







《 Centos7下Zookeeper集群的搭建与测试 》
前言:
在这儿通过搭建三个 zookeeper 实例,实现 zookeeper 的集群环境的搭建工作,在实际开发工作中,将对应的 zookeeper 实例修改为各个 zookeeper 服务器节点即可实现同样的效果。如果对 zookeeper 的相关操作,不是很熟悉,建议先从 《 搭建单机版 Zookeeper 分布式应用程序协调服务 》开始!!!
搭建环境:
操作系统:Centos7zookeeper 版本:zookeeper-3.5.3
JDK 版本 : jdk-1.8
zookeeper-3.5.3 下载 http://download.csdn.net/download/hello_world_qwp/102223051、搭建 zookeeper 前准备
在这儿手首先需要先安装 JDK 环境哟 《 Linux下Jdk1.8的安装与环境变量配置教程 》
1)、存储快照文件snapshot的目录。默认情况下,事务日志也会存储在这里,所以在这儿需要创建三个 “数据文件” 目录:
“ mkdir /home/temp/cluster_zk/data/zk_data_001 -p ”“ mkdir /home/temp/cluster_zk/data/zk_data_002 -p ”
“ mkdir /home/temp/cluster_zk/data/zk_data_003 -p ”
创建完成后,如下图:

注意:创建完成后,在每个 data 目录下,创建一个 myid,直接输入命令 “ vi myid ”,输入值保存即可,id 范围: 1001~1003 后面好用!
或者输入命令 “ echo "1001">myid ” 进行设值,输入命令 “ cat myid ” 可以查看是否设值成功,这个比较好用哟!!!
2)、日志的目录,将日志存放在指定的日志目录中:
“ mkdir /home/temp/cluster_zk/logs/zk_logs_001 -p ”
“ mkdir /home/temp/cluster_zk/logs/zk_logs_002 -p ”
“ mkdir /home/temp/cluster_zk/logs/zk_logs_003 -p ”
创建完成后,如下图:

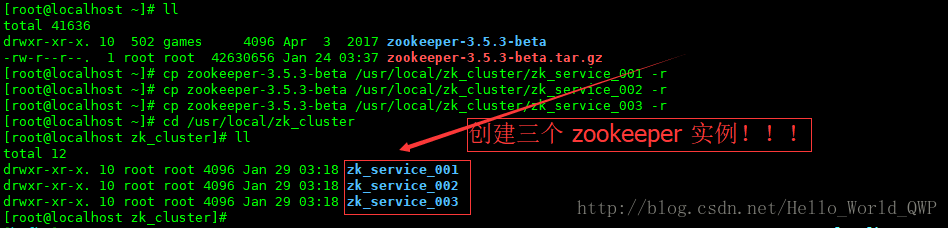
2、创建三个 zookeeper 实例:
“ cp zookeeper-3.5.3-beta /usr/local/zk_cluster/zk_service_001 -r ”“ cp zookeeper-3.5.3-beta /usr/local/zk_cluster/zk_service_002 -r ”
“ cp zookeeper-3.5.3-beta /usr/local/zk_cluster/zk_service_003 -r ”
创建完成后,如下图:
3、修改 zookeeper 配置文件:
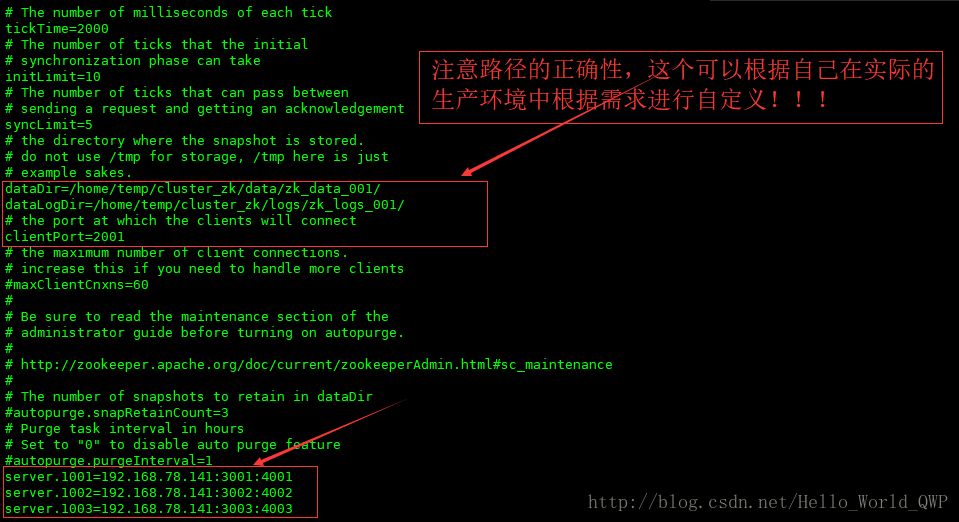
使用端口范围:2001~2003配置详解:
# zookeeper 中的一个时间单元,以毫秒为单位
tickTime=2000
# follower 在启动过程中,会从leader同步所有最新数据,然后确定自己能够对外服务的起始状态。
# leader 允许在 initLimit 时间内完成这个工作
initLimit=10
# 如果 leader 发出心跳包在 syncLimit 之后,还没有从 follower 那里收到响应,那么就认为这个已经不在线了
syncLimit=5
# 存储快照文件snapshot的目录。默认情况下,事务日志也会存储在这里。
# 建议同时配置参数dataLogDir, 事务日志的写性能直接影响zk性能。
dataDir=/home/temp/cluster_zk/data/zk_data_001/
# 在这个指定了日志的目录,日志存放在指定的日志目录中
dataLogDir=/home/temp/cluster_zk/logs/zk_logs_001/
# 客户端连接server的端口,即对外服务端口
clientPort=2001
# 单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,
# 如果设置为0,那么表明不作任何限制
#maxClientCnxns=60
# 这个参数和下面参数配合使用
# 指定了需要保留的文件数目。默认是保留3个
#autopurge.snapRetainCount=3
# 3.4.0 及之后版本,zookeeper 提供了自动清理事务日志和快照文件的功能,
# 这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,
# 0表示不开启自动清理功能
#autopurge.purgeInterval=1
# 这儿三台机器都可以一样
# 语法格式:server + myid = IP + 选举端口 + 投票端口
server.1001=192.168.78.141:3001:4001
server.1002=192.168.78.141:3002:4002
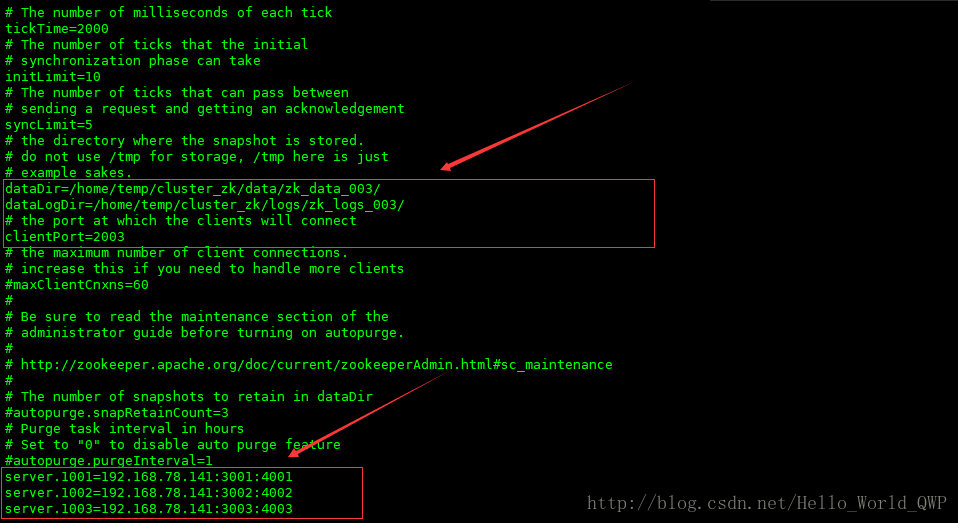
server.1003=192.168.78.141:3003:4003zookeeper 实例一:zk_service_001 配置后,如下图:
zookeeper 实例二:zk_service_002 配置后,如下图:
zookeeper 实例三:zk_service_003 配置后,如下图:

注意:需要先将 zookeeper 的配置文件修改为 “ zoo.cfg ”,不能直接使用 “ zoo_simple.cfg ” 配置文件,不然后面会报错;
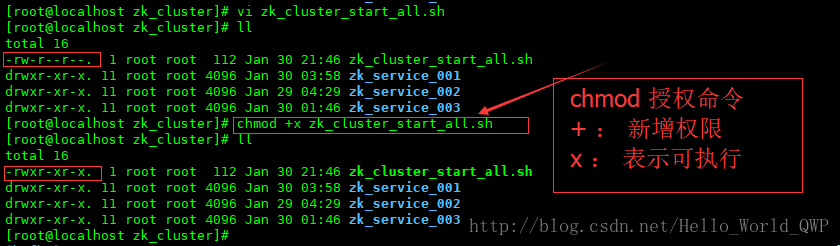
4、编写 zookeeper 集群启动脚本儿
为了方便启动节点,不用每次都去单个节点启动,这儿编写一个启动脚本儿,输入命令 “ vi zk_cluster_start_all.sh ” ,启动脚本儿创建完成后,还需要新增可执行的权限,输入命令 “ chmod +x zk_cluster_start_all.sh ” ,如下图:
脚本儿内容:

测试启动脚本儿,如下图:
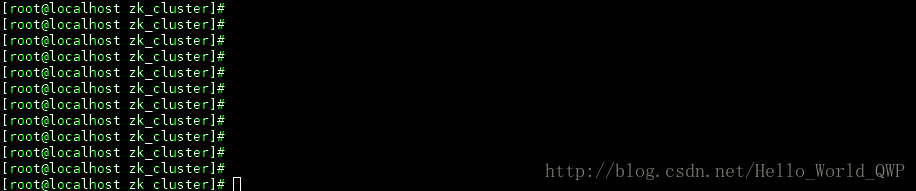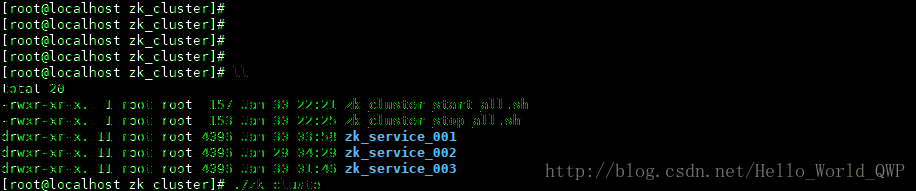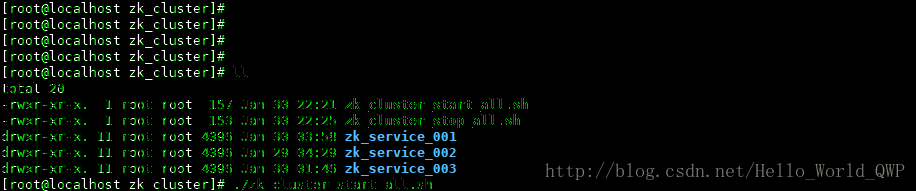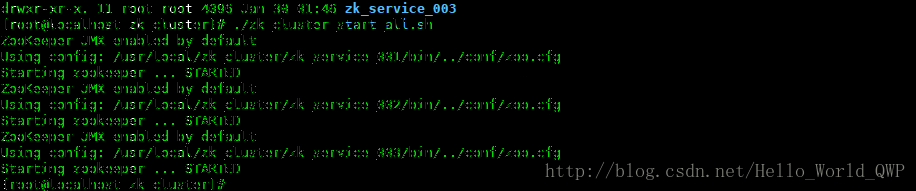
5、编写 zookeeper 集群停止脚本儿
不用每次都去单个节点停止,这儿再编写一个停止脚本儿,输入命令 “ vi zk_cluster_stop_all.sh ” ,zookeeper 集群服务停止脚本儿创建完成后,还需要新增可执行的权限,输入命令 “ chmod +x zk_cluster_stop_all.sh ” ,如下图:
测试停止脚本儿,如下图:

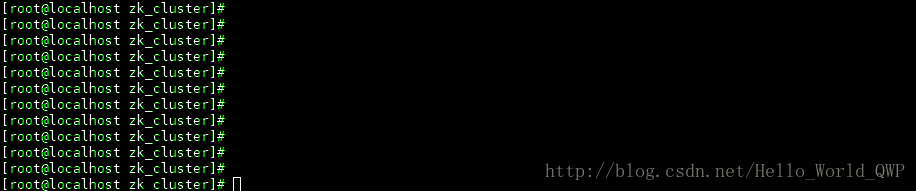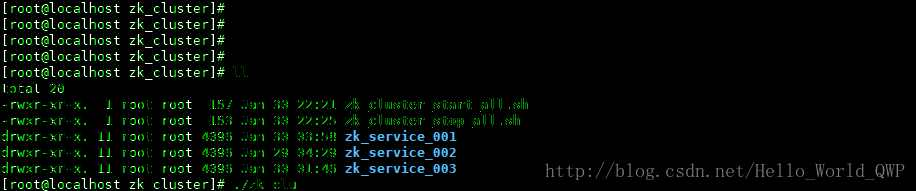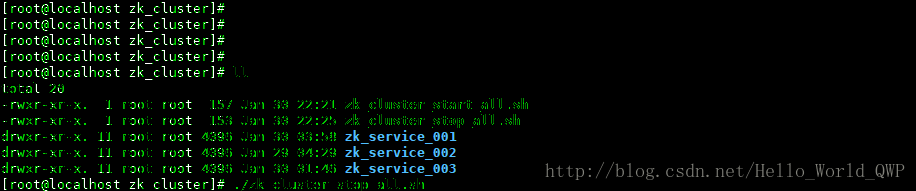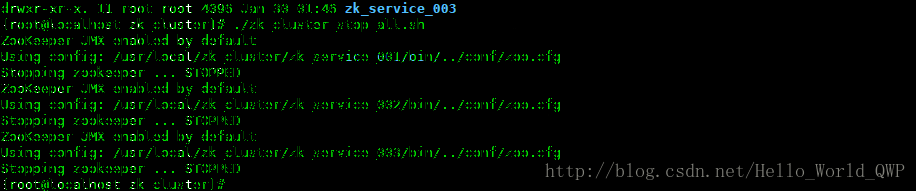
6、zookeeper 集群环境测试
1)、连接到 zookeeper 实例一输入命令 “ zk_service_001/bin/zkCli.sh -server 192.168.78.141:2001 ”
当然也可以直接输入命令 “ zk_service_001/bin/zkCli.sh ” 进行连接,
关于这个连接命令没有特殊要求,上面个连接命令是我个人习惯!!!
并新建一个永久节点,输入命令 “ create /zk/node_001 huazai ”
获取节点的元数据,输入命令 “ get /zk/node_001 ”
操作内容如下图:
2)、查看节点同步情况,连接到 zookeeper 实例二
输入命令 “ zk_service_002/bin/zkCli.sh -server 192.168.78.141:2002 ”

3)、查看节点同步情况,连接到 zookeeper 实例三
输入命令 “ zk_service_003/bin/zkCli.sh -server 192.168.78.141:2003 ”


7、zookeeper 主从节点测试
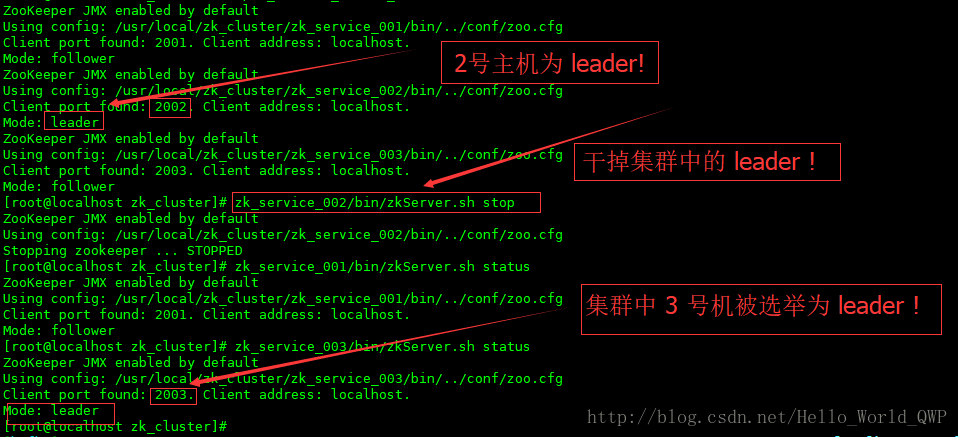
在一个集群环境中,当一个 “ leader ” 实力宕机的时候,从节点 “ follower ” 自动选举;在剩余的 “ follower ” 中选举出一个 “ leader ” ,让生产环境可以继续正常的工作,这就是集群实际存在的意义。
下面我将模拟集群中的 “ leader ” 主机出现宕机的情况,也就是把 zookeeper 实例二干掉,在查看状态时;
发现 zookeeper 实例三被选举为了 “ leader ” 了。
如下图:
在集群启动时,你可能遇到 zookeeper 集群启动成功,但是链接失败的问题如下图:

解决方案已经为你准备,拿去不谢!《 zookeeper 集群启动失败 》
其中涉及到 zookeeper 节点的操作,可以参考这儿 《 zookeeper_cli 客户端命令实操 》
在这儿再介绍两个在 zookeeper 使用上比较多的场景或比较实用的场景:
- 一)、共享锁(Locks)
- 二)、队列管理
1)、当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。
2)、 队列按照 FIFO 方式进行入队和出队操作,例如实现生产者和消费者模型。
同步队列用 Zookeeper 实现的实现思路如下:
创建一个父目录 /synchronizing,每个成员都监控标志(Set Watch)位目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列,加入队列的方式就是创建 /synchronizing/member_i 的临时目录节点,然后每个成员获取 / synchronizing 目录的所有目录节点,也就是 member_i。判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start。
好了,关于 zookeeper 集群环境的搭建就到此结束了,如果还有什么疑问或遇到什么问题,可以给我留言。
歇后语:“共同学习,共同进步”,也希望大家多多关注CSND的IT社区。
需要了解更多关于 zookeeper 相关的内容,请点击下面 图标 进入官网:
















 2826
2826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









