







一、Lucene介绍
Lucene是一个全文检索的框架,apache组织提供了一个用Java实现的全文搜索引擎的开源项目,其功能非常的强大,api非常简单,并且有了全文检索的功能支持可以非常方便的实现根据关键字来搜索整个应用系统的内容,在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。
二、Lucene安装
-
1.安装JDK
-
在安装lucene之前需要首先安装jdk,因为lucene是在jdk的环境下运行的。最好下载jdk1.7以上的版本。如果没有安装jdk,可以按照以下步骤来安装:
我用的是jdk1.8.0_112,官网下载地址
默认的安装目录是C:\Program Files\Java\jdk1.8.0_112,安装完成后,配置环境变量,打开 计算机-属性-系统高级设置-环境变量:
新建一个系统变量,变量名为JAVA_HOME,变量值为:;C:\Program Files\Java\jdk1.8.0_112\bin;
其中C:\Program Files\Java\jdk1.8.0_112就是你的jdk安装目录。
选择系统变量中的Path进行编辑,在原有的变量值后增加;C:\Program Files\Java\jdk1.8.0_112\bin;
按照以上步骤完成后,jdk就可以安装到系统,运行cmd进入控制台,输入javac,弹出以下窗口,说明安装成功。
-
2.安装Tomcat
-
我安装的是Tomcat7.0.40
下载tomcat-7.0.40,官方下载地址,解压,运行tomcat-7.0.40的bin文件夹里的startup.bat来启动tomcat。
检测tomcat服务器是否安装成功。在网页中输入127.0.0.1:8080如果出现以下页面则说明安装成功。
-
3.安装Lucene
-
我下载的是最新版本Lucene6.3.0,Lucene6以上要求的Java最低版本为8,官方下载地址。
下载lucene-6.3.0.zip,解压,复制lucene-6.3.0/core中的lucene-core-6.3.0.jar和lucene-6.3.0/demo中的lucene-demo-6.3.0到jdk的安装C:\Program Files\Java\jdk1.8.0_112\下的lib文件夹。把lucene-6.3.0文件夹放到C盘。
设置环境变量,在“用户变量”和“系统变量”中都新建一个变量,变量名:CLASSPATH,变量值:
.;%JAVA_HOME%\lib\lucene-demo-6.3.0.jar;%JAVA_HOME%\lib\lucene-core-6.3.0.jar;C:\lucene-6.3.0\core\lucene-core-6.3.0.jar;C:\lucene-6.3.0\queryparser\lucene-queryparser-6.3.0.jar;C:\lucene-6.3.0\analysis\common\lucene-analyzers-common-6.3.0.jar;C:\lucene-6.3.0\demo\lucene-demo-6.3.0.jar;
-
4.建立索引
-
在控制台中输入:
java org.apache.lucene.demo.IndexFiles -docs C:\lucene-6.3.0
如果一切正确的话,就能看到一堆的控制台输出了,建立的索引,会放在一个index文件夹下,index文件夹在你cmd当前所在目录C:\Users\Administrator。
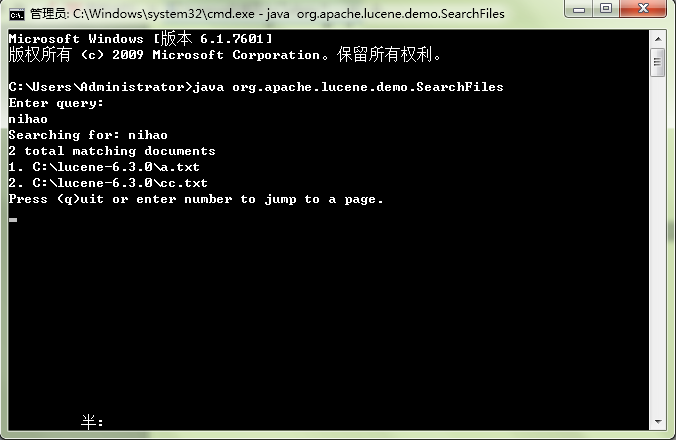
在lucene-6.3.0文件夹下新建一个a.txt和一个cc.txt文件,都输入hello,保存。
在控制台中输入:java org.apache.lucene.demo.SearchFiles,会显示“Enter query:”,输入hello,显示检索结果:
以上,就是Lucene的整个安装及配置过程。
三、Lucene执行过程
1、创建一个索引文件目录,然后把需要检索的信息 用Field 对应匹配的 封装成一个Document文档对象,将这个对象放入索引文件目录中,这里既可以将索引存放到磁盘中,也可以放入内存中,如果放入内存,那么程序关闭索引就没有了,所以一般都是将索引放入磁盘中;
2、如果发现信息有问题需要删除,那么索引文件也要删除,否则检索的时候还是会查询得到,这个时候需要根据索引id去删除对应的索引;
3、如果发现信息被更新了,那么索引文件也要更新,这个时候需要先将旧的索引删除然后添加新的索引;
4、最后是全文搜索,先创建索引读取对象,然后封装Query查询对象,调用search()方法得到检索结果。
四、Lucene代码实例
1.建立索引文件:
package HighLightSearch;
import java.io.IOException;
import java.nio.file.FileSystems;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.RAMDirectory;
public class Find {
public static void main(String[] args) throws IOException {
// 创建一个内存目录对象,所以这里生成的索引不会放在磁盘中,而是在内存中。
RAMDirectory directory = new RAMDirectory();
// 这里也可以创建一个磁盘目录对象
// Directory directory = FSDirectory.open(FileSystems.getDefault().getPath("C:/index"));
// 创建分词器
Analyzer analyzer = new StandardAnalyzer();
// 创建索引写入对象控制
IndexWriterConfig writerConfig = new IndexWriterConfig(analyzer);
/*
* 创建索引写入对象,该对象既可以把索引写入到磁盘中也可以写入到内存中。 参数说明:
* public IndexWriter(Directory directory, IndexWriterConfig conf)
* directory:目录对象,也可以是FSDirectory 磁盘目录对象
* conf:写入对象的控制
*/
IndexWriter writer = new IndexWriter(directory, writerConfig);
// 创建Document 文档对象,在lucene中创建的索引可以看成数据库中的一张表,表中也可以有字段,往里面添加内容之后可以根据字段去匹配查询
// 下面创建的doc对象中添加了三个字段,分别为name,,thing,
Document doc = new Document();
/*
* 参数说明 public Field(String name, String value, FieldType type)
* name : 字段名称
* value : 字段的值 store :
* TextField.TYPE_STORED:存储字段值
*/
doc.add(new Field("name", "Hsuan", TextField.TYPE_STORED));
doc.add(new Field("address", "中国广东", TextField.TYPE_STORED));
doc.add(new Field("thing", "I am learning lucene ",TextField.TYPE_STORED));
writer.addDocument(doc); //将文档添加到写入对象中
//这里也可以写入多个文档
Document doc1 = new Document();
doc1.add(new Field("name", "John", TextField.TYPE_STORED));
doc1.add(new Field("address", "中国北京", TextField.TYPE_STORED));
doc1.add(new Field("thing", "Welcome to lucene ",TextField.TYPE_STORED));
writer.addDocument(doc1);
writer.close(); // 这里可以提前关闭,因为dictory 写入内存之后 与IndexWriter 没有任何关系了
// 因为索引放在内存中,所以存放进去之后要立马测试,否则,关闭应用程序之后就检索不到了
// 如果放在磁盘中则不需要
// 创建IndexSearcher 检索索引的对象,里面要传递上面写入的内存目录对象directory
DirectoryReader directoryReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(directoryReader);
// 根据搜索关键字 封装一个term组合对象,然后封装成Query查询对象
// thing是上面定义的字段,lucene是对该字段检索的关键字
Query query = new TermQuery(new Term("thing", "lucene"));
// Query query = new TermQuery(new Term("thing", "I"));
//也可以对其他字段进行查询
// Query query = new TermQuery(new Term("address", "广东"));
// Query query = new TermQuery(new Term("name", "Hsuan"));
// 去索引目录中查询,返回的是TopDocs对象,里面存放的就是上面放的document文档对象
TopDocs topDocs = indexSearcher.search(query, 100);
System.out.println( "检索到" + topDocs.totalHits + "条记录。");
//读出得到的索引文件
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println("name:" + document.getField("name").stringValue());
System.out.println("address:" + document.getField("address").stringValue());
System.out.println("thing:" + document.getField("thing").stringValue());
}
directory.close(); //关闭,清除内存
}
} -
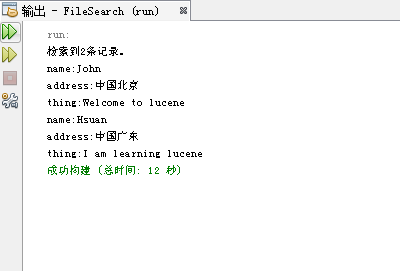
运行结果如下:
-
可以看到,新建的两个文件因为“thing”字段都有“lucene”而被索引出来了。2.StandardAnalyzer只能根据空格分析,所以能对英文进行分词,无法对中文分词,如果将查询语句改为:
Query query = new TermQuery(new Term(“address”, “广东”));
该语句是单个字节进行查询,查询到没有完全与“广东”匹配的,如果改为:
Query query = new TermQuery(new Term(“address”, “中国广东”));
那么就可以查询到结果。
因此,Lucene原生带的分词器不能够支持中文分词,如果对中文进行分词,需要使用其他高级的分词器。
3.分词器会将停用词去掉,如果查询语句改为:
Query query = new TermQuery(new Term(“thing”, “I”));
查询结果为0。
参考资料:
http://blog.csdn.net/qq_35522169/article/details/52460262
http://blog.csdn.net/joker233/article/details/51909565















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









