









Spark各种架构和提交方式的组合
-
Spark on Yarn架构+Client提交模式
spark-submit --master yarn-client --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.
0-hadoop2.6.0.jar 10
或者
spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.
0-hadoop2.6.0.jar 10
-
Spark on Yarn架构+Cluster提交模式
spark-submit --master yarn-cluster --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.
0-hadoop2.6.0.jar 10
或者
spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.
0-hadoop2.6.0.jar 10
-
Spark Master HA架构+Client提交模式
spark-submit --master spark://faith-Fedora:7077,faith-Ubuntu:7077,faith-openSUSE:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.0-hadoop2.6.0.jar 10
-
Spark Master HA架构+Cluster提交模式
spark-submit --master spark://faith-Fedora:7077,faith-Ubuntu:7077,faith-openSUSE:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi spark-1.6.0/lib/spark-examples-1.6.0-hadoop2.6.0.jar 10
-
这四种方式的注意事项
-
spark-env.sh的HADOOP_CONF_DIR属性
-
当启用了Spark的History Server日志功能之后,由于Spark需要将日志存储在HDFS的目录上,所以Spark需要知道HDFS的地址,例如:hdfs://mycluster/...所以需要在spark-env.sh上配置HADOOP_CONF_DIR属性,如下:

现在的问题是,这个配置项在哪个节点上配置??
-
master HA + cluster,由于这种模式下Driver进程有Master进程在资源充足的Worker节点中随机选取一台Worker节点启动Driver进程,所以如果Driver进程所在节点没有配置spark-env.sh的话,将抛出异常。

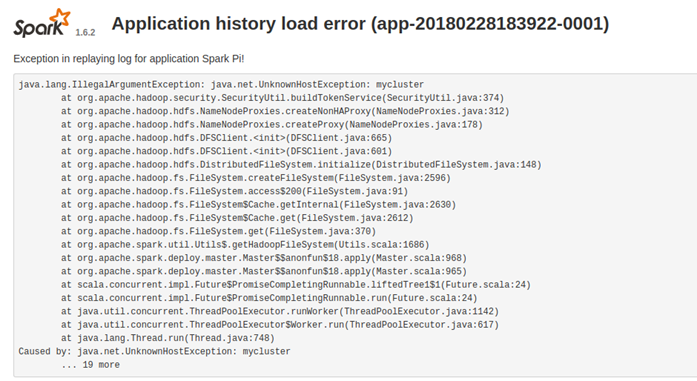
-
master HA client模式下,只需要配置Spark Client节点的spark-env.sh文件即可:

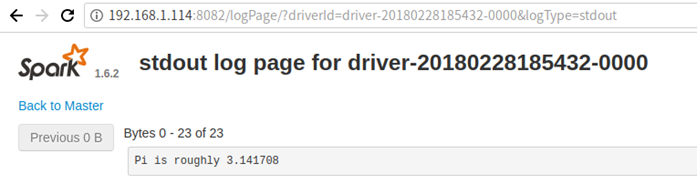
-
yarn+client
如果使用yarn+client、yarn+cluster这两种yarn的架构之下。由于使用的是yarn资源调度框架,而yarn本身隶属于Hadoop的一部分,集群会知道HADOOP_CONF_DIR在哪里。所以不用配置。

client提交方式可以直接在命令行看结果
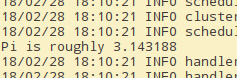
-
yarn+cluster

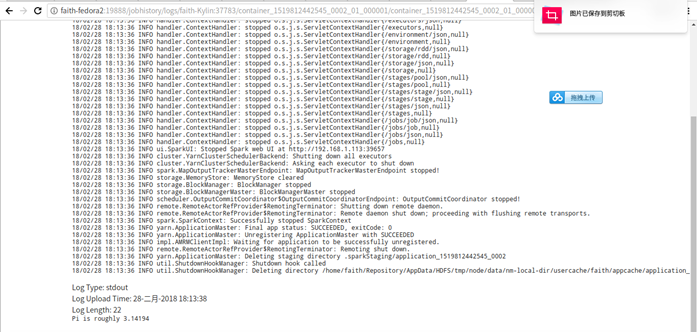















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









