







 本文介绍了支持向量机的序列最小最优化(SMO)算法,详细阐述了问题引入、问题分析、代码实现以及总结。SMO算法通过解决一系列小优化问题来高效地求解大规模样本的凸二次规划问题。文章提供了简化版和启发式规则优化版的Python代码实现,展示了不同C值下决策边界的可视化效果,强调了算法优化对于处理大数据集的重要性。
本文介绍了支持向量机的序列最小最优化(SMO)算法,详细阐述了问题引入、问题分析、代码实现以及总结。SMO算法通过解决一系列小优化问题来高效地求解大规模样本的凸二次规划问题。文章提供了简化版和启发式规则优化版的Python代码实现,展示了不同C值下决策边界的可视化效果,强调了算法优化对于处理大数据集的重要性。
一、问题引入
上篇博文我们已经把支持向量机的学习问题化为求解凸二次规划问题,并求出了它的最优解。但是当训练样本容量很大时,使用二次规划的算法往往变得非常低效,以致无法使用。因此,我们需要实现一个高效的支持向量机学习算法。John Platt提出的序列最小最优化(SMO)算法便是这些高效算法中的一种。SMO算法是一种启发式算法,它将原优化问题分解为多个小优化问题来求解,并且对这些小优化问题进行顺序求解得到的结果作为作为整体的结果,有些动态规划的思想。
二、问题分析
以下只把算法列出,不予证明。证明过程可查看John Platte的相关论文或《统计学习方法》。
SMO算法要求解的问题是:
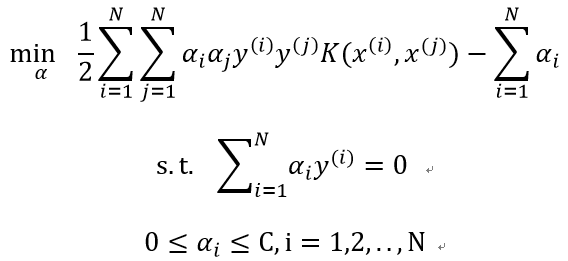
其子问题可以写成:
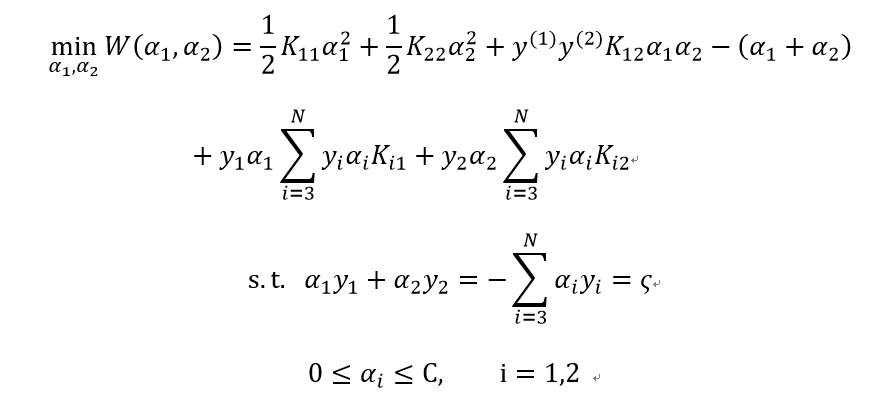
为了叙述方便,记:
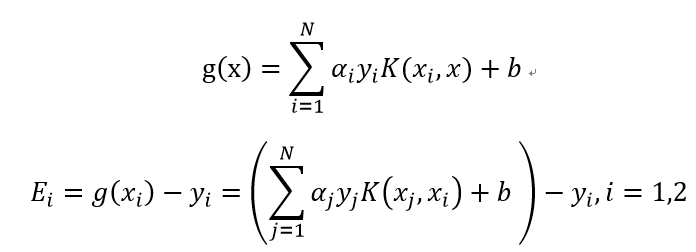
子问题未经约束的解是:
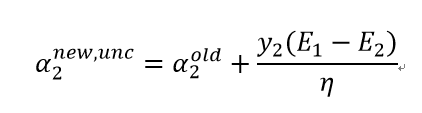
其中:
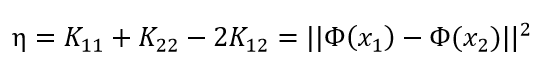
经约束后的解是:
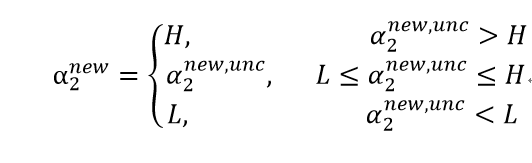
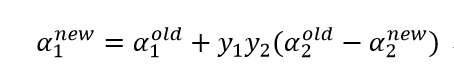
其中:
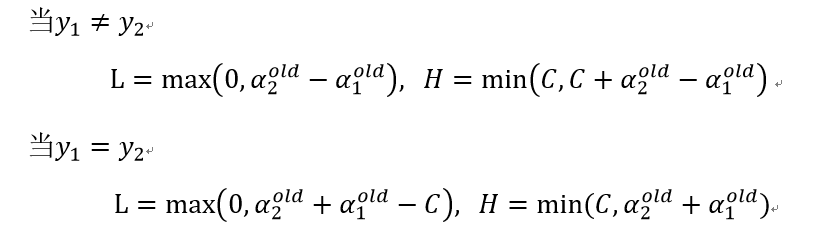
变量的选择步骤如下:
(1)启发式策略1:第一个变量的选择为外层循环,先选取违反KKT条件最严重的样本点,KKT条件即:
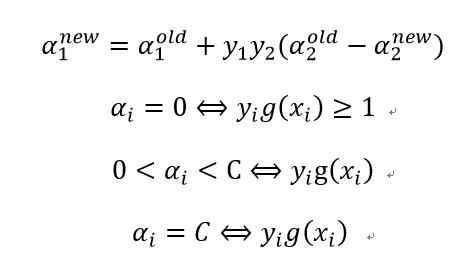
再用“启发式策略2”选择另外一个变量并进行这两个变量的优化(之所以选择非边界样本是为了提高找到违反KKT条件的点的机会),最后,如果上述非边界样本中没有违反KKT条件的样本,则再从整个样本中去找,直到所有样本中没有需要改变的变量或者满足其它停止条件为止。
(2)启发式策略2:第二个变量的选择为内层循环,为了加快α2的迭代速度,应使其对应的|E1-E2|最大。
(3)计算阈值b:
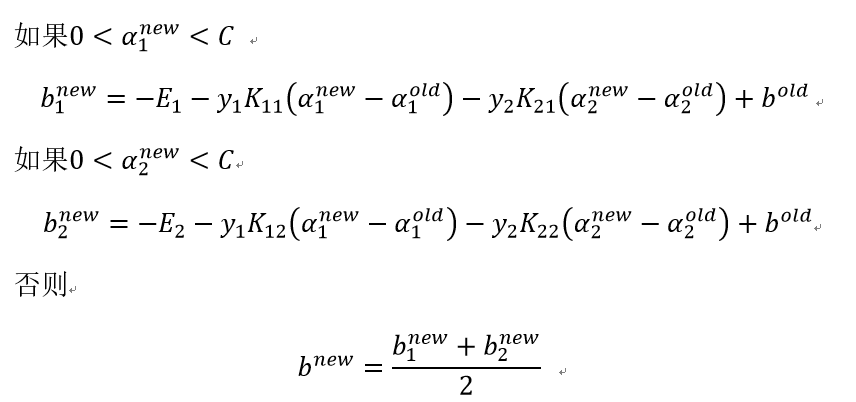
三、代码实现(Python)
1.简化版
此算法实现时的内层循环采用随机选择的方式,未使用启发式规则。
(1)主算法实现
# 随机选择一个不等于i的j
def selectJrand(i,m):
j = i
while (j == i):
j = int(random.uniform(0,m))
return j
# 上下界约束
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
# 主算法
# 输入参数:训练数据集、类别标签(y)、惩罚参数C、容错率、最大迭代次数
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose()
b = 0; m,n = shape(dataMatrix)
alphas = mat(zeros((m,1)))
iter = 0 # 迭代次数
while (iter < maxIter):
alphaPairsChanged = 0
for i in range(m):
gXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b # 计算g(xi)
Ei = gXi - float(labelMat[i])
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):# 检查是否满足KKT条件
j = selectJrand(i,m) # 随机选择第二个变量
gXj = float(multiply(alphas,labelMat).T * (dataMatrix*dataMatrix[j,:].T)) + b
Ej = gXj - float(labelMat[j])
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
if (labelMat[i] != labelMat[j]): # 计算约束上下界
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3776
3776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









