——除了桶表的join优化,还有桶表排序的join优化

八、优化器——关联优化


如果某些操作有相关性,可以放在一个MR中实现,例如上面的group by和order by的字段都是相同字段。
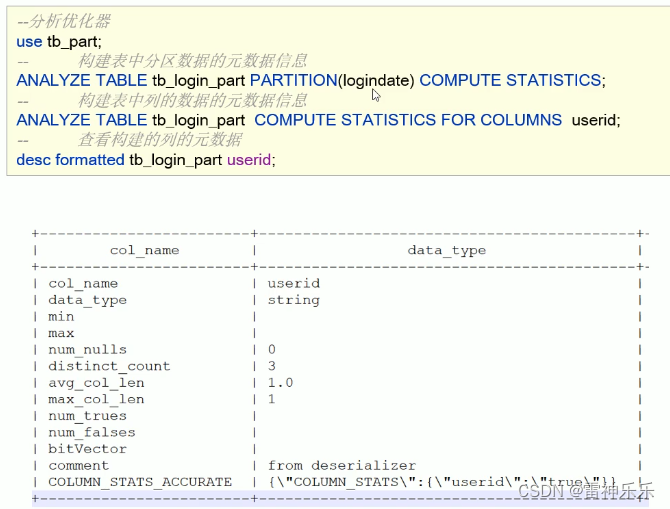
九、CBO优化
1.优化器引擎——背景

2.优化器引擎——CBO优化器

那么CBO引擎是如何判断哪种查询方案是更高效呢?原因是它的底层是Analyze分析器。

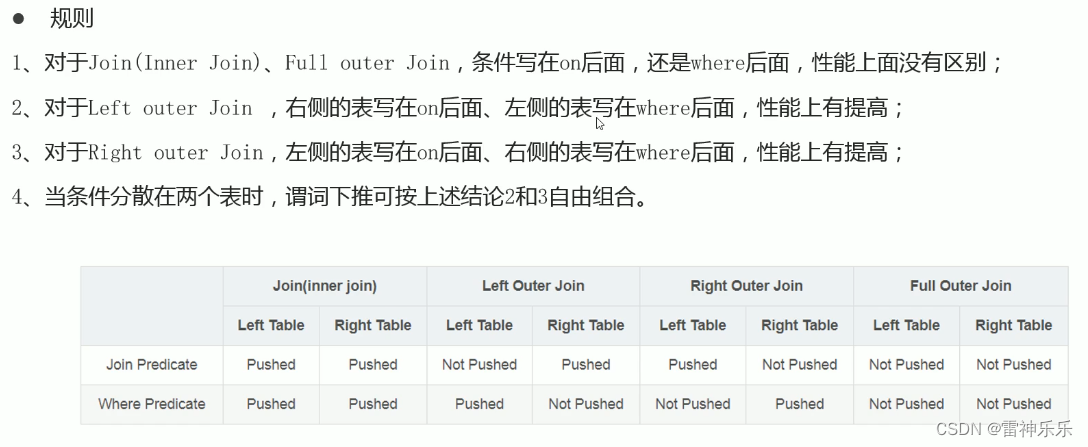
十、谓词下推(PPD)



十一、数据倾斜
(一)group by倾斜优化
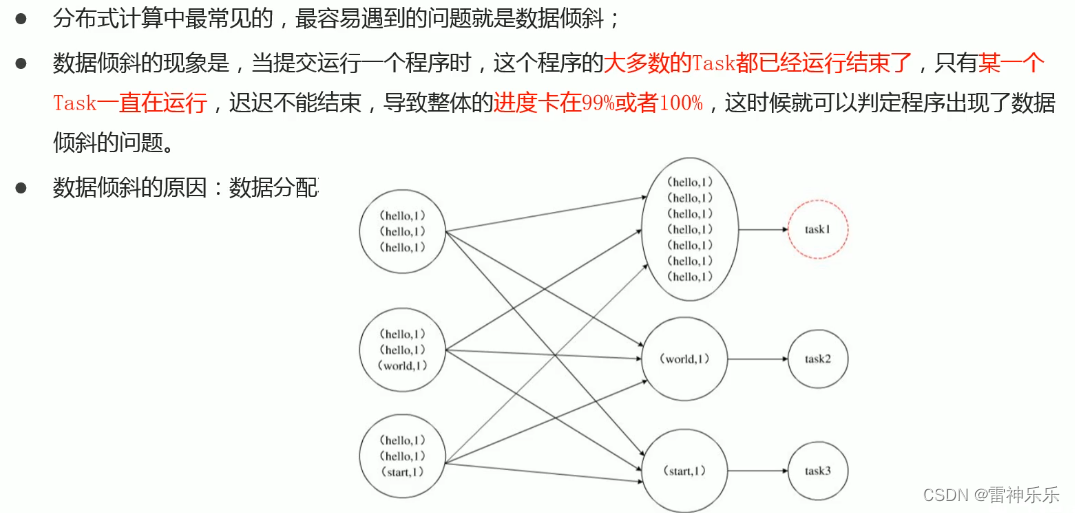
MR再运行HQL语句时,将相同的key分到一组,某一组的key有时会很多,另外一组的key很少,这就出现了数据倾斜。

1.开启Map端聚合
set hive.map.aggr=true;通过减少shuffle数据量和Reducer阶段的执行时间,避免每个YTask数据差异过大导致数据倾斜。
2.实现随机分区
selcet * from table distribute by rand();
distribute by 用于指定底层按照哪个字段作为key实现分区、分组等,通过rank函数随机值实现随机分区,避免数据倾斜。
3.数据倾斜时自动负载均衡——空间换时间
set hive.groupby.skewindata=true开启该参数以后,当前程序会自动通过两个MapReduce来运行。
第一个MR自动进行随机分布到Reducer中,每个Reducer做部分聚合操作,输出结果。
第二个MR将上一步聚合的结果再按照业务(group by key)进行处理,保证相同的分布到一起,最终聚合得到结果。
总之就是:先将key打散,分到不同的reducer中,然后再进行聚合。
(二)join倾斜优化

1.提前过滤,将大数据变成小数据,实现Map Join

2.使用Bucket Join
如果使用方案1,过滤后的数据依旧是一张大表,那么最后的Join依旧是一个Reduce Join,这种场景下,可以将两张表的数据构建为桶表,实现Bucket Map Join,避免数据倾斜。
3.使用Skew Join


















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









