







使用IDEA开发spark程序 (windows)
安装JDK
配置环境变量(计算机属性 - 高级设置 - 环境变量 - 新建 ):
JAVA_HOM= E:\Java\jdk1.8.0_101 PATH=E:\Java\jdk1.8.0_101\bin CLASSPATH=E:\Java\jdk1.8.0_101\lib安装scala
这个直接安装就可以了。但是要特别注意版本(会出现spark不兼容的情况),最好选用2.10的版本,我用的是2.10.4
配置Hadoop
HADOOP_HOME=E:\hadoop\deploy\hadoop-1.2.1 PATH=E:\hadoop\deploy\hadoop-1.2.1\bin
注意:向Hadoop的bin目录下添加winutils.exe文件。否则会报错:

附下载地址:链接: https://pan.baidu.com/s/1c01FEe 密码: 6e4k
4.配置spark应用开发环境
4.1 安装Intellij IDEA,在 “Configure” -> “Plugin” -> “Browse repositories” -> 输入scala ; (这里如果下载很慢或者失败可以直接去官网下载插件,然后这里选择本地文件)
4.2 用户在Intellij IDEA 中创建Scala Project, SparkTest
4.3 在菜单栏 “File” -> “project structure” -> “Libraries” 命定,单击 “+“,导入
spark-assembly-1.3.0-SNAPSHOT-hadoop2.5.0-cdh5.3.0.jar 包;
附下载地址:
5.试运行SparkPi程序
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/11/14.
*/
object Main {
def main(args: Array[String]):Unit= {
val conf = new SparkConf().setAppName("Spark Pi").setMaster("local")
//在本地运行设置Maser为local或者local[N]
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = 100000 * slices
val count = spark.parallelize(1 to n, slices).map { i =>
val x = Math.random * 2 - 1
val y = Math.random * 2 - 1
if (x * x + y * y < 1) 1 else 0
}.reduce(_ + _)
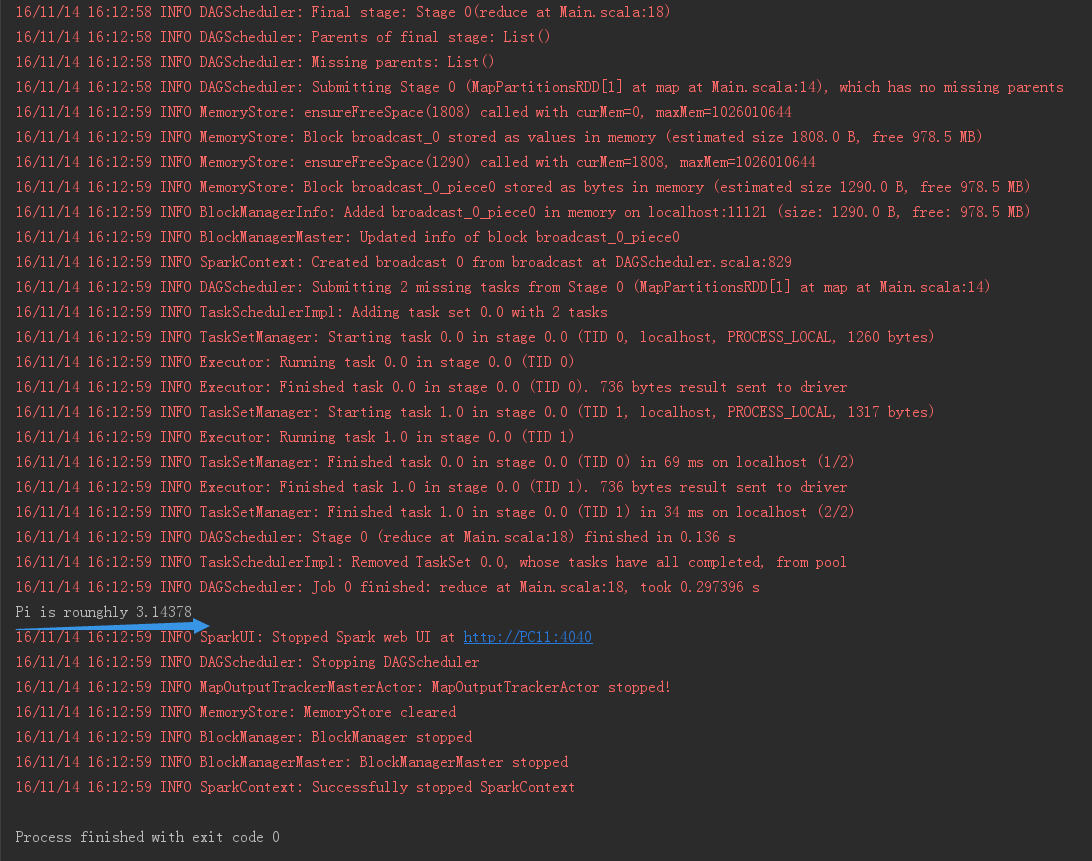
println("Pi is rounghly " + 4.0 * count / n)
spark.stop()
}
}运行结果为:
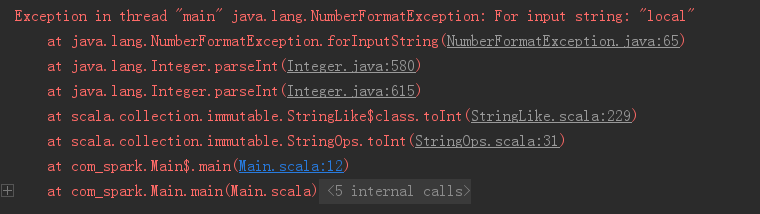
注意:不要在Edit configurations里面设置 “Program argument” 为 local,否则会出错;
错误为:















 5458
5458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









