







常用的线程池创建
一、为什么要使用线程池
1.线程池多数使用在高并发的情况下,使用线程池可以重复利用已经创建的线程,减少了线程创建和销毁时的资源消耗;
2.由于没有频繁创建和销毁线程,使得系统效率可以大大提升;
3.可以控制线程数量,更有效的利用系统资源;
二、线程池执行流程
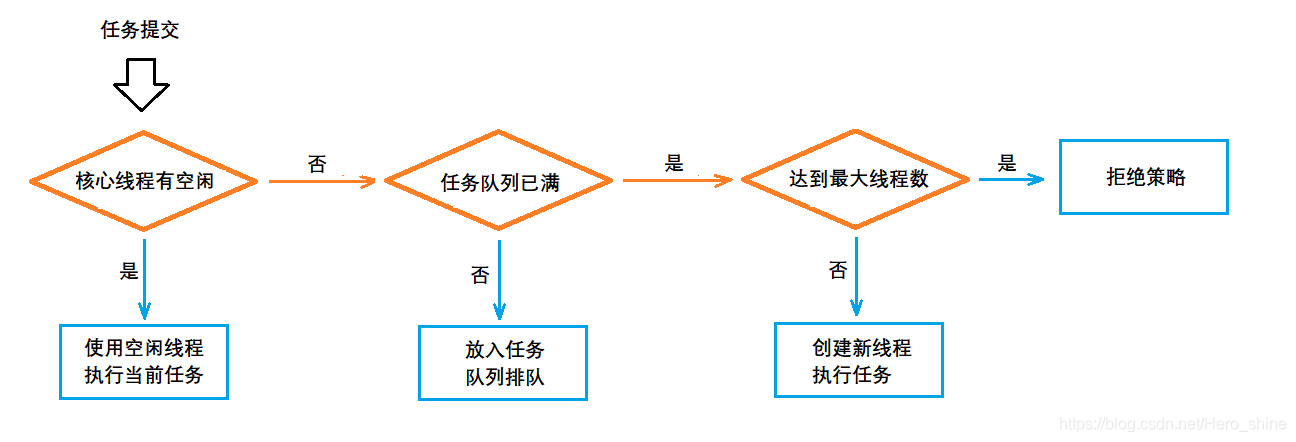
三、常用创建方式
先了解下线程池比较重要的几个参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) { }【int corePoolSize】核心线程数
【int maximumPoolSize】允许的最大线程数
【long keepAliveTime】空闲线程存活时间
【TimeUnit unit】keepAliveTime参数的时间单位
【BlockingQueue<Runnable> workQueue】任务队列,线程池达到了核心线程数,其他线程又是活跃状态,任务进入此队列
【ThreadFactory threadFactory】定制线程的创建过程
【RejectedExecutionHandler handler】拒绝策略, 当workQueue队满时,采取的措施
1.CachedThreadPool
调用ThreadPoolExecutor的构造,设置最大线程数为Integer最大值,无限制的线程池,理论上,如果其他线程均为活跃状态,并非空闲,只要接到任务需求,就会创建新线程,所以相对FixedThreadPool更快一点。
//源码
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}如何创建:
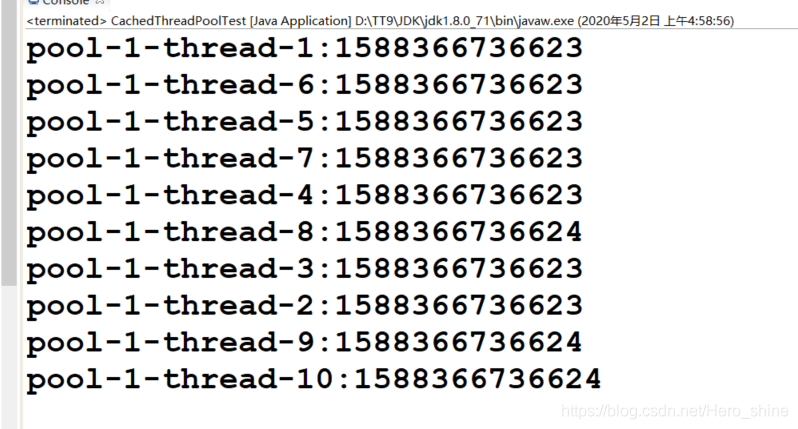
public class CachedThreadPoolTest {
public static void main(String[] args) {
ExecutorService cacheThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
cacheThreadPool.execute(new Runnable(){
@Override
public void run(){
System.out.println(Thread.currentThread().getName()
+ ":" + System.currentTimeMillis());
//每条线程执行至少10ms,则会创建10条线程
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}执行结果:
对比代码:
public class CachedThreadPoolTest {
public static void main(String[] args) {
ExecutorService cacheThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
cacheThreadPool.execute(new Runnable(){
@Override
public void run(){
System.out.println(Thread.currentThread().getName()
+ ":" + System.currentTimeMillis());
}
});
//循环启动十次任务,但线程已经执行完毕,一直是同一条线程执行任务
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}执行结果: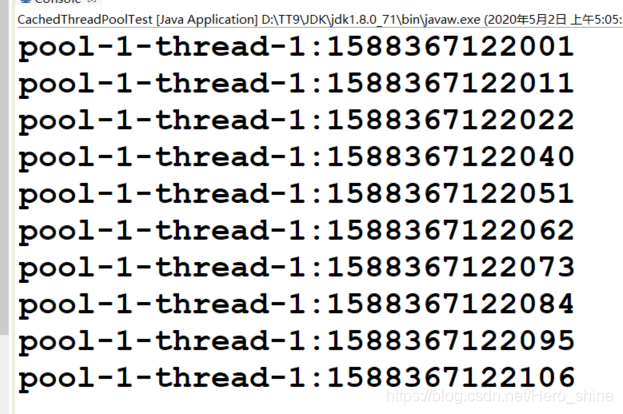
2.FixedThreadPool
启动固定线程数量的线程池,调用ThreadPoolExecutor的构造,将corePoolSize和maximumPoolSize设置相同值,使线程数量固定为给定参数值,空余线程等待时间设置为0,无界任务队列LinkedBlockingQueue,数量固定,即使没有任务,空闲的线程也不会被回收。
//源码
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}如何创建:
public class FixedThreadPoolTest {
public static final int FLAG = 15;
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
Future<?> result = newFixedThreadPool.submit(new Runnable(){
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+ ":" + FLAG);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}执行结果: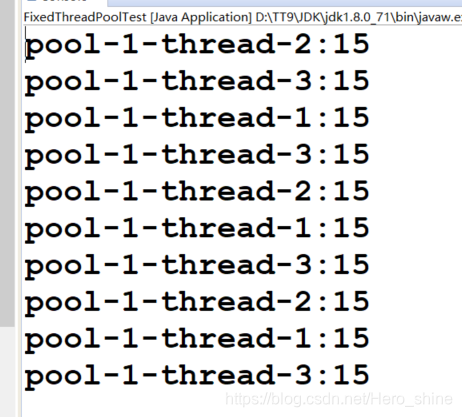
3. SingleThreadPool:
创建单一线程池:只有一条线程,调用ThreadPoolExecutor构造, 将coreThreadSize及maximumPoolSize设置为1,后续线程任务将在任务队列中排队。
//源码
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}如何创建:
public class SingleThreadPoolExecutor {
public static void main(String[] args) {
ExecutorService singleThreadPool = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
singleThreadPool.execute(new Runnable(){
@Override
public void run() {
System.out.println(Thread.currentThread().getName()
+ ":" + System.currentTimeMillis());
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
} 执行结果: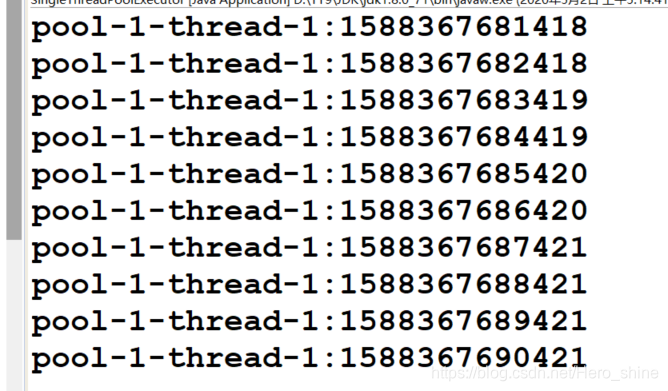
4.ScheduledThreadPool
可以实现延迟执行或定时执行任务。
如何创建延时任务
public class ScheduledThreadPoolTest {
public static void main(String[] args) {
ScheduledExecutorService scheduleExecutorService = Executors.newScheduledThreadPool(3);
//延时执行:
System.out.println(System.currentTimeMillis());
scheduleExecutorService.schedule(new Runnable(){
@Override
public void run() {
System.out.println(System.currentTimeMillis());
}
}, 3, TimeUnit.SECONDS);//延迟3秒执行
}执行结果:
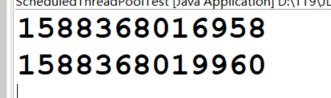
如何创建延时定时任务
public class ScheduledThreadPoolTest {
public static void main(String[] args) {
ScheduledExecutorService scheduleExecutorService = Executors.newScheduledThreadPool(3);
//延迟加定时执行
System.out.println(System.currentTimeMillis());
scheduleExecutorService.scheduleAtFixedRate(new Runnable(){
@Override
public void run() {
System.out.println(System.currentTimeMillis());
}
}, 1, 3, TimeUnit.SECONDS);//延迟1秒,每三秒执行一次
}
}执行结果:

5. ForkJoinPool
分段执行线程任务,多用于单个线程任务有参数限制,需要进行多段任务同时进行,以提高效率的情况。
代码演示:
public class ForkJoinPoolTest {
public static void main(String[] args) {
int[] arr = new int[120];
int total = 0;
for (int i = 0; i < arr.length; i++) {
arr[i] = (int)(Math.random()*20);
total += arr[i];
}
System.out.println("初始化120个数字累计和为:" + total);
ForkJoinPool forkJoinPool = new ForkJoinPool();
SumTask task = new SumTask(arr, 0, arr.length);
Future<Integer> future = forkJoinPool.submit(task);
try {
System.out.println("分段计算120个数字累计和为:" + future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
class SumTask extends RecursiveTask<Integer>{
private static final int THRESHOLD = 50;//最多允许计算50个数
private int[] arr;
private int start;
private int end;
public SumTask(int[] arr, int start, int end) {
this.arr = arr;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
Integer sum = 0;
if( end - start < THRESHOLD){
for (int i = start; i< end; i++) {
sum += arr[i];
}
return sum;
}else{
int middle = (end + start)/2;
SumTask left = new SumTask(arr,start,middle);
SumTask right = new SumTask(arr,middle,end);
left.fork();
right.fork();
return left.join() + right.join();
}
}
}执行结果:

6. WorkStealingPool
可以设置并行数量的线程池,不设置参数则默认为电脑的CPU线程数量。
如何创建:
public class WorkStealingPoolTest {
public static void main(String[] args) {
//设置并行数量为2,最多两个线程执行任务
ExecutorService workStealingPool = Executors.newWorkStealingPool(2);
for (int i = 0; i < 10; i++) {
final int count = i;
workStealingPool.submit(new Runnable(){
@Override
public void run() {
System.out.println(Thread.currentThread().getName()
+ "正在执行任务" + count + ",时间:"
+ System.currentTimeMillis());
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
//程序延迟10秒结束,以观察结果
try {
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}执行结果:

四、线程池内部任务队列
1.ArrayBlockingQueque:
基于数组实现的阻塞队列,内部维护了一个定长数组,以便缓存队列中的数据对象,内部还保存两个整形变量,在生产者生产数据和消费者获取数据的过程中,没有进行锁分离,用的是同一把锁,因此生产者和消费者无法并行,效率相对较低,在初始化时数组必须指定长度,即必须指定队列大小。
2.LinkedBlockingQueue:
无边界链式阻塞队列,用在【FixedThreadPool】及【SingleThreadPool】内部,其内部使用链表实现,因为生产者和消费者使用的是独立的锁对象,生产用的是【putLock】消费用的是【takeLock】,所以能够更加高效的处理并发数据,生产者和消费者可以并行操作队列中的数据,提高并发性能,初始化过程中可以不指定队列大小,默认是Integer最大值。
3.DelayedWorkQueue:
延时阻塞队列 ,用在【ScheduledThreadPool】内部,只有当延时的时间到了,才会从队列中获取元素,因此,再向队列中插入数据的操作(即生产者)永远不会被阻塞,只有消费者在获取数据的时候,可能被阻塞。
4.PriorityBlockingQueue:
基于优先级的阻塞队列,优先级通过传入的参数决定,该队列不会阻塞生产者,只有在消费者没有数据可以取的时候,阻塞消费者,因此,该队列的生产者插入数据的速度,必须小于消费者获取数据的速度,否则时间长会耗尽所有可用的堆内存,内部控制线程同步时,使用的是公平锁(FIFO-First Input First Output)。
5.SynchronousQueue:无缓冲等待队列,用在【CacheThreadPool】内部,没有容量,由内部类【SNode]】对象存储元素,必须等队列中的添加元素被消费者消费后才能继续添加新的元素。
五、关于拒绝策略
1.ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出【RejectExecutionException】异常(默认处理方式)
2.ThreadPoolExecutor.DiscardPolicy:丢弃任务,不抛出以常。
3.ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)。
4.ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务,即由主线程处理任务。
六、如何合理的分配线程数量
此内容来自一个声音亲切热心可爱的小姐姐,十分感谢
1.CPU密集型:一般指计算比较频繁的业务情况,【线程数量 = CPU核数 + 1】以减少线程上下文切换。
2.IO密集型:一般指查询操作比较频繁的业务情况,分两种,任务线程并不是一直都在执行任务,应尽可能多的配置线程数量,如【CPU核数 * 2 】,另一种,大部分线程均为阻塞状态,需要配置多一点的线程数,参考公式【CPU核数 / (1-阻塞系数)】,阻塞系数一般在【0.8~0.9】之间。

















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









