









MR History Server与Spark History Server
MR History与Spark History Server不是一个东西
Hadoop提供的History Server是MR的,不是Yarn的
参考:http://blog.csdn.net/cymvp/article/details/52090348
由于MR是Hadoop的默认计算框架,所以YARN的history server只是针对MR的。而由于YARN是一个通用的资源调度平台,所以YARN无法针对其他计算框架例如Spark记录日志。
Spark具有自己的History Server。
很多文章也是混淆概念的。
MR History Server配置
-
版本:Hadoop-2.x
-
集群规划
faith-Fedora
faith-Ubuntu
faith-openSUSE
faith-Kylin
faith-Mint
faith-Fedora2
zk
zk1
√
zk2
√
zk3
√
Hadoop
NN1
√
NN2
√
JN1
√
JN2
√
JN3
√
DN1
√
DN2
√
DN2
√
ZKFC1
√
ZKFC2
√
Spark
Client
√
MR History Server
√
-
配置mapred-site.xml文件
-
只需要在yarn集群的相关节点上配置这些参数就可以了也就是faith-openSUSE、faith-Kylin、faith-Mint、faith-Fedora2四个节点上。
faith-openSUSE、faith-Kylin、faith-Mint分别是NodeManager节点,所以需要配置
faith-Kylin、faith-Mint分别是ResourceManager节点,所以需要配置
faith-Fedora2:作为History Server节点和yarn timeline server节点,所以需要配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- History Server的地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>faith-Fedora2:10020</value>
</property>
<!-- History Server的WebUI地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>faith-Fedora2:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>1000</value>
<description>default 20000</description>
</property>
<property>
<name>mapreduce.jobhistory.cleaner.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.cleaner.interval-ms</name>
<value>86400000</value>
<description>the job history cleaner checks for files to delete, in milliseconds. Default 86400000 (one day). Files are only deleted if they are older than</description>
</property>
<property>
<name>mapreduce.jobhistory.max-age-ms</name>
<value>432000000</value>
<description>Job history files older than this many milliseconds will be deleted when the history cleaner runs. Defaults to 604800000 (1 week)</description>
</property>
<!-- 存放MR日志的目录 -->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/tmp/hadoop-yarn/staging</value>
</property>
<!-- 存放MR运行过程中的日志目录 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
</property>
<!-- 存放MR运行完成日志的最终目录 -->
<property>
<name>mapreduce.jobhistory.done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
</property>
以我的机器为例,日志目录为
hdfs://mycluster:8020/tmp/hadoop-yarn/staging/history/done_intermediate
hdfs://mycluster:8020/tmp/hadoop-yarn/staging/history/done
-
配置yarn日志聚合,spark-site.xml
yarn的NodeManager节点是和DataNode节点在同一台服务器上的。而应用提交到yarn上之后,会在NodeManager节点启动Container进程,默认情况下,Container/任务日志记录在NodeManager节点上,这样一个应用的日志实际上是分散在各个NodeManager节点上的。
日志聚合功能是Yarn提供的日志中央化管理功能,它能将运行完成的Container/任务日志上传到HDFS上,从而减轻NodeManager负载,并且提供一个中央化的存储和分析机制。
在yarn-site.xml文件中添加如下内容
<!-- 启用日志聚合功能,默认值false -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 在HDFS上聚合的日志最多保存多长时间,默认值:-1,即永久保存 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>-1</value>
</property>
<!-- 多长时间检查一次HDFS上聚合的日志,并将满足yarn.log-aggregation.retain-seconds这个参数的条件的日志删除掉,如果yarn.log-aggregation.retain-check-interval-seconds设置为0或者负数,则每隔yarn.log-aggregation.retain-seconds时间的1/10检查一次,如果yarn.log-aggregation.retain-seconds设置为负数,那么永远不检查 -->
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>-1</value>
</property>
<!-- 当应用程序运行结束后,日志被转移到的HDFS目录(启用日志聚合后该参数生效),默认值/tmp/logs -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/yarn/log</value>
</property>
<!--
聚合日志目录的子目录名称(开启聚合日志后该参数生效),默认值:${yarn.nodemanager.remote-app-log-dir}/${user}/${thisParam}下
mapreduce.jobhistory.intermediate-done-dir和mapreduce.jobhistory.done-dir的含义应该是聚合之前的日志存放目录,yarn.nodemanager.remote-app-log-dir和yarn.nodemanager.remote-app-log-dir-suffix定义的应该是聚合后日志的目录
-->
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>nodemanagerlog</value> </property>
<!-- MR History Server的webUI地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://faith-fedora2:19888/jobhistory/logs</value>
</property>
yarn.log.server.url的配置的含义是,点下面按钮时候跳转到该地址

-
启动MR History Server
-
启动History Server
-
根据集群规划,在faith-Fedora2节点上启动
~/Repository/Programs/hadoop-2.6.5/sbin/mr-jobhistory-daemon.sh start historyserver
~/Repository/Programs/hadoop-2.6.5/sbin/yarn-daemon.sh start timelineserver
-
查看History Server进程
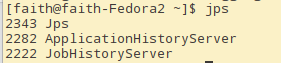
-
测试聚合日志
-
使用Hive(MR计算引擎)测试
-
hive的计算引擎可以说MR,也可以是spark。我们这里配置hive的引擎是MR,这样就可以看到MR的日志了。
在faith-Fedora节点上启动hive

在faith-Ubuntu节点上启动hive的client,并且执行一个可以产生MR的SQL语句
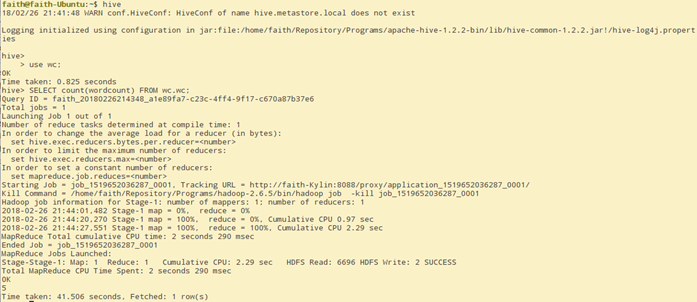
-
查看日志
先看yarn的日志

点击history,跳转到http://faith-fedora2:19888/jobhistory/job/job_1519652036287_0001
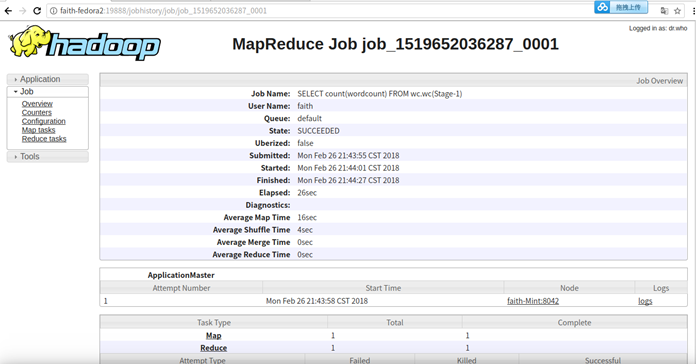
-
关闭MR History Server和yarn的timelineserver


配置Spark的History Server
-
集群规划
-
参考上面的集群配置,由于这个架构是spark on yarn架构,所以资源调度框架是yarn,spark只起到计算框架的作用,所以实际上,spark只需要安装在faith-Fedora2节点上,其他节点根本不需要安装spark。
-
修改faith-Fedora2节点上的spark-defaults.conf
# 是否记录Spark事件,用于应用程序在完成之后重构webUI,默认值false
spark.eventLog.enabled true
# 保存日志相关信息的路径,可以使hdfs://开头的HFDS路径,也可以是file://开头的本地路径,都需要提前创建,默认值:file://tmp/spark-events
spark.eventLog.dir hdfs://mycluster/spark/history/fs/logDirectory
# 是否压缩记录spark事件,前提spark.eventLog.enabled为true,默认使用的是snappy,默认值:false
spark.eventLog.compress true
-
修改faith-Fedora2节点上的spark-env.sh

spark.history.ui.port=18080 HistoryServer的webUI端口,默认值18080
spark.history.retainedApplications=3 保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,默认值250
spark.history.fs.logDirectory spark历史日志存储路径
-
spark.eventLog.dir和spark.history.fs.logDirectory的区别
原创 2017年02月25日 22:13:18
-
2123
spark.eventLog.dir是记录Spark事件的基本目录,如果spark.eventLog.enabled为true。 在此基本目录中,Spark为每个应用程序创建一个子目录,并在此目录中记录特定于应用程序的事件。用户可能希望将其设置为统一位置,如HDFS目录,以便历史记录服务器可以读取历史记录文件。
spark.history.fs.logDirectory用于为历史记录程序提供文件系统,包含要加载的应用程序事件日志的目录URL。 这可以是本地文件路径file://路径,HDFS路径hdfs://namenode:port /shared/spark-logs或Hadoop API支持的备用文件系统的路径。
spark.eventLog.dir用于生成日志,spark.history.fs.logDirectory是Spark History Server发现日志事件的位置。
但是这两个目录应该配置成相同的路径,如果不同,则History Server的WebUI上查询不到日志。
-
启动Spark History Server
在faith-Fedora2节点上启动start-history-server.sh(spark on yarn架构下,在其他节点上根本没有spark,之后faith-Fedora2节点上有spark程序)
-
spark on yarn(Client提交模式)

在这种模式下,Dirver进程是在Client服务器上执行的(client服务器就是faith-Fedora2),所以在命令行是可以看到执行结果的。

-
spark on yarn(Cluster提交模式)

在这种模式下,Driver进程是随机在一个NodeManager节点上启动的,所以无法在命令行看到执行结果,只能到webUI的ApplicationMaster节点上看。
-
在webUI上查看spark history server
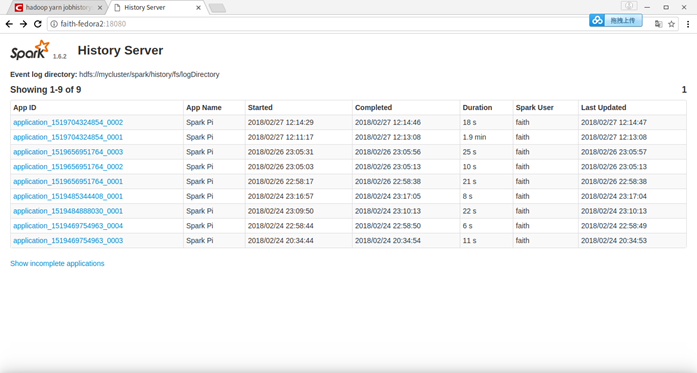
选择第一个Application,进去
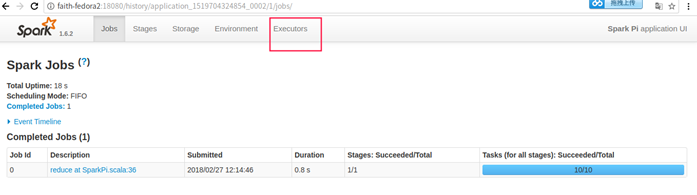
点击Executors标签页进入:
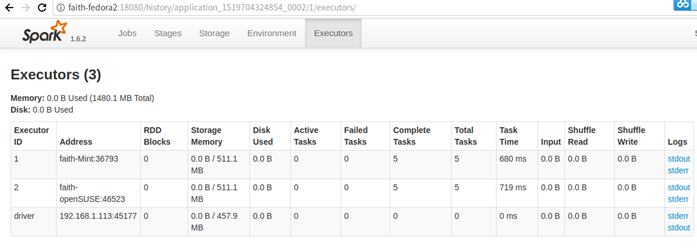
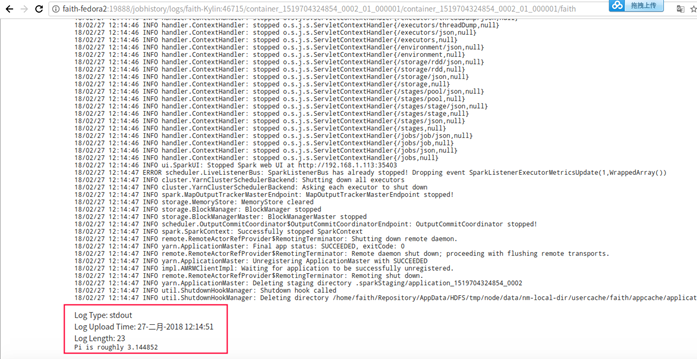
然后点击stdout、stderr等连接,页面就转到了MR 的History Server界面——faith-fedora2:19888地址。这就是在yarn-site.xml中配置了yarn.log.server.url的原因。
点击Driver的stderr,可以看到Pi的输出结果。
-
停止Spark History Server
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









