 Python用PaddleOCR识别图片文字并处理
Python用PaddleOCR识别图片文字并处理




Python 使用PaddleOCR引擎识别图片内容,提取图片文字并格式化智能文本处理

1、功能概述
系统基于PaddleOCR引擎开发,为图像的全自动文本识别与结构化处理。系统通过五级智能格式化规则,将原始OCR识别结果转换为符合行业规范的结构化数据。
- 特殊符号统一化(
+→+) - 纤维成分与百分比智能分隔(
Cotton95%→Cotton 95%) - 复合成分格式优化(
Nylon+Polyester→Nylon + Polyester) - 计量单位标准化(
210g/m²→210 g/m²) - 冗余空格清理与格式美化
2、环境准备 基础依赖安装
pip install paddleocr tqdm opencv-python
3、目录结构
input_images/ # 待处理图像存放目录
processed_results/ # 处理结果输出目录
├── original_images # 原始文件备份
└── {filename}_result.txt # 结构化结果文件
4、执行流程
1、将待处理图像放入input_images目录
2、运行主程序:
python formatting_content.py
5、代码运行
import re
import logging
from pathlib import Path
from paddleocr import PaddleOCR
from tqdm import tqdm
# ---------------------------
# 文本格式化模块(必须定义)
# ---------------------------
class TextFormatter:
@staticmethod
def format_composition(text):
"""五级文本格式化规则"""
text = text.replace('+', '+').replace('/', '/')
text = re.sub(r'(\d+%)([A-Z\u4e00-\u9fa5])', r'\1 \2', text)
text = re.sub(r'([A-Z\u4e00-\u9fa5])(\d+%)', r'\1 \2', text)
text = re.sub(r'([%A-Za-z\u4e00-\u9fa5])([+/])([A-Za-z\u4e00-\u9fa5])', r'\1 \2 \3', text)
text = re.sub(r'([A-Za-z\u4e00-\u9fa5]+)(\d)', r'\1 \2', text)
text = re.sub(r'(\d)(g/m[²]?)', r'\1 \2', text, flags=re.IGNORECASE)
text = re.sub(r'\s+', ' ', text)
text = re.sub(r'(\s?[+/]\s?)', lambda m: f' {m.group().strip()} ', text)
return text.strip()
# ---------------------------
# OCR处理核心
# ---------------------------
class OCRProcessor:
def __init__(self):
self.ocr = PaddleOCR(
use_angle_cls=True,
lang='ch',
use_gpu=False,
show_log=False # 关闭PaddleOCR的DEBUG日志
)
def process_image(self, image_path):
try:
result = self.ocr.ocr(str(image_path), cls=True)
if not result or not result[0]:
raise ValueError("未识别到有效文本")
raw_text = " ".join([line[1][0] for line in result[0] if line and line[1]])
formatted = TextFormatter.format_composition(raw_text) # 正确调用格式化类
print(f"\n📄 文件: {image_path.name}")
print(f"🔍 原始识别: {raw_text}")
print(f"✨ 格式化后: {formatted}")
print("━" * 60)
return formatted
except Exception as e:
print(f"\n❌ 处理失败: {image_path.name} - {str(e)}")
return None
# ---------------------------
# 主程序
# ---------------------------
def main():
input_dir = Path("./input_images")
if not input_dir.exists():
print("❌ 输入目录不存在!")
return
image_files = [f for f in input_dir.glob('*') if f.suffix.lower() in ('.jpg', '.jpeg', '.png')]
if not image_files:
print("❌ 未找到图片文件!")
return
processor = OCRProcessor()
with tqdm(total=len(image_files), desc="🚀 处理进度", bar_format="{l_bar}{bar:20}{r_bar}") as pbar:
for img in image_files:
processor.process_image(img)
pbar.update(1)
print("\n✅ 处理完成!所有结果已输出至终端")
if __name__ == "__main__":
main()
6、输出结果比对
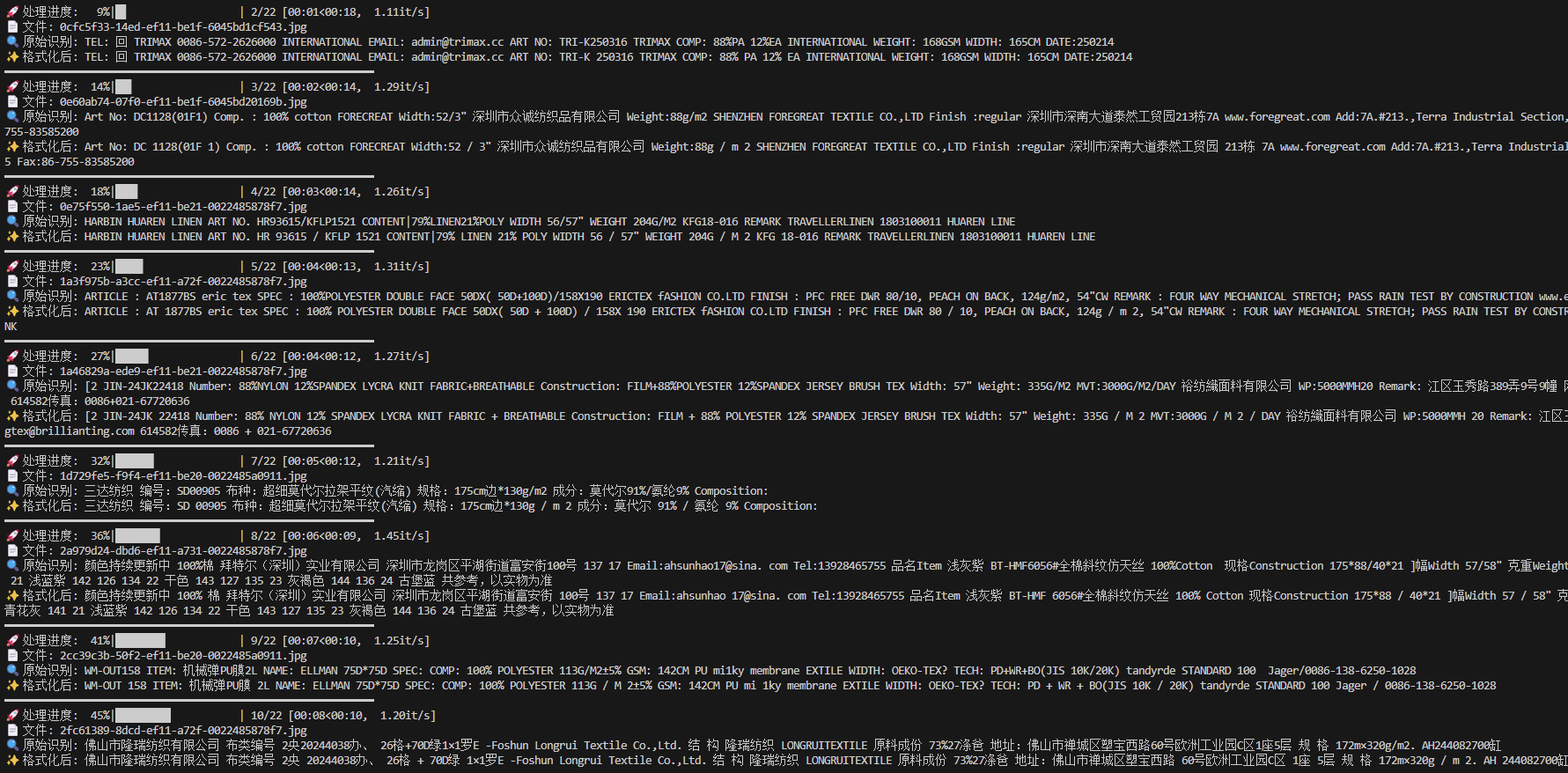

感谢大佬指正 小Monkey
如果你觉得有用的话,就留个赞吧!蟹蟹


















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











