







1、RedLock 算法
1.1、RedLock 算法是什么?
Redis 作者对于分布式锁提出的一种加锁算法,其实核心非常简单:假设redis集群中有N个redis节点,只有当客户端成功在 N/2+1 个实例中成功加锁成功,才算成功持有分布式锁。当然了,这算法里面还有很多其他的小细节,如果大家感兴趣,可以看看 redis 官网关于 RedLock 算法的介绍,是非常详细的。RedLock算法
那么,Redisson 有对应的实现么?
那是必须有的,各种锁都提供了,难道还会缺这个么?同时,我们可以在官网看到,官网对于 RedLock 算法的Java客户端实现,首推 Redisson。

1.2、为什么需要 RedLock 算法?
回头想想,为什么需要 RedLock 算法?
我们知道,之前提到的分布式锁有:可重入锁、公平锁、读写锁,他们其实底层都是根据key计算出一个槽(slot),这个槽可以对应到某个 Redis 集群的一个节点;那么就是说,这些分布式锁仅仅是在一个节点上加锁,那么下面的情况就会出现不同客户端持有锁:
- Redis 集群是多主多从架构,假设客户端1在MasterNode1上成功持有锁[myLock],但不幸的是,MasterNode1突然宕机了,并且此时还未将数据完全同步给SlaveNode1(包括客户端1的加锁信息),那么当 SlaveNode1 被选举为新的 MasterNode1 后,其他客户端就可以在新的 MasterNode1成功持有锁[myLock]。
其实这个场景,redis 官网在介绍 RedLock 算法的时候也提到了~
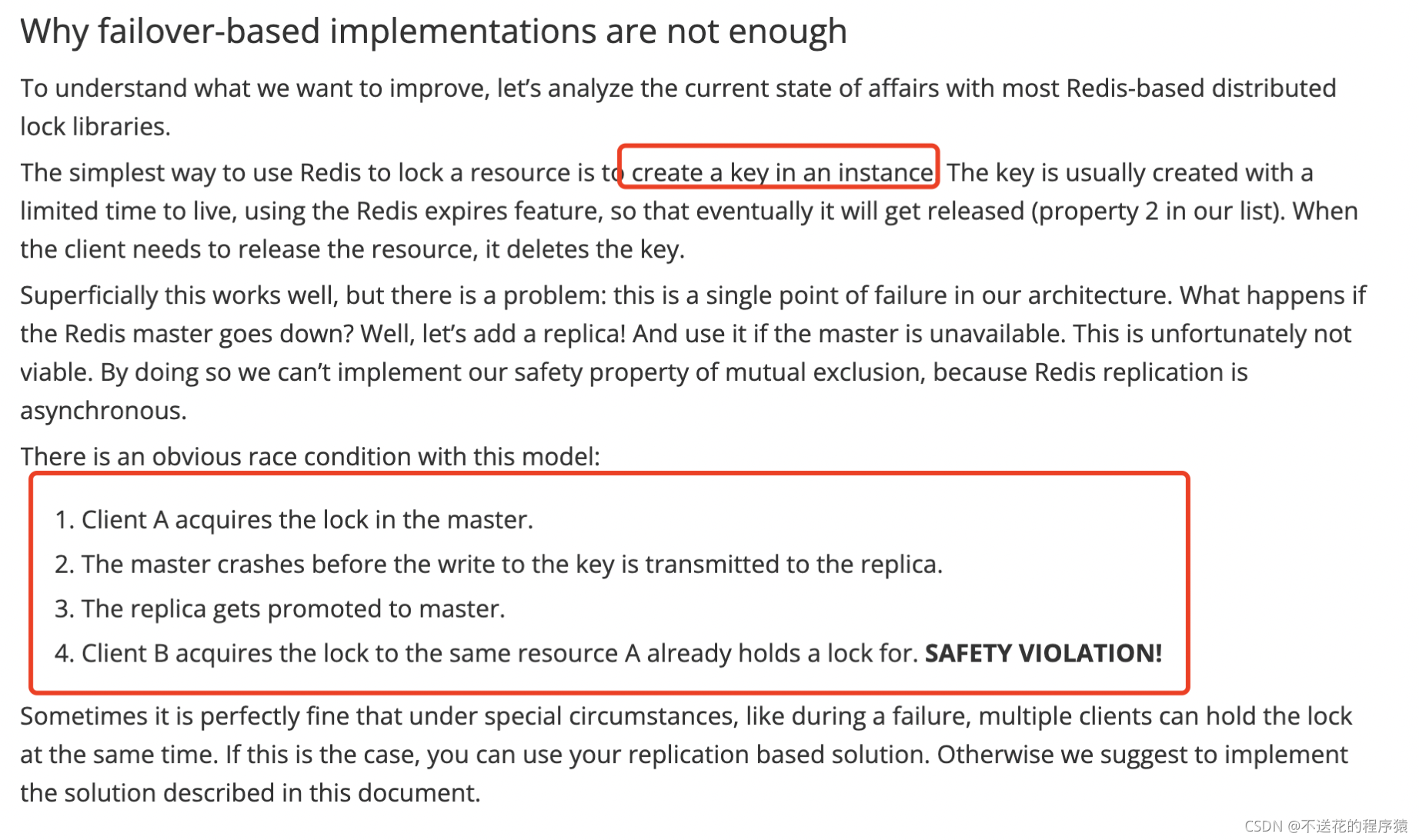
正是因为可能出现上面的场景,导致不同客户端可同时持有同一把锁,所以才推出 RedLock 算法。
但是我们上篇文章不是介绍了可以同时持有N个资源的 RedissonMultiLock 么,感觉它的实现原理可以完成这个 RedLock 算法。确实,在 Redisson 中,RedissonRedLock 就是基于 RedissonMultiLock 上面做的扩展,并且仅仅重写了三方法,下面我们将简单介绍一下。
2、RedissonRedLock
2.1、使用demo:
public class RedissonRedLockDemo {
public static void main(String[] args) {
RedissonClient redissonClient = RedissonClientUtil.getClient("");
RLock rLock1 = redissonClient.getLock("lock1");
RLock rLock2 = redissonClient.getLock("lock2");
RLock rLock3 = redissonClient.getLock("lock3");
RedissonRedLock redLock = new RedissonRedLock(rLock1, rLock2, rLock3);
redLock.lock();
redLock.unlock();
int result1 = CRC16.crc16("lock1".getBytes()) % 16384;
int result2 = CRC16.crc16("lock2".getBytes()) % 16384;
int result3 = CRC16.crc16("lock3".getBytes()) % 16384;
System.out.println("========测试一=========");
System.out.println(result1);
System.out.println(result2);
System.out.println(result3);
int result11 = CRC16.crc16("lockone".getBytes()) % 16384;
int result21 = CRC16.crc16("locktwo".getBytes()) % 16384;
int result31 = CRC16.crc16("lockthree".getBytes()) % 16384;
System.out.println("========测试二=========");
System.out.println(result11);
System.out.println(result21);
System.out.println(result31);
System.out.println("redis cluster 三个节点,平均 slot:"+16384/3);
}
}
我们可以看到,RedissonRedLock 不愧是基于 RedissonMultiLock 做的简单扩展,确实连使用都是基本一致的;只需要配置好 N 个锁,一般数量就是对应集群中主节点的数量,然后创建一个 RedissonRedLock 对象,接着就是调用获取锁和释放锁的方法即可。
2.2、使用 RedissonRedLock 时需要注意 key 的使用
那下面的那些计算slot是怎么回事?
在 RedLock 算法中提到的是,获取锁其实就是在所有 Rediss 实例节点使用同一个 key 进行加锁操作。
但在 Redisson 中,执行lua脚本前是需要根据 Key 来定位 slot 的,然后 slot 能对应一个 Redis 节点。那么,如果我们在使用 RedissonRedLock 时,如果所有 RLock 都指定同一个key,都等同于当前客户端在重复获取同一把锁,那么最终就达不到 RedLock 算法的效果了。
那么应该怎么指定 RedissonRedLock 中锁的 key 呢?
我们先看一下上面关于slot计算的两个测试结果:
========测试一=========
11346
7217
3088
========测试二=========
10453
998
6216
redis cluster 三个节点,平均 slot:5461
Process finished with exit code 0
redis 集群中,slot 的总数为 16394,如果集群中有三个主节点,那么第一个主节点的slot槽有:[1,5461]、第二个主节点的slot槽有:[5462,10923]、第三个主节点的slot槽有:[10924,16384]。当然了,不一定就是这些数,但是大概也差不了多少了。
我们可以发现,测试一中的key都分别分布在三个节点中了,而测试二中的key,一个在节点1中,两个在节点2中;这么一看,明显测试一中的key使用更符合 RedLock 算法。那么,我们可以认为测试一的key在RedissonRedLock 中使用是符合 RedLock 算法的。
其实,想保证 key 一定是使用正确的话,最稳健的就是研究 CRC16 算法是如何利用 key 定位 slot 的,当你分析透彻了,怎么使用也不在话下了。
2.3、源码分析:
好了,上面关于 key 在 RedissonRedLock 应该如何使用,也简单地分析完了,下面继续 RedissonRedLock 的源码分析。
因为 RedissonRedLock 是基于 RedissonMultiLock 做的简单扩展,而且只是重写了三方法,那么源码是非常的简单的,我们直接上源码。
RedissonRedLock 源码:
public class RedissonRedLock extends RedissonMultiLock {
/**
* Creates instance with multiple {@link RLock} objects.
* Each RLock object could be created by own Redisson instance.
*
* @param locks - array of locks
*/
public RedissonRedLock(RLock... locks) {
super(locks);
}
@Override
protected int failedLocksLimit() {
return locks.size() - minLocksAmount(locks);
}
protected int minLocksAmount(final List<RLock> locks) {
return locks.size()/2 + 1;
}
@Override
protected long calcLockWaitTime(long remainTime) {
return Math.max(remainTime / locks.size(), 1);
}
@Override
public void unlock() {
unlockInner(locks);
}
}
重写failedLocksLimit():
重写这个方法是因为,在 RedissonMultiLock 中,是要保证所有子锁都获取成功,连锁才算获取成功,所以 RedissonMultiLock 的 failedLocksLimit() 方法返回的是0。
而 RedissonRedLock 重写后,失败上限就是locks.size()/2 + 1,即 RedLock 算法中,大多数节点成功获取锁即可。
重写calcLockWaitTime(long remainTime):
RedissonMultiLock 遍历锁列表获取锁时,每个锁调用 tryLock 的等待时间都是同样的,即[baseTime/2,baseTime]之间的随机数。其中 baseWaitTime = locks.size() * 1500。因为 RedissonMultiLock 的 calcLockWaitTime 方法就是传入什么返回什么。
而 RedissonRedLock 重写后,是每个锁平分这个等待时间,如果均分后小于1,那就是1。我觉得这个重写,最大的意义在于能快速到下一个redis节点获取锁,因为 RedLock 算法只需保证大多数节点成功获取锁即可,避免等待多余的时间。
重写unlock():
直接调用 RedissonMultiLock 的 unlockInner() 方法。
3、最后
到此,关于 RedissonRedLock 锁的分析就完毕了;但其实 RedLock 算法不只这么一点东西,如果大家对这个算法感兴趣,可以到官网上面看看作者的介绍哈~
大家如果对此系列的文章感兴趣的话,可以直接关注专栏:<<分布式锁系列文章>>

















 1475
1475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









