










import concurrent.futures
import blog_spider
# craw
with concurrent.futures.ThreadPoolExecutor() as pool:
htmls = pool.map(blog_spider.craw, blog_spider.urls)
htmls = list(zip(blog_spider.urls, htmls))
for url, html in htmls:
print(url, len(html))
print('craw over')
# parse
with concurrent.futures.ThreadPoolExecutor() as pool:
futures = {}
for url, html in htmls:
future = pool.submit(blog_spider.parse, html)
futures[future] = url
for future in concurrent.futures.as_completed(futures):
url = futures[future]
print(url,future.result())

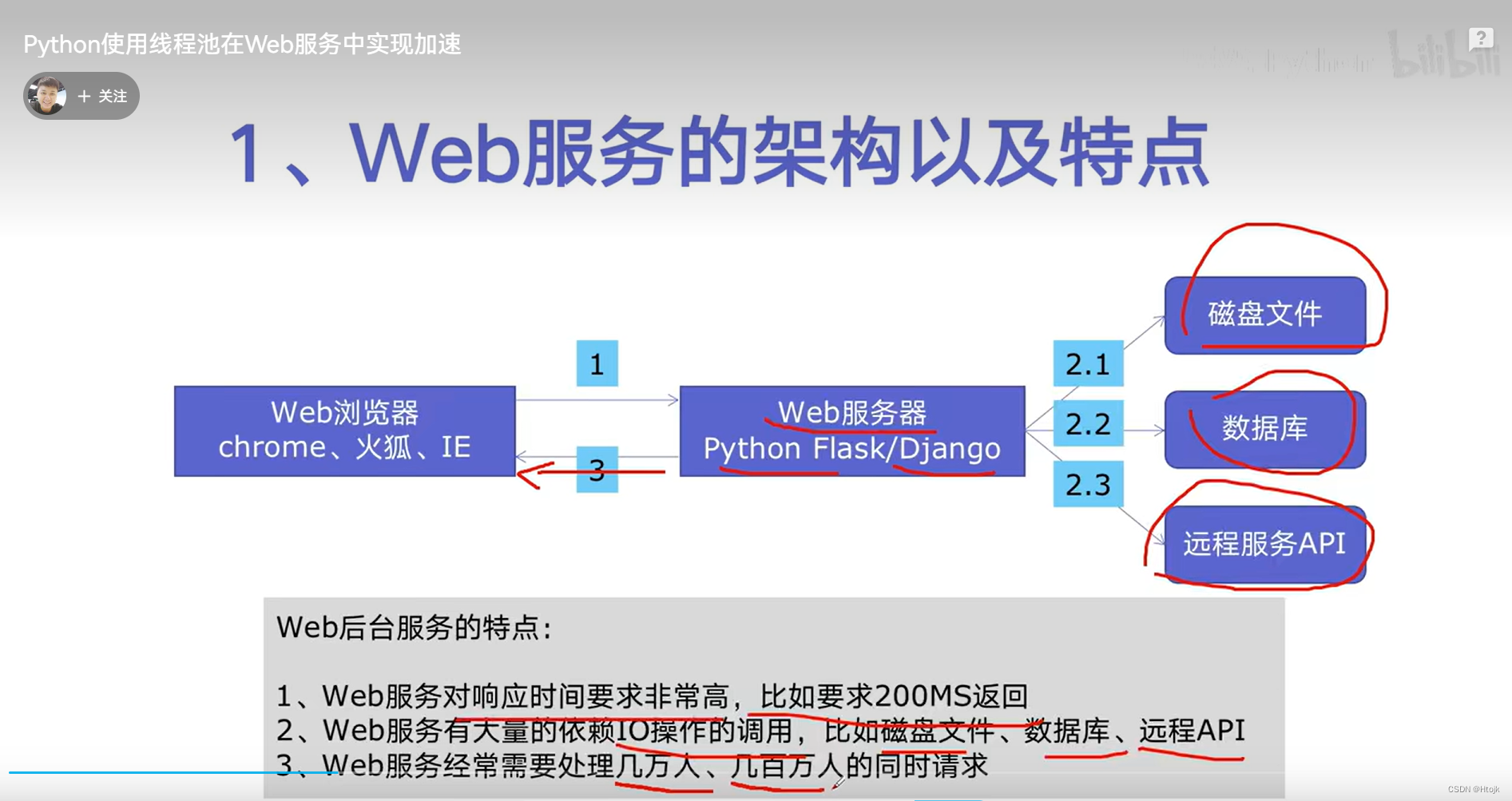
 在web服务中实现并发加速
在web服务中实现并发加速
import flask
import json
import time
import concurrent.futures
app = flask.Flask(__name__)
def read_file():
time.sleep(0.1)
print('result_file')
def read_db():
time.sleep(0.2)
print('result_db')
def read_api():
time.sleep(0.3)
print('result_api')
@app.route("/")
def index():
with concurrent.futures.ThreadPoolExecutor() as pool:
result_file = pool.submit(read_file)
result_db = pool.submit(read_db)
result_api = pool.submit(read_api)
return json.dumps({
'result_file':result_file.result(),
'result_db':result_db.result(),
'result_api':result_api.result()
})
if __name__ == '__main__':
app.run()




flask中使用多进程加速
import flask
import math
import json
from concurrent.futures import ProcessPoolExecutor
# process_pool = ProcessPoolExecutor()
app = flask.Flask(__name__)
def is_prime(n):
if n<2:
return False
if n==2:
return True
if n%2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3,sqrt_n,2):
if n%i == 0:
return False
return True
@app.route("/is_prime/<numbers>")
def api_is_prime(numbers):
number_list = [int(x) for x in numbers.split(',')]
results = process_pool.map(is_prime,number_list)
return json.dumps(dict(zip(number_list,results)))
if __name__=="__main__":
process_pool = ProcessPoolExecutor()
app.run()异步IO


import asyncio
import blog_spider
import aiohttp
async def async_craw(url):
print('craw url:',url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f'craw url:{url},{len(result)}')
loop = asyncio.get_event_loop()
tasks = [
loop.create_task(async_craw(url))
for url in blog_spider.urls
]
import time
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print('异步io用时:',end-start)

资料来源:
在异步IO中使用信号量控制爬虫并发度_哔哩哔哩_bilibili















 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









