







目录
一、基本介绍
1)Hadoop 是一个由Apache基金会所开发的分布式系统基础架构
注:分布式是指多个服务器完成某一项任务
2)主要用来解决海量数据的存储和海量数据的分析计算问题
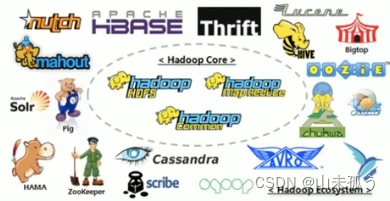
3)广义上来说,Hadoop通常是指Hadoop生态圈
二、发展历史(百度百科)
Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一 。2004年,Google在“操作系统设计与实现”会议上公开发表了题为《Mapreduce:简化大规模集群上的数据处理》的论文之后

受到启发的Doug Cutting等人开始尝试
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2991
2991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









