










SparkStreaming并行度属性设置

spark.streaming.blockInterval:该属性是对BatchInterval的进一步细化切分。将一个BatchInterval的数据喜欢切分成更小的block,一个block对应一个Spark Partition。
BatchInterval的数据对应RDD
blockInterval的数据对应RDD中的Partition
所以SparkStreaming中Partition的数量公式如下:
Partition个数 = BatchInterval / blockInterval
建议:blockInterval的大小不要小于50ms,如果数据太小,那么处理数据所花费的时间远远小于启动一个线程所需要的时间,那么相当于使用大炮打蚊子。
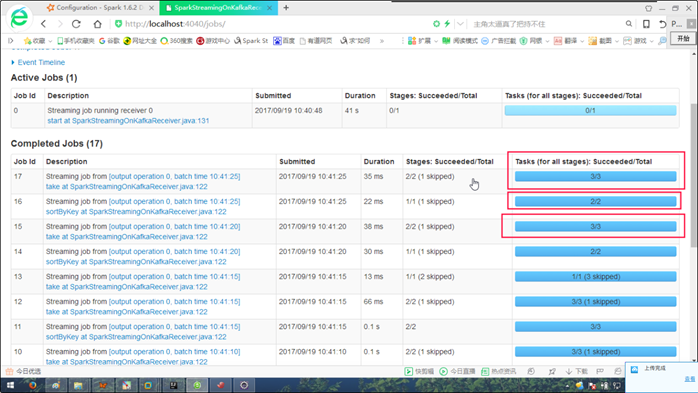
默认情况下,blockInterval = 200ms,如果BatchInterval = 5s,那么Partition个数 = BatchInterval / blockInterval = 25,也就是有25个Partition,但是当一个BatchInterval中数据过少,例如只有<25个数的数据,那么是分不成25个Partition的,如下图,只有3个,有时只2个Partition。















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









