






(1)报告正文总标题宋体三号字加粗,单行间距,段前、段后选择自动间距;
(2)报告中一级标题采用黑体小三号字;
(3)二级标题黑体四号字;
(4)其他标题及正文均用宋体小四号字。
(5)摘要、参考文献等名称均用黑体四号字,内容为宋体小四号字。行间距1.25倍,段前间距0.5行。
(6)文中图表标题用宋体小四号字,表格内文字一般用宋体小四号或五号字,单行间距。
忌用异体字、复合字及一切不规范的简化字,除非必要,不使用繁体字。
(7)上下边距为2.54厘米,左右边距为3.18厘米。
(8)报告主体内容要简洁、明确,层次不宜过多,层次序号为:一、;(一);1.; (1);1)。
(9)数字用法:凡是公历世纪、年代、年、月、日、时刻、各种记数、计量均用阿拉伯数字;夏历和清代以前的历史纪年用汉字,并以圆括号加注公元纪年;邻近的两个数字并列连用以表示的概数,采用汉字。
(10)文中图表等:文中的图表、附录、参考文献、公式一律采用阿拉伯数字连续编号。如图1,表1,附注1,公式(1)。图序及图题置于图的下方居中,表序及表题置于表的上方居中,图序和图题之间、表序和表题之间空两格。论文中的公式编号用圆括号括起来写在右边行末,其间不加虚线。
(11)参考文献:对引文作者、出处、版本等详细情况的注明。
模板已设置好三线表,自动设置/更新图表名称,公式制表位编辑,目录自动更新等内容,还包含了本人当时的写作框架,不知道正大杯文字怎么写的可以入手了
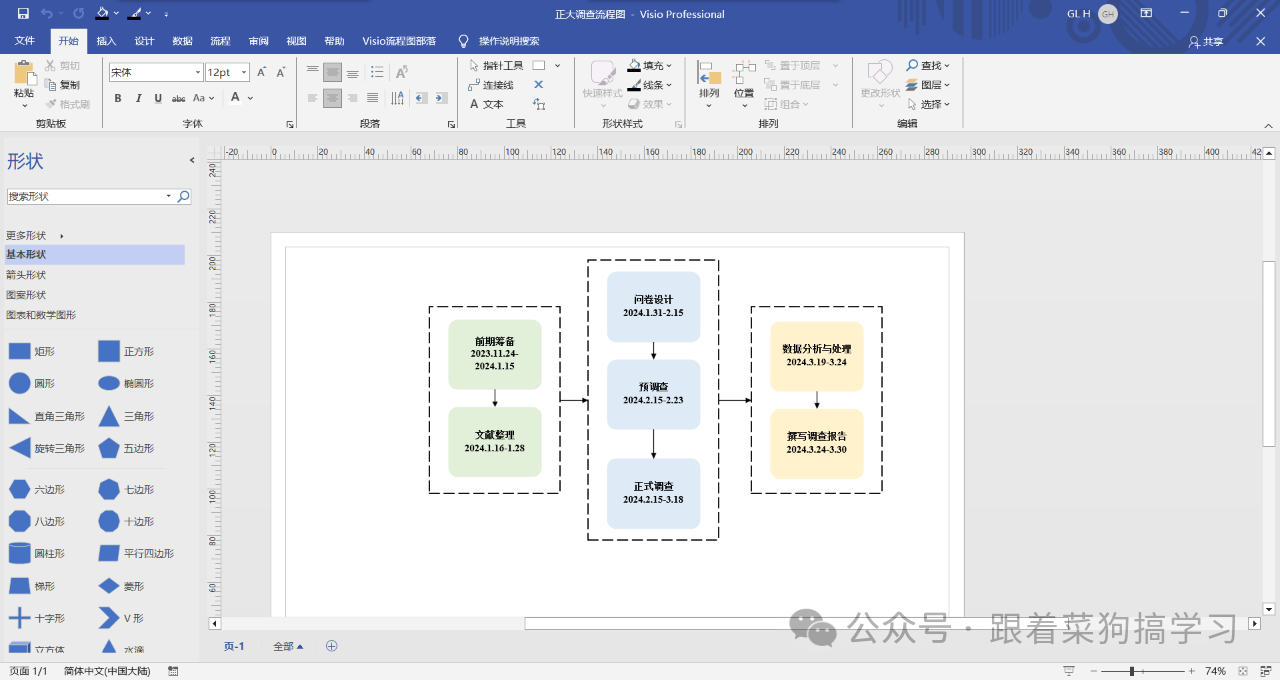
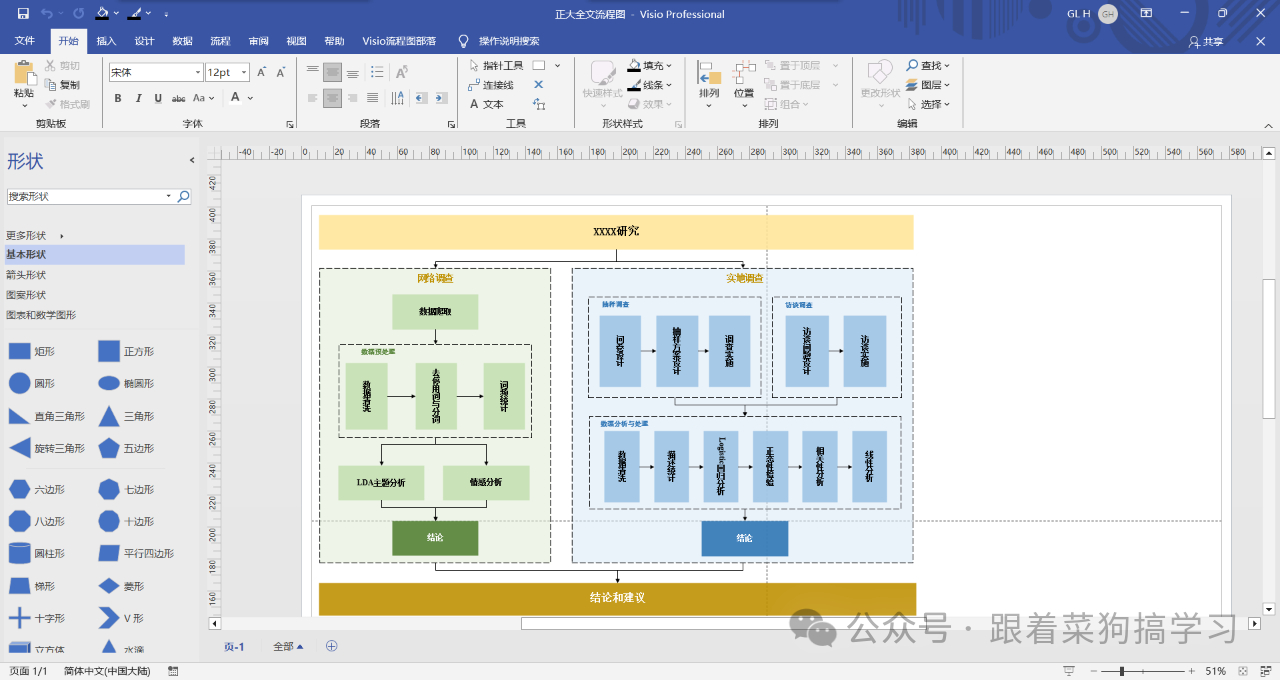
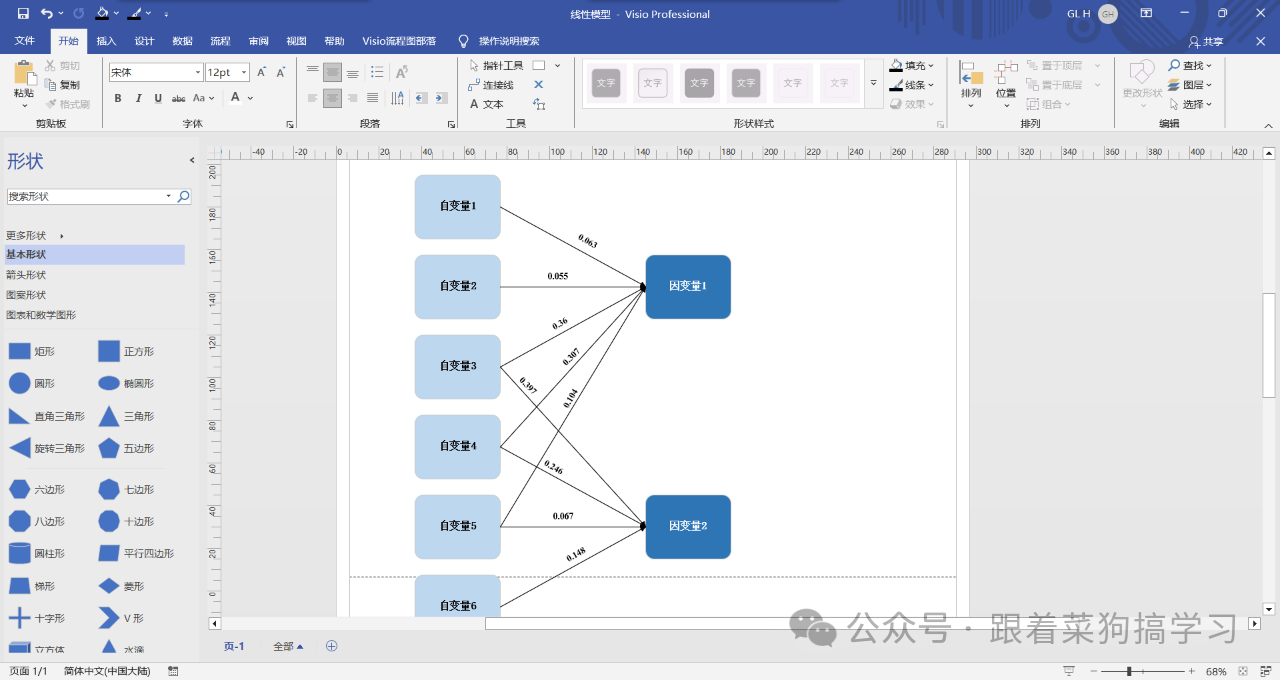
流程图模板包括,全文流程图模板,调查流程图模板,线性结构模板,都可直接套用(Visio版,可直接在在线流程图网站Process on中打开)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









