







一楼放图
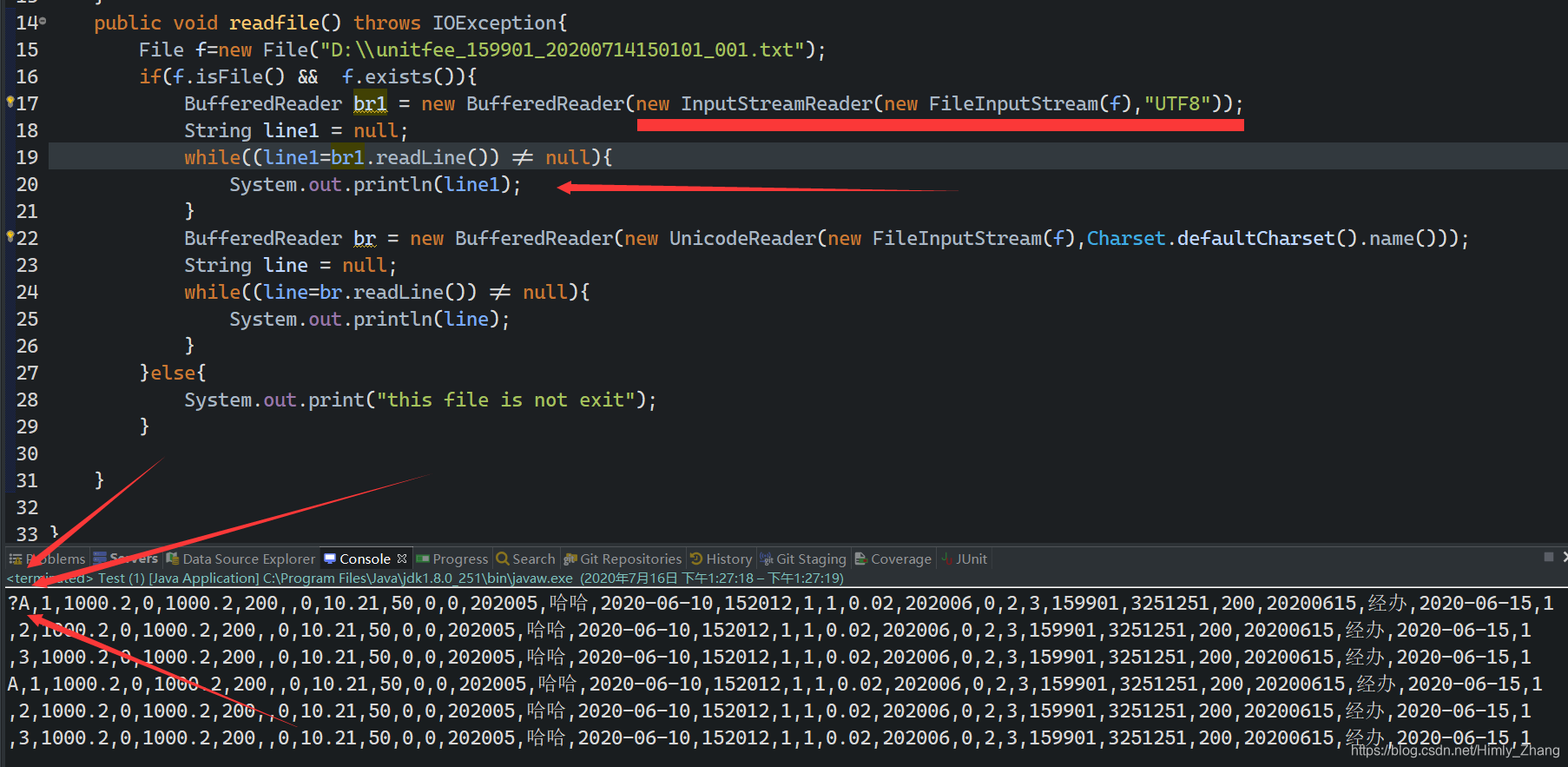
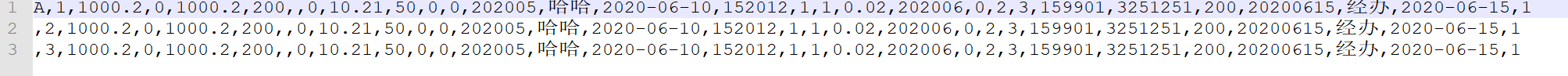
以上是用java做一个简单的文件读取,在TXT中,我们的第一个字明明是A,但是打印的结果,确是一个问号。
发现问题
首先文件是UTF8格式,我们确定读取时候设置的格式无错,那我们检查一下NOTEPAD++文本编辑器中,的编码格式。显示当前文本格式为UTF8,
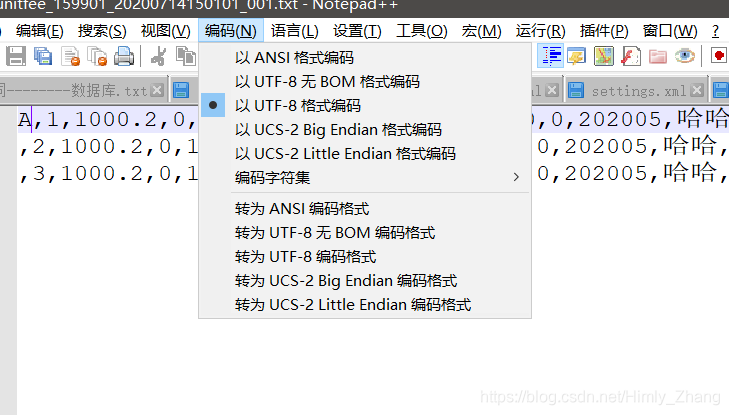
当然我们还发现,里面有一个选项是以UTF8-无BOM格式编码。经过尝试,当我们文件以UTF8无BOM时候编码时候,文件读取结果正常。那么我们可以肯定,问题是处在这个BOM上。那么我们对BOM到底是干啥的,给一个详细的解释。
编码格式说明
首先明确一下BOM-即BYTE ORDER MARK,就是字节的顺序,那么我们常见的UTF8格式,他是以1个字节为单元进行数据存储的,那么我们想知道下一位的时候,只要当前地址+1,即可。
而UTF16,UTF32分别是以2个和4个字节为单元进行数据存储的。这样在传输或者存储过程中,我们就要考虑字节的顺序问题,很显然,UTF16,UTF32在这一点上有区别于UTF8。
那么在计算机处理文本的时候,他要知道这个文件到底是UTF8,还是UTF16还是UTF32,来确定每次的读取单元和顺序。所以就不得不给UTF8前面也加个帽子。
其实这个BOM对UTF8什么用都没有,因为一次默认读1个单元,又与顺序无关。
代码说明
接下来用过代码来更好的解释一下,计算机的读取过程。
首先,BOM有4byte,每个byte都可对标记进行存储。
package com.sunreal.test;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PushbackInputStream;
import java.io.Reader;
public class UnicodeReader extends Reader {
PushbackInputStream internalIn;
InputStreamReader internalIn2 = null;
String defaultEnc;
private static final int BOM_SIZE = 4;
UnicodeReader(InputStream in, String defaultEnc) {
internalIn = new PushbackInputStream(in, BOM_SIZE);
this.defaultEnc = defaultEnc;
}
UnicodeReader(InputStream in) {
internalIn = new PushbackInputStream(in, BOM_SIZE);
}
public String getDefaultEncoding( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









