







目前很多网站都使用ajax技术动态加载数据,和常规的网站不一样,数据时动态加载的,如果我们使用常规的方法爬取网页,得到的只是一堆html代码,没有任何的数据。
Ajax是利用 JavaScript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
Ajax基本原理
-
发送请求
-
解析内容
-
渲染页面
比如:
首先打开chrome浏览器,打开开发者工具,点击Network选项,点击XHR选项,然后输入网址:https://www.baidu.com/,点击Preview选项卡,就会看到通过ajax请求返回的数据,Name那一栏就是ajax请求,当鼠标向下滑动时,就会出现多条ajax请求:
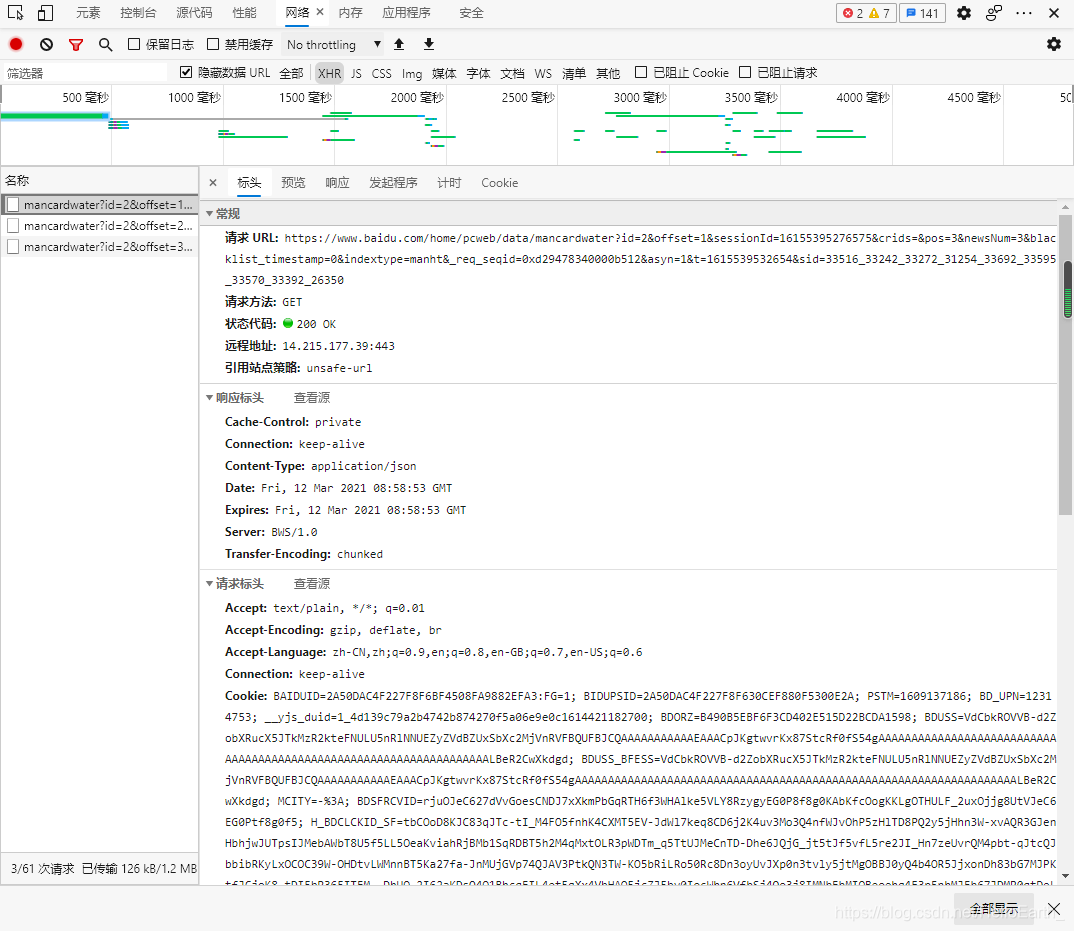
通过上图我们知道ajax请求返回的是json数据。
爬取AJAX有两种方式:
1.直接分析AJAX调用的接口。然后通过代码请求这个接口。
2.使用selenium+浏览器驱动模拟浏览器行为获取数据。
分析接口:
优点:直接可以请求到数据。不需要做一些解析工作。代码量少,性能高。
缺点:分析接口比较负责,特别是一些通过JS混淆的接口,要有一定的JS功底。容易被发现是爬虫。
selenium:
优点:直接模拟浏览器的行为。浏览器能请求到的,使用selenium也能请求到。爬虫更稳定。
缺点:代码量多。性能低。
AJAX调用接口
使用内建的模块urlilib。比如下面的使用urllib演示一个post请求代码
from urllib.request import urlopen
from urllib.request import Request
from urllib import parse
req = Request('http://www.thsrc.com.tw/tw/TimeTable/SearchResult')
postData = parse.urlencode([
("StartStation", "977abb69-413a-4ccf-a109-0272c24fd490"),
("EndStation", "2f940836-cedc-41ef-8e28-c2336ac8fe68"),
("SearchDate", "2018/01/06"),
("SearchTime", "10:30"),
("SearchWay", "DepartureInMandarin")
])
# header给的是来源和使用的请求工具浏览器
req.add_header("Origin", "http://www.thsrc.com.tw")
req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36")
resp = urlopen(req, data=postData.encode("utf-8"))
print(resp.read().decode("utf-8"))使用requests演示一个
import requests
parms = {"StartStation": "977abb69-413a-4ccf-a109-0272c24fd490","EndStation": "2f940836-cedc-41ef-8e28-c2336ac8fe68" ,"SearchDate": "2018/01/06" ,"SearchTime": "10:30" ,"SearchWay": "DepartureInMandarin"}
# requests.post(url, data=data, headers=headers)
r = requests.post('http://www.thsrc.com.tw/tw/TimeTable/SearchResult', headers={'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit', 'Origin': 'http://www.thsrc.com.tw', }
,json=parms)
print(r.text)要记得把header和请求的数据写完整。
selenium
requests和selenium的不同:
requests是通过模拟http请求来实现浏览网页的
selenuim是通过浏览器的API实现控制浏览器,从而达到浏览器自动化
首先配置chromedriver。下载chromedriver之前需要先检查下chrome浏览器的版本,点击浏览器帮助--->关于 google chrome,检查浏览器的版本。笔者的浏览器是75.0.3770.100版本的。
我们需要根据浏览器的版本下载相应的chromedriver版本,需要查看一下chrome浏览器版本和chromedriver版本的对照表。
------------2019年兼容版本对照表-----------
注:支持chromeV74版本的driver版本号比较特别一点,不知道之后会不会回归以前正常的版本
ChromeDriver 76.0.3809.12 (2019-06-07)---------Supports Chrome version 76
ChromeDriver 75.0.3770.8 (2019-04-29)---------Supports Chrome version 75
ChromeDriver v74.0.3729.6 (2019-03-14)--------Supports Chrome v74
ChromeDriver v2.46 (2019-02-01)----------Supports Chrome v71-73
--------以下为2018年兼容版本对照表-------
ChromeDriver v2.45 (2018-12-10)----------Supports Chrome v70-72
ChromeDriver v2.44 (2018-11-19)----------Supports Chrome v69-71
ChromeDriver v2.43 (2018-10-16)----------Supports Chrome v69-71
ChromeDriver v2.42 (2018-09-13)----------Supports Chrome v68-70
ChromeDriver v2.41 (2018-07-27)----------Supports Chrome v67-69
ChromeDriver v2.40 (2018-06-07)----------Supports Chrome v66-68
ChromeDriver v2.39 (2018-05-30)----------Supports Chrome v66-68
ChromeDriver v2.38 (2018-04-17)----------Supports Chrome v65-67
ChromeDriver v2.37 (2018-03-16)----------Supports Chrome v64-66
ChromeDriver v2.36 (2018-03-02)----------Supports Chrome v63-65
ChromeDriver v2.35 (2018-01-10)----------Supports Chrome v62-64
从对照表可以看出, 版本为ChromeDriver 75.0.3770.8支持Chrome version 75。笔者的浏览器(75.0.3770.100)是属于version 75,所以对应下载ChromeDriver 75.0.3770.8。
下载网址:http://npm.taobao.org/mirrors/chromedriver/
把下载好的chromedriver.exe放置在相应位置,修改代码中的路径即可
#-*- coding:utf-8 -*-
import time
from bs4 import BeautifulSoup
from selenium import webdriver
opt = webdriver.ChromeOptions() # 创建chrome对象
opt.add_argument('--no-sandbox') # 启用非沙盒模式,linux必填,否则会报错:(unknown error: DevToolsActivePort file doesn't exist)......
opt.add_argument('--disable-gpu') # 禁用gpu,linux部署需填,防止未知bug
opt.add_argument('headless') # 把chrome设置成wujie面模式,不论windows还是linux都可以,自动适配对应参数
driver = webdriver.Chrome(executable_path=r'/root/chromedriver',options=opt) # 指定chrome驱动程序位置和chrome选项
driver.get('https://baidu.com') # 访问网页
time.sleep(5) # 等待5秒
content = driver.page_source # 获取5秒后的页面
soup = BeautifulSoup(content,features='html.parser') # 将获取到的内容转换成BeautifulSoup对象
driver.close()
print(soup.body.get_text()) # 通过BeautifulSoup对象访问获取到的页面内容参考:
https://blog.csdn.net/well2049/article/details/78988189
https://blog.csdn.net/modabao/article/details/95017418
https://www.cnblogs.com/liuhui0308/p/12077963.html
https://www.cnblogs.com/liyihua/p/11182862.html















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









