






1、C++混合运算时的类型转换
隐式类型转换的依据:类型转换优先级序列(最上面有限级最高,从上到下依次递减)

不同类型转换会变化为优先级高的数据类型
注:short和char在运算时一律转换为int
eg:

unsigned比int的类型转换优先级跟高,所以计算结果应该以unsigned的方式来解释
解决方法:

2、数据类型
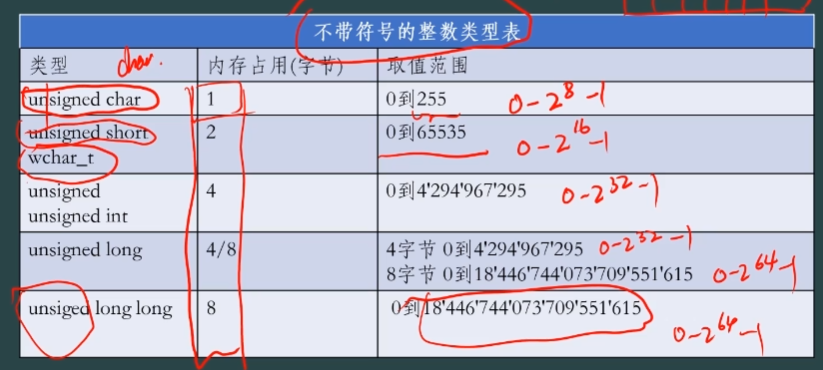
unsigned = unsigned int
3、要学习计算机组成原理的基础知识
0xffffffff在补码中表示-1
4、进制问题
为什么2进制经常用16进制和8进制来表示,而不用生活中常用的10进制表示?
因为3位2进制正好对应1位8进制
4位2进制正好对应一位16进制
而10进制没有与2进制相对应的位数,表示起来不是很方便
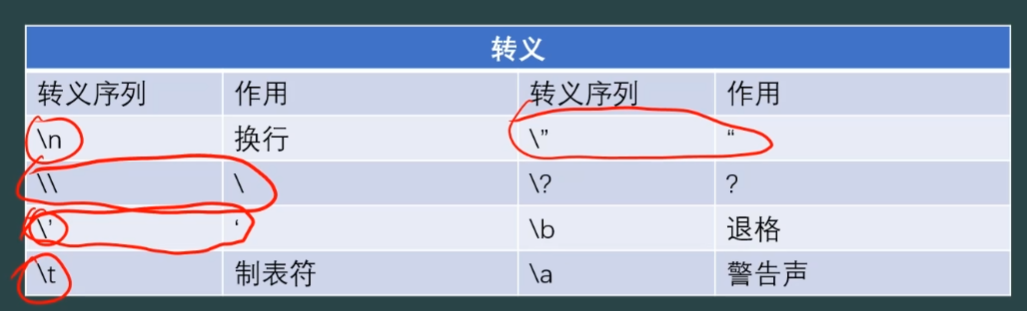
5、C++中最容易出现编码错误的问题(字符的编码问题)
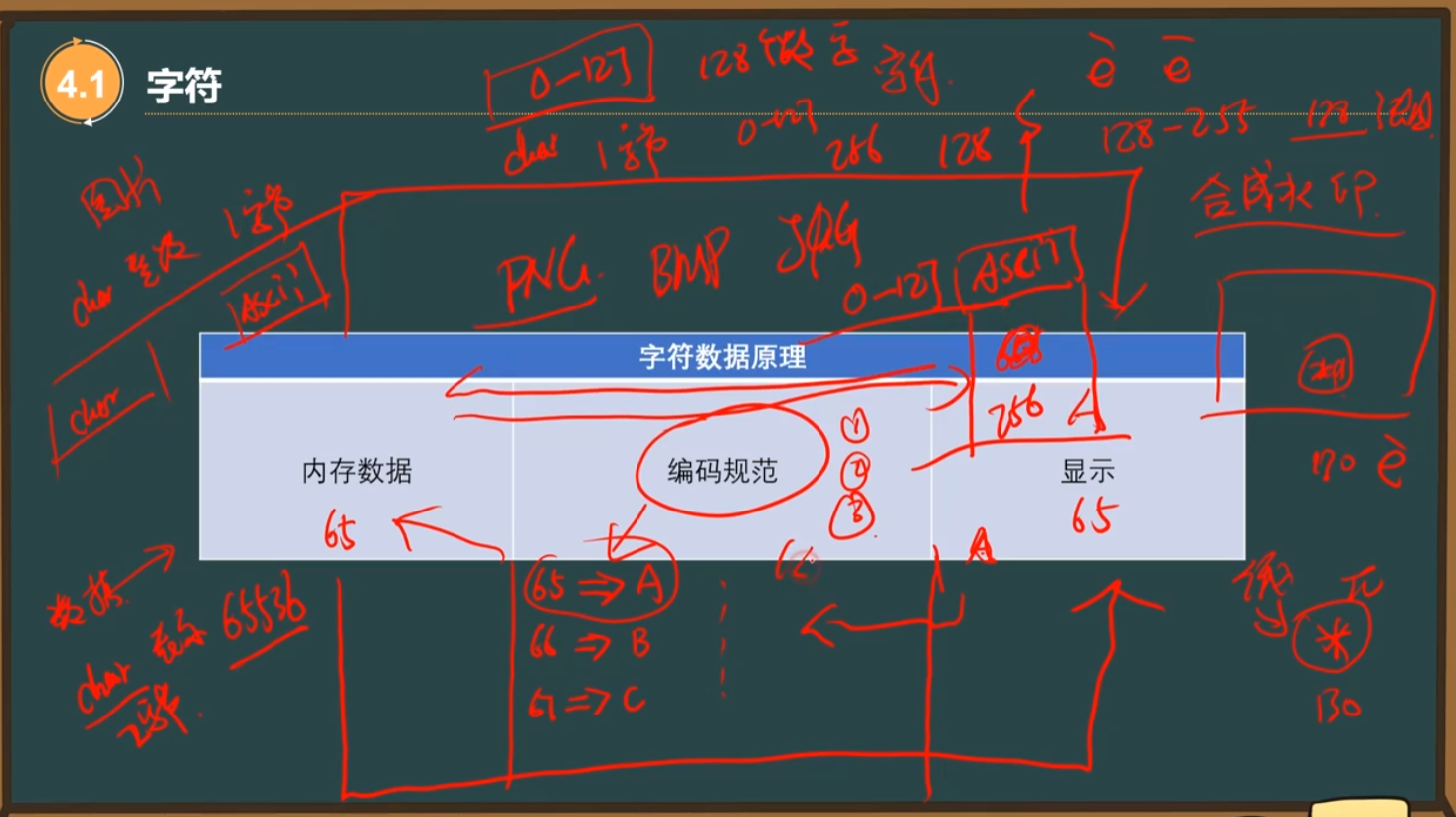
std::cout有自己的编码规范
万国统一码unicode 包含各个国家的文字和字符
中文用两个char表示
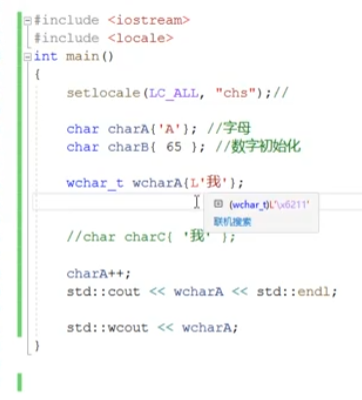
wchar宽字符前面要加L
英文和中文都占两个字节
6、ASCII编码表
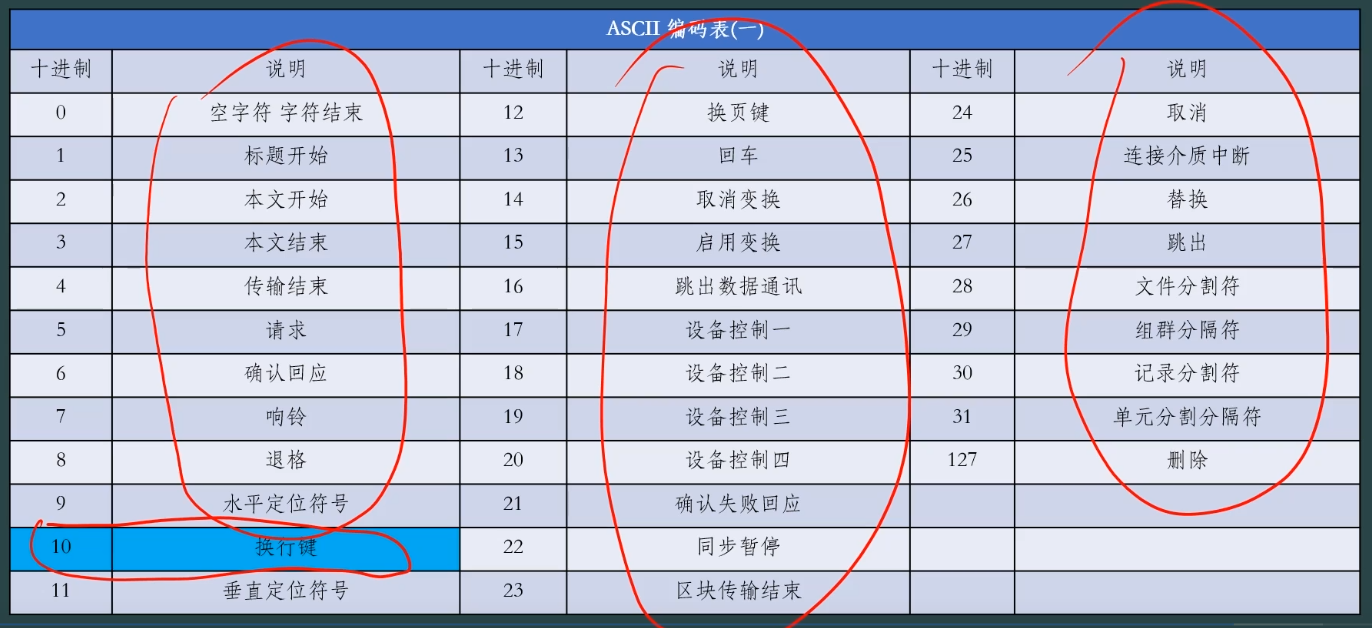
![]()
10是换行键对应的ASCII码,所以(char)10也可以当作换行符使用。
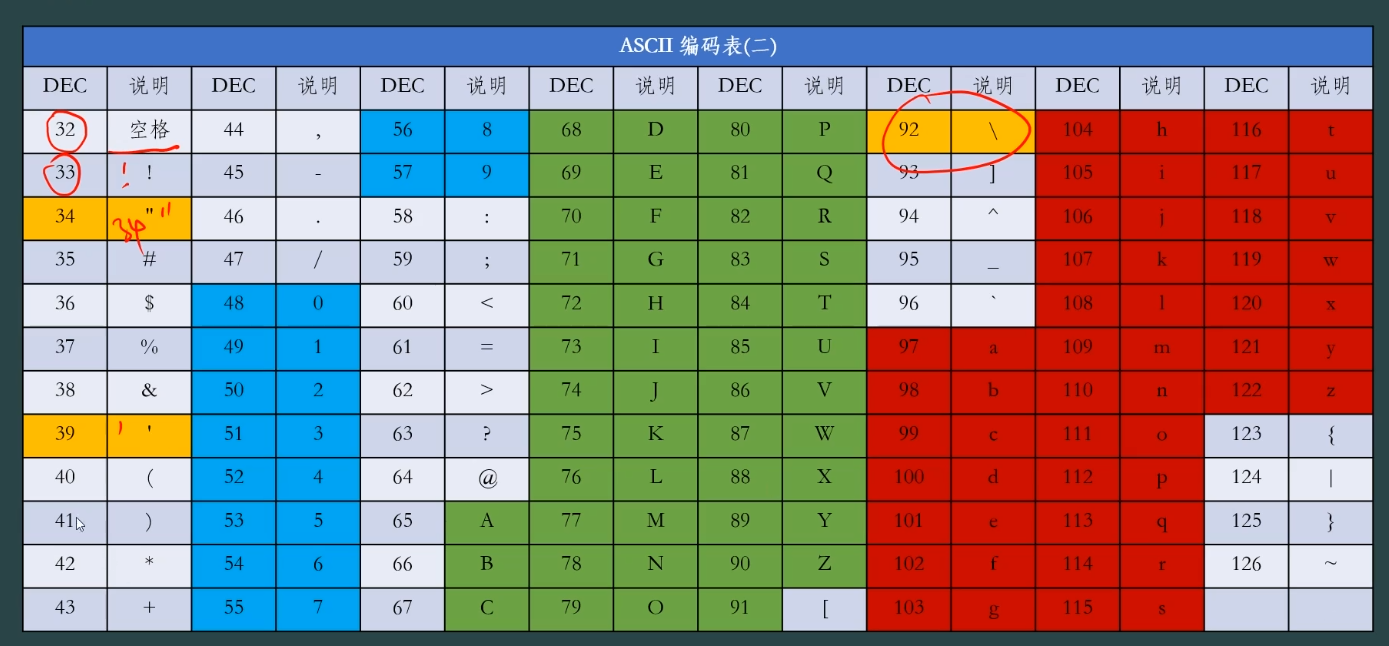
注:字符1和数字1是不同的
7、示例代码

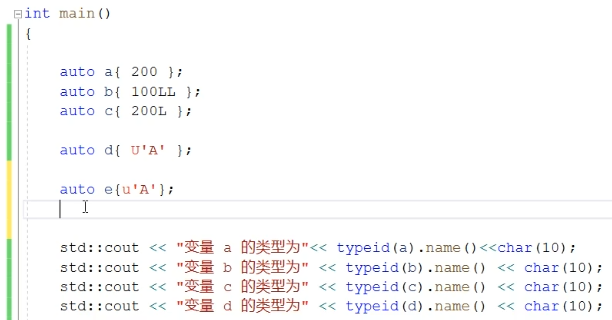
8、setfill()和setw()的使用
![]()
可以使用setfill()和setw()来有控制的输出大量相同字符
9、运算符优先级问题
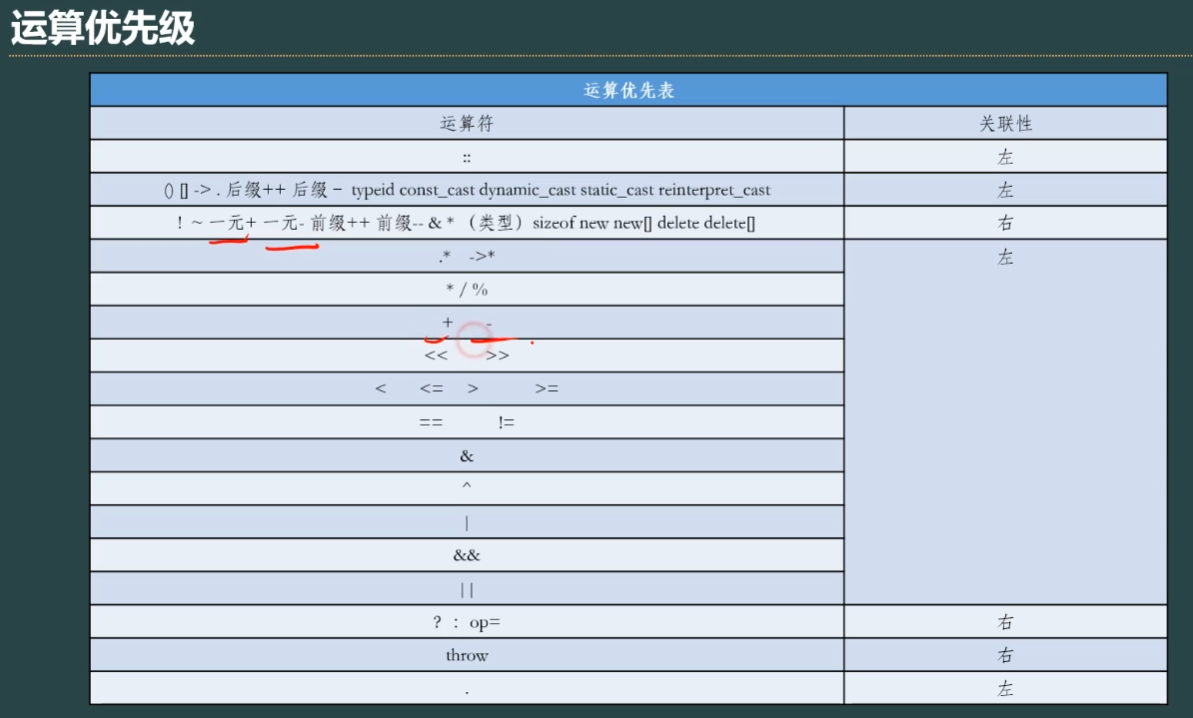
”一元+”“一元-”其实就是正负号
关联性的左右eg:-10 “一元-”的关联性是右,则“-”关联的是右边的10,从10到-号算
“+”号的关联性是左,a+b表示+号关联左边的a,是二元运算符
10、在编码时可以使用编译器来查看代码对应的反汇编代码,有助于理解代码的本质

反汇编代码
11、反汇编代码
vs2019在处理*2时会自动将*2优化为位运算,可以通过反汇编代码看出
12、负数的位运算
负数在右移时补1,原因是要让他保持在位移时数值除2的特性
在不同的编译器和环境中,int做位运算时所进行的操作可能会有差异,所以在写代码时尽量使用unsigned int来确保位运算的稳定性
13、异或运算的理解和使用
异或运算可以将两个二进制数不同的位给表现出来
14、不同的编码规范(极易出现bug的地方)
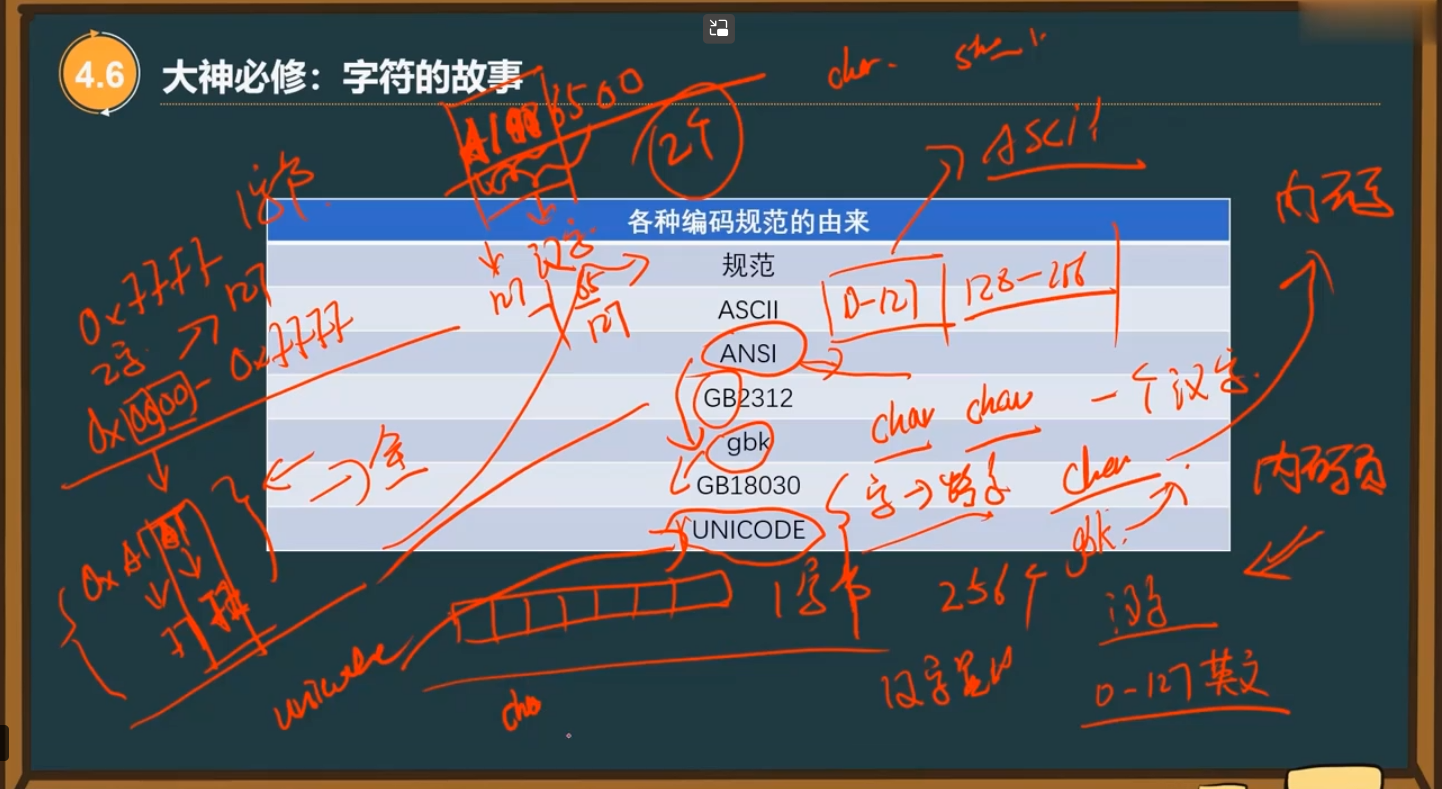
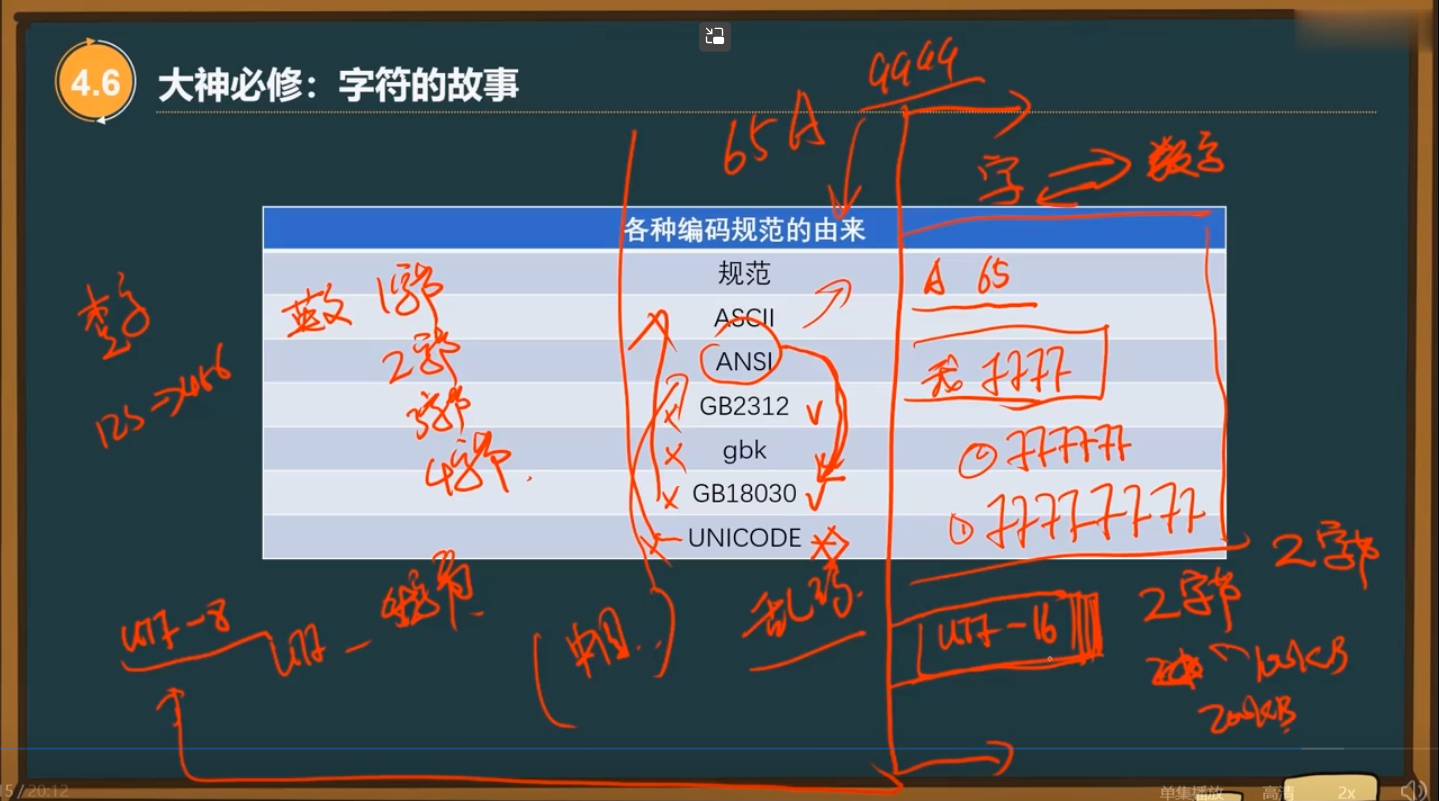
1、gbk为国标扩
2、UNICODE规范了字符对应的数字是什么,不会改变
而UTF-16(统一使用两个字节,存储英文比较浪费空间)、UTF-8(存储英文使用一个字节,存储中文时可以变换使用,可能是2或3或4个字节)、UTF-32(统一使用四个字节)是使用不同的策略来存储字符对应的固定的数字
3、UNICODE是一种规范,而UTF-16、UTF-8是具体的不同实现方式
4、在制作跨国网页时使用UTF-8,在使用时还要考虑ANSI或其他编码规范与UNICODE之间的转换,使用的是什么函数来转换相应的字符
5、中文占两个字符,英文占一个字符。当第一个字节大于127时,代表这个字节与后面一个字节合在一起的两个字节共同表示一个中文字符,而当第一个字节小于127时,这个字节就代表一个英文字符















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









