







1. 起因, 目的:
前面使用 EasyOCR 用起来还行,能识别中文和英文,但精度不太行:
- 尤其是中文的句号、逗号经常识别错。
- 比如“栅栏”被认成“柳栏”,
- “太”和“大”
我查了下,确认自己用的是最新模型,但效果还是差强人意。
没办法,我决定试试——PaddleOCR 听说精度更高,支持中文也更好,我就装上了。
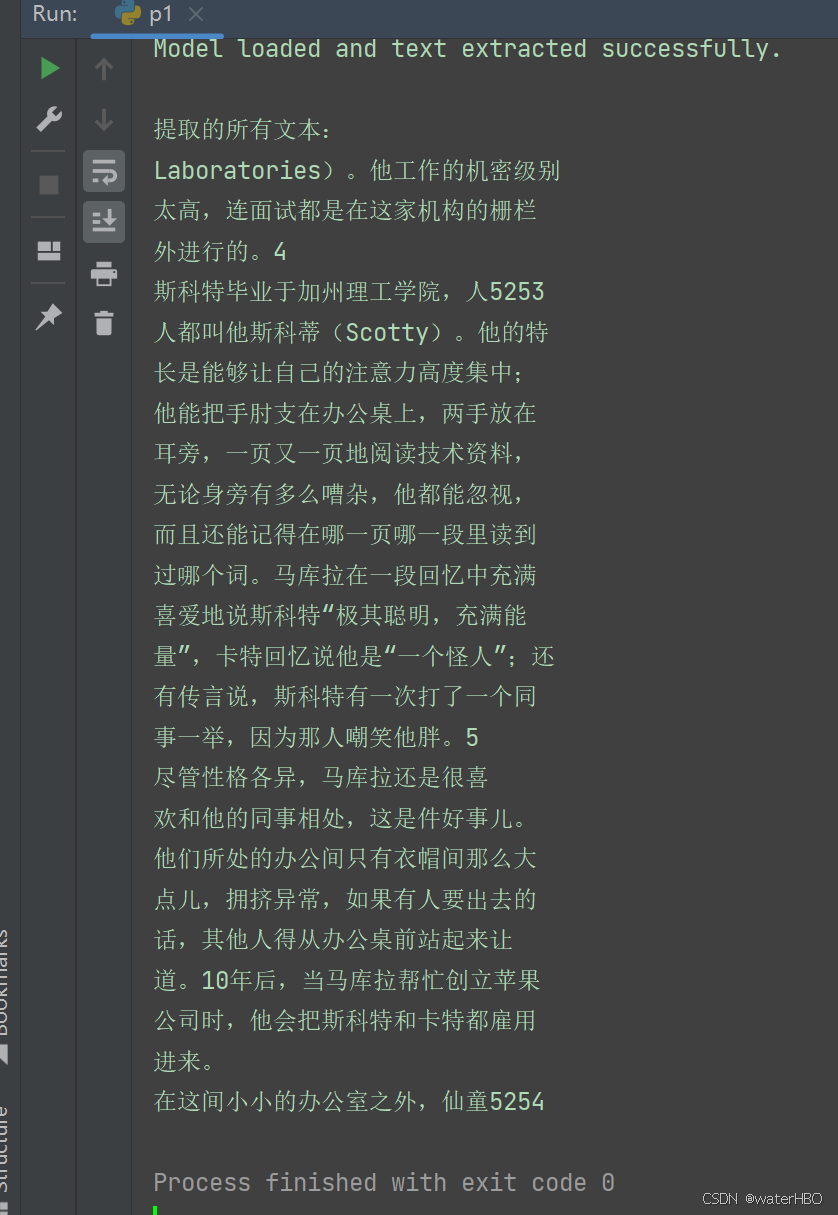
2. 先看效果 (效果确实不错。)
手机截图

输出结果
3. 过程:
- 把要求描述一下,让AI 来写代码。
- 整体也是很简单的。
代码 1 , 识别单个图片
- 这里是基础,后面的版本,都是在这个基础上进行增加。
- 使用 GPU, 不然得话, CPU 占用很高。
- 手动选择模型的文件名, 使用最新的模型。
- paddleocr 模型下载地址 https://paddlepaddle.github.io/PaddleOCR/latest/ppocr/model_list.html#21
from paddleocr import PaddleOCR
import os
# 定义函数,参数为图片文件名
def extract_text_from_image(image_path, det_model_dir=None, rec_model_dir=None, cls_model_dir=None):
# 初始化 PaddleOCR,手动指定模型路径
ocr = PaddleOCR(
use_gpu=True, # 启用 GPU
use_angle_cls=True,
lang='ch',
det_model_dir=det_model_dir, # 指定检测模型路径
rec_model_dir=rec_model_dir, # 指定识别模型路径
cls_model_dir=cls_model_dir, # 指定分类模型路径(可选)
use_space_char=True, # 启用空格识别
det_db_score_mode='fast', # 检测得分模式(fast 或 slow)
det_db_unclip_ratio=2.0 # 提高检测框扩展比例,减少漏检
)
# 读取图片并进行文字识别
result = ocr.ocr(image_path, cls=True)
# PaddleOCR 返回的 result 是一个列表,格式为 [[bbox, (text, prob)], ...]
# 提取文本和边界框
text_list = []
bbox_list = []
for line in result[0]: # result[0] 是第一个(也是唯一)图片的结果
bbox, (text, prob) = line
text_list.append(text)
bbox_list.append(bbox)
# 合并文本(按 y 坐标合并相邻行)
merged_text = []
current_line = ""
last_y = None
y_threshold = 20 # 假设 y 坐标差小于 20 像素为同一行
# 按 y 坐标排序结果(PaddleOCR 的 bbox 格式为 [[x1, y1], [x2, y2], [x3, y3], [x4, y4]])
sorted_result = sorted(zip(bbox_list, text_list), key=lambda x: x[0][0][1]) # 按左上角 y 坐标排序
for bbox, text in sorted_result:
current_y = bbox[0][1] # 左上角 y 坐标
if last_y is None or abs(current_y - last_y) < y_threshold:
current_line += text
else:
if current_line:
merged_text.append(current_line)
current_line = text
last_y = current_y
if current_line:
merged_text.append(current_line)
# 返回提取的文本列表
return merged_text
# 主程序:调用函数并处理结果
if __name__ == "__main__":
# 用户传入图片文件名
image_path = '2.jpg'
# 指定模型路径(替换为你下载并解压后的模型路径)
det_model_path = './models/ch_PP-OCRv4_det_server_infer.tar' # 检测模型路径
rec_model_path = './models/ch_PP-OCRv4_rec_server_infer.tar' # 识别模型路径
cls_model_path = './models/ch_ppocr_mobile_v2.0_cls_slim_infer.tar' # 分类模型路径(可选)
# 调用函数提取文本
print("Loading PaddleOCR model...")
extracted_text = extract_text_from_image(
image_path,
det_model_dir=det_model_path,
rec_model_dir=rec_model_path,
cls_model_dir=cls_model_path
)
print("Model loaded and text extracted successfully.")
# 打印提取的文本
print("\n提取的所有文本:")
for text in extracted_text:
print(text)
# 保存到文件
with open('one.txt', 'w', encoding='utf-8') as f:
for text in extracted_text:
f.write(text + '\n')
代码 2 , 批量识别, 把识别结果写入到一个文件中。
from paddleocr import PaddleOCR
import os
import time
from pathlib import Path
# 全局初始化 PaddleOCR,避免重复加载模型
print("Loading PaddleOCR model...")
paddle_ocr = PaddleOCR(
use_angle_cls=True,
lang='ch',
use_gpu=True,
det_model_dir='./models/ch_PP-OCRv4_det_infer', # 手动指定检测模型
rec_model_dir='./models/ch_PP-OCRv4_rec_infer', # 手动指定识别模型
cls_model_dir='./models/ch_ppocr_mobile_v2.0_cls_infer', # 手动指定分类模型
use_space_char=True, # 启用空格识别
det_db_score_mode='fast',
det_db_unclip_ratio=2.0
)
print("Model loaded successfully.")
# 重命名图片文件为 1.jpg 到 n.jpg
def rename_images_in_folder(folder_path):
# 支持的图片格式
image_extensions = {
'.jpg', '.jpeg', '.png', '.bmp', '.gif'}
# 收集所有图片文件
image_files = [f for f in os.listdir(folder_path)
if Path(f).suffix.lower() in image_extensions]
# 按文件名排序(可选,确保重命名前有一定顺序)
image_files.sort()
# 重命名文件
for index, old_name in enumerate(image_files, start=1) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











