







 本文介绍了无监督学习中的k-means聚类算法,详细阐述了算法流程、目标函数和收敛性,并提供了Matlab及Python的实现示例。k-means在数据挖掘和市场细分等领域广泛应用,但可能陷入局部最优,二分k-means作为优化策略,通过不断划分降低误差平方和,提升聚类质量。
本文介绍了无监督学习中的k-means聚类算法,详细阐述了算法流程、目标函数和收敛性,并提供了Matlab及Python的实现示例。k-means在数据挖掘和市场细分等领域广泛应用,但可能陷入局部最优,二分k-means作为优化策略,通过不断划分降低误差平方和,提升聚类质量。
前言:从现在开始要开始一个新的话题了——无监督学习(Unsupervised Learning)。前面讲的学习方法都属于有监督学习。它们的共同特点是:训练数据的输入和输出都是明确的。比如在预测房价的线性回归模型中,训练数据中的房屋面积和房价都是已知的,我们的任务是建立一个模型使得有新的输入时作出预测。同样地,在分类问题中,训练数据中的特征向量和分类标签都是已经给出的,任务也是相同的。回归与分类问题的区别只是在于它们建立的模型是连续或者离散的。而在本文即将介绍的聚类分析就属于典型的无监督学习问题——训练数据没有任何标记,我们的任务是挖掘这些数据中隐藏的结构。聚类有时也会被称为无监督分类,应用非常广泛。举几个例子,对顾客行为进行聚类可以把市场分为几个不同的几个部分,针对不同的顾客可以采用不同的销售策略;在Google的新闻首页,对新闻进行聚类,使得描述同一事件的报道不全部显示;在图片分割中,可以利用图片不同部分的相似度来理解图片信息等。下面对其中一种比较简单的聚类算法——k-means进行介绍。
一、问题引入
k-mean算法的核心思想是簇识别。假定有一些数据,把相似数据归到一起,簇识别会告诉我们这些簇到底是什么,簇的个数是用户给定的,每一个簇都有一个心脏——聚类中心,也叫质心(centroid)。聚类与分类的最大不同是,分类的目标事先已知,而聚类则是,我们不知道分类标签是什么,根据相似度来给数据贴上不同的标签。相似度的度量最常用的是欧氏距离。
二、问题分析
1.k-means算法的基本流程如下:
给定输入训练数据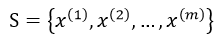
(1) 选择初始的k个聚类中心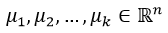
(2)对每个样本数据,将其类别标号设为距离其最近的聚类中心的标号,即:
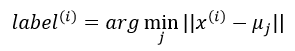
(3)将每个聚类中心的值跟新为与该类别中心相同类别的所有样本的平均值,即:
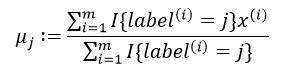
(4)重复第(2)步和第(3)步,直到算法收敛为止,此时聚类中心不会再移动。
2.算法的收敛性
对于k-means来说,它要优化的目标函数可以看成以下形式:
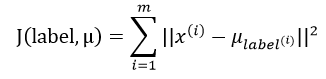
由于此式不是凸函数,因此不能保证算法会收敛到一个全局最优值,只能保证收敛到一个局部最优值。解决这个问题有两种方法:一是随机初始化多次,以最优的聚类结果为最终结果;二是下文将要介绍二分k-means算法。
三、代码实现
1.普通k-means算法(Matlab):
(1)导入数据并绘图:
%% 导入数据
X = load('testSet.txt')
%% 画出原始数据散点图
figure(1);hold off
plot(X(:,1),X(:,2),'ko');绘制效果如下:
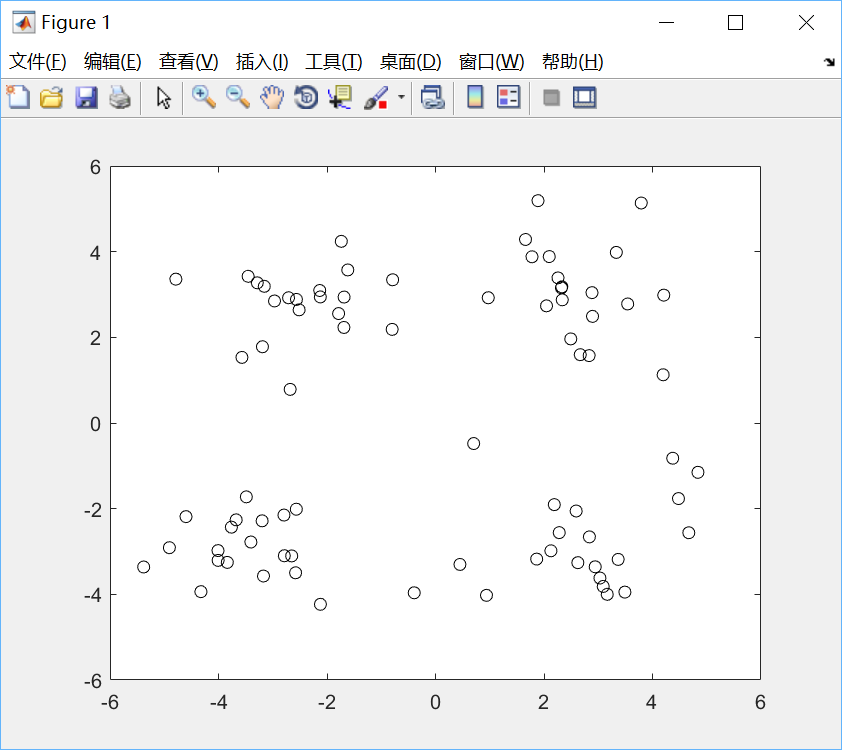
可见图中的数据点都是没有类别标签的。
(2)主算法:
%% 随机初始化均值
K = 4; % 簇的数量
cluster_means = rand(K,2)*10-5;
%% 为每个样本点分配一个簇,并更新均值
converged = 0; % 算法收敛标志
N = size(X,1);
cluster_assignments = zeros(N,K);
distances = zeros(N,K);
colors = {
'r','g','b','y'};
while ~converged
for k = 1:K
distances(:,k) = sum((X - repmat(cluster_means(k,:),N,1)).^2, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7065
7065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









