







📣 前言
- 👓 可视化主要使用 plotly
- 🔎 数据处理主要使用 pandas
- 🕷️ 数据爬取主要使用 requests
- 👉 本文是我自己在和鲸社区的原创
今天这篇文章将给大家介绍小宇宙中文播客热门榜单数据分析及可视化案例。
Step 1. 导入模块
import numpy as np
import pandas as pd
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import warnings
from pandas.core.common import SettingWithCopyWarning
warnings.filterwarnings('ignore', category=SettingWithCopyWarning)
Step 2. 数据概览
数据下载:关注公众号【布鲁的Python之旅】,回复关键字 【小宇宙】 获取。
podcast_data =pd.read_csv(r"/home/mw/input/sjj8477/热门播客_240313_1710313614.csv")
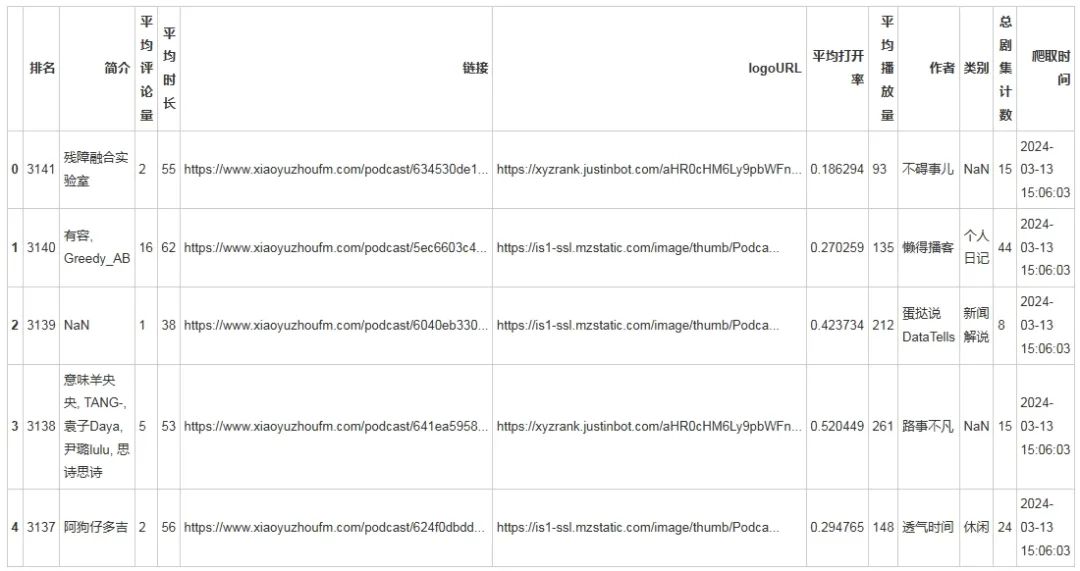
podcast_data.head()
输出结果:
Step 3. 数据分析及可视化
哪些因素会影响播客的打开率
为了分析影响播客打开率的因素,我们可以首先考虑以下几个可能影响打开率的因素:
- 平均评论量:通常评论量较多的播客可能更受关注,因此可能会有更高的打开率。
- 平均时长:播客的时长可能会影响听众的选择。例如,一些听众可能更喜欢短时间的播客,而另一些则可能更喜欢长时间的深入讨论。
- 类别:不同类别的播客可能有不同的受众群体,这可能会影响打开率。
- 总剧集计数:拥有更多剧集的播客可能有更稳定的听众群体,这可能会影响打开率。
接下来,我将进行以下步骤的分析:
- 对数据进行初步的清洗,处理缺失值和异常值。
- 对上述可能的因素进行描述性统计分析。
- 使用适当的统计图表或可视化工具展示数据和分析结果。
- 根据分析结果进行总结。
对数据进行初步的清洗,处理缺失值和异常值
接下来,我将进行以下步骤的分析:
对数据进行初步的清洗,处理缺失值和异常值
# Check for missing values in the dataset
missing_values = podcast_data.isnull().sum()
# Check for any outliers in the numerical columns
num_cols = ['平均评论量', '平均时长', '平均打开率', '平均播放量', '总剧集计数']
outliers_info = {}
for col in num_cols:
IQR = podcast_data[col].quantile(0.75) - podcast_data[col].quantile(0.25)
lower_bound = podcast_data[col].quantile(0.25) - 1.5 * IQR
upper_bound = podcast_data[col].quantile(0.75) + 1.5 * IQR
outliers_count = ((podcast_data[col] < lower_bound) | (podcast_data[col] > upper_bound)).sum()
outliers_info[col] = (outliers_count, lower_bound, upper_bound)
missing_values, outliers_info
输出结果:
(排名 0
简介 62
平均评论量 0
平均时长 0
链接 0
logoURL 0
平均打开率 0
平均播放量 0
作者 0
类别 1063
总剧集计数 0
爬取时间 0
dtype: int64,
{'平均评论量': (315, -44.5, 87.5),
'平均时长': (71, 1.5, 109.5),
'平均打开率': (274, -0.47575540670101657, 1.264120383512492),
'平均播放量': (414, -3328.0, 6640.0),
'总剧集计数': (333, -46.5, 117.5)})
结论:
从上述数据中,我们可以观察到以下几点:
缺失值:
- “简介”列有 62 个缺失值。
- “类别”列有 1063 个缺失值。
- 其他列没有缺失值。
异常值:
- “平均评论量”有 315 个异常值。
- “平均时长”有 71 个异常值。
- “平均打开率”有 274 个异常值。
- “平均播放量”有 414 个异常值。
- “总剧集计数”有 333 个异常值。
为了进一步分析,我们需要处理这些缺失值和异常值。
● 对于缺失值,我们可以选择删除或填充。
● 对于异常值,我们可以选择删除或将其视为特殊情况进行分析。
接下来,将对数据进行处理,并开始分析影响播客打开率的因素。
首先,删除有大量缺失值的**“简介”和“类别”**列,并对其他列的异常值进行处理。
podcast_data_cleaned = podcast_data.drop(columns=['简介', '类别'])
for col in num_cols:
lower_bound = outliers_info[col][1]
upper_bound = outliers_info[col][2]
podcast_data_cleaned = podcast_data_cleaned[(podcast_data_cleaned[col] >= lower_bound) & (podcast_data_cleaned[col] <= upper_bound)]
podcast_data_cleaned.info()
输出结果:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2191 entries, 0 to 3044
Data columns (total 10 columns):
排名 2191 non-null int64
平均评论量 2191 non-null int64
平均时长 2191 non-null int64
链接 2191 non-null object
logoURL 2191 non-null object
平均打开率 2191 non-null float64
平均播放量 2191 non-null int64
作者 2191 non-null object
总剧集计数 2191 non-null int64
爬取时间 2191 non-null object
dtypes: float64(1), int64(5), object(4)
memory usage: 188.3+ KB
描述性统计分析
经过清洗,我们得到了一个包含2191个条目的数据集。现在,我们将进行以下分析:
1、描述性统计分析:我们将查看“平均评论量”、“平均时长”、“总剧集计数”等列的平均值、中位数、标准差等统计信息。
2、可视化分析:我们将使用散点图、箱线图等可视化工具来展示这些因素与“平均打开率”之间的关系。
3、总结:根据上述分析,我们将总结哪些因素可能影响播客的打开率。
首先,我们来进行描述性统计分析
desc_stats = podcast_data_cleaned[num_cols].describe()
desc_stats
输出结果:
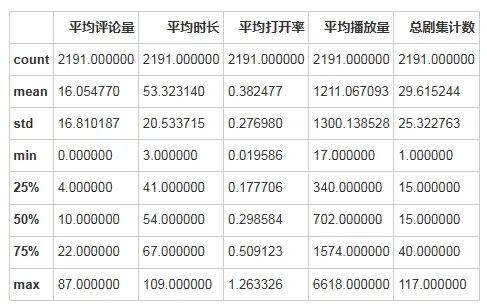
以下是“平均评论量”、“平均时长”、“平均打开率”、“平均播放量”和“总剧集计数”的描述性统计信息:
- 平均评论量:
- 平均值: 16.05
- 中位数: 10
- 最小值: 0
- 最大值: 87
- 平均时长:
- 平均值: 53.32 分钟
- 中位数: 54 分钟
- 最小值: 3 分钟
- 最大值: 109 分钟
- 平均打开率:
- 平均值: 0.382
- 中位数: 0.299
- 最小值: 0.020
- 最大值: 1.263
- 平均播放量:
- 平均值: 1211.07
- 中位数: 702
- 最小值: 17
- 最大值: 6618
- 总剧集计数:
- 平均值: 29.62
- 中位数: 15
- 最小值: 1
- 最大值: 117
接下来,我们将使用可视化工具来分析这些因素与“平均打开率”之间的关系。我们首先来看一下“平均评论量”、“平均时长”和“总剧集计数”与“平均打开率”之间的散点图。
接下来,我们将使用可视化工具来分析这些因素与“平均打开率”之间的关系。
我们首先来看一下**“平均评论量”、“平均时长”和“总剧集计数”与“平均打开率”**之间的散点图。
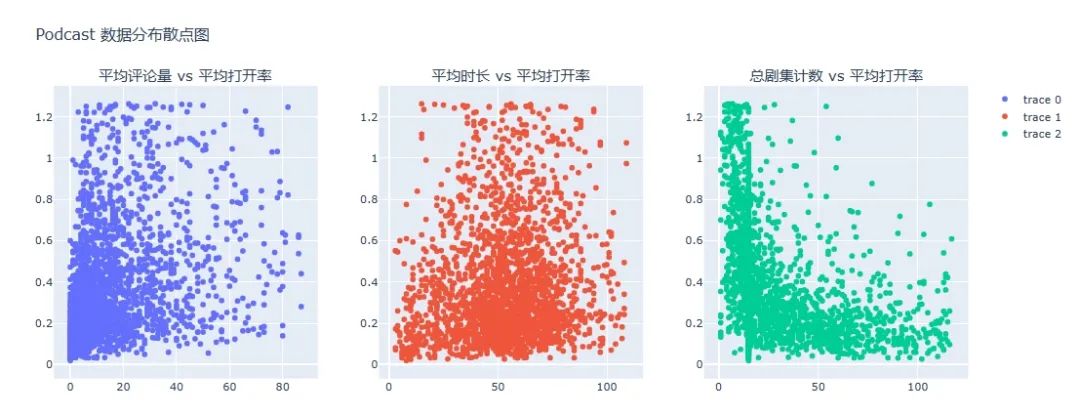
结论:
1、平均评论量与平均打开率:
图中显示了一些高评论量的播客有较高的打开率,但也存在一些评论量较低但打开率较高的播客。这可能表明评论量与打开率之间存在一定的关联,但并不是唯一的决定因素。
2、平均时长与平均打开率:
图中显示不同时长的播客都有较高的打开率,没有明显的趋势表明时长与打开率之间存在直接的关联。
3、总剧集计数与平均打开率:
图中显示总剧集计数较高的播客通常有较高的打开率。这可能表明拥有更多剧集的播客可能有更稳定的听众群体,从而提高打开率。
接下来,我们可以进一步分析**“类别”**这一因素。
由于原始数据中“类别”列存在大量缺失值,我们无法直接使用该列进行分析。但我们可以根据其他信息(如播客的名称、作者等)尝试推断出一些可能的类别,并分析这些类别与打开率之间的关系。
首先,我们可以查看一些播客的名称和作者,以便了解可能的类别。
sample_authors = podcast_data_cleaned[['排名', '作者']].sample(10)
sample_authors
输出结果:
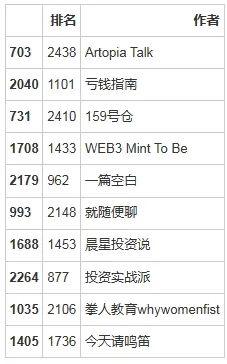
这是随机选取的一些播客的作者:
- 出海早知道
- 整点发盐
- 杰夫说
- 偶然事件aha-moment
- 柠檬变成柠檬水
- 西海之声 Radio SayHi!
- 小畅翻牌|开小灶
- 随便聊聊|JusTalk
- 雪梨卷·100种销洒人生
- 桃汽电波
从这些播客的名称中,我们可以推断出一些可能的类别,例如:
- 新闻/信息类:如“出海早知道”
- 娱乐/生活类:如“整点发盐”、“杰夫说”
- 教育/知识类:如“柠檬变成柠檬水”
- 文化/艺术类:如“西海之声 Radio SayHi!”
结论:
**1、平均评论量:**高评论量的播客通常有较高的打开率,但并非所有高评论量的播客都有高打开率。
**2、平均时长:**没有明显的趋势表明时长与打开率之间存在直接的关联。
**3、总剧集计数:**拥有更多剧集的播客通常有较高的打开率,这可能表明稳定的听众群体有助于提高打开率。
请注意,由于数据的限制,我们无法进行更深入的分析。如果有更详细的数据或其他相关信息,我们可以进行更全面的分析。
数值变量之间的关系
直方图
展示“平均评论量”、“平均时长”、“平均打开率”、“平均播放量”和“总剧集计数”的分布情况。
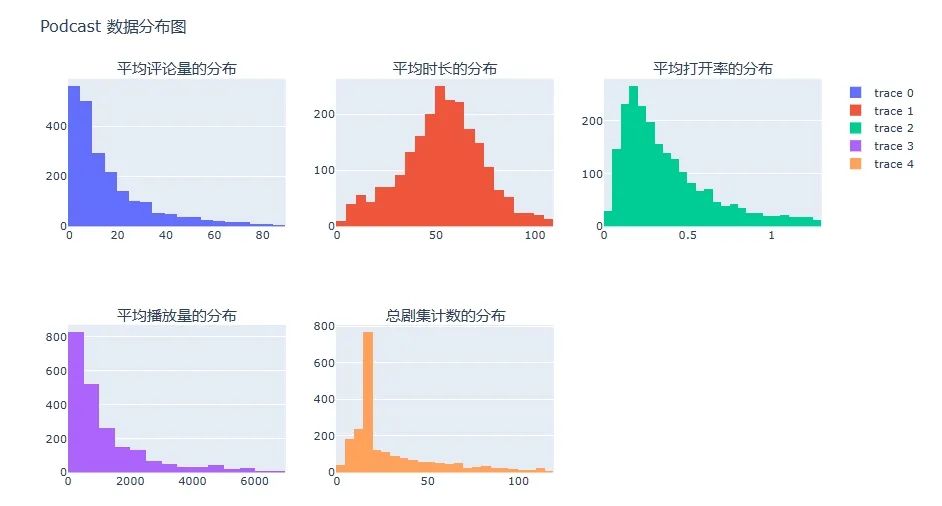
结论:
**● 平均评论量:**大多数播客的平均评论量在较低范围内,但也有一些播客的评论量较高。
● 平均时长:播客的平均时长主要集中在30 至 70 分钟之间,但也有一些播客的时长较短或较长。
● 平均打开率:大多数播客的平均打开率在0.2 至 0.6 之间,但也有一些播客的打开率较高。
● 平均播放量:播放量的分布较为分散,但大多数播客的平均播放量在较低范围内。
**● 总剧集计数:**大多数播客的总剧集计数在较低范围内,但也有一些播客的剧集数量较多。
接下来,我们将使用箱线图来查看这些数值变量的四分位数和异常值。
箱线图
# 创建一个包含2行3列子图的Figure对象``fig = make_subplots(rows=2, cols=3, subplot_titles=['平均评论量的箱线图', '平均时长的箱线图', '平均打开率的箱线图', '平均播放量的箱线图', '总剧集计数的箱线图'])`` ``# 添加每个子图,指定位置、大小和数据``fig.add_trace(go.Box(y=podcast_data_cleaned['平均评论量']), row=1, col=1)``fig.add_trace(go.Box(y=podcast_data_cleaned['平均时长']), row=1, col=2)``fig.add_trace(go.Box(y=podcast_data_cleaned['平均打开率']), row=1, col=3)``fig.add_trace(go.Box(y=podcast_data_cleaned['平均播放量']), row=2, col=1)``fig.add_trace(go.Box(y=podcast_data_cleaned['总剧集计数']), row=2, col=2)`` ``# 更新布局``fig.update_layout(height=800, width=1200, title_text="Podcast 数据分布箱线图")`` ``# 显示图形``fig.show()
输出结果:

结论:
**● 平均评论量:**大部分播客的平均评论量集中在较低的范围,但也有一些播客的评论量较高。
**● 平均时长:**大多数播客的平均时长在 30 至 70 分钟之间,但也存在一些较短的播客。
● 平均打开率**:**大部分播客的平均打开率在 0.2 至 0.6 之间,但也有一些播客的打开率较高。
**● 平均播放量:**播放量的分布较为分散,但大多数播客的平均播放量在较低范围内。
**● 总剧集计数:**大部分播客的总剧集计数在较低范围内,但也有一些播客的剧集数量较多。
最后,我们将使用热力图来查看这些数值变量之间的相关性。这将帮助我们了解变量之间的线性关系。
热力图
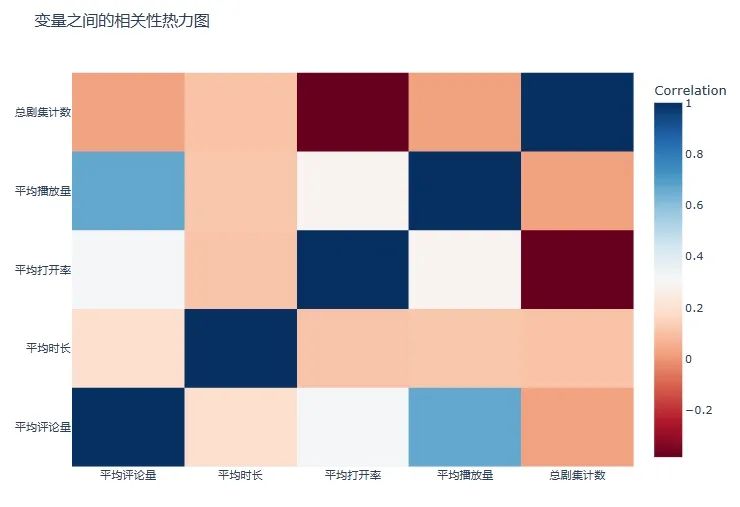
结论:
**● 平均评论量与平均播放量:**两者之间存在较强的正相关性(约 0.63),这意味着评论量越多的播客通常播放量也越高。
**● 平均播放量与总剧集计数:**两者之间存在中等程度的正相关性(约 0.44),这意味着拥有更多剧集的播客通常播放量也更高。
● 平均打开率与其他变量:平均打开率与其他变量之间的相关性较弱。尽管平均打开率与平均播放量之间存在一定的正相关性(约0.21),但这并不意味着打开率是由这些变量直接决定的。
请注意,这些只是基于现有数据的观察结果。实际情况下,播客的打开率可能受多种因素的影响,包括内容质量、受众群体、推广策略等。
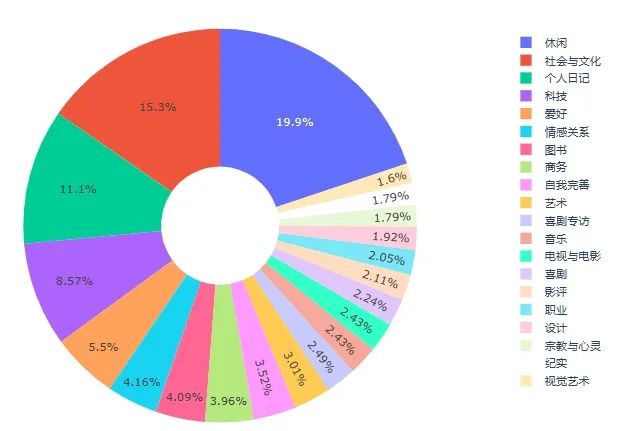
类别分布 Top20
category_counts = podcast_data['类别'].value_counts()[:20]``
category_counts
输出结果:
休闲 311
社会与文化 240
个人日记 174
科技 134
爱好 86
情感关系 65
图书 64
商务 62
自我完善 55
艺术 47
喜剧专访 39
音乐 38
电视与电影 38
喜剧 35
影评 33
职业 32
设计 30
宗教与心灵 28
纪实 28
视觉艺术 25
Name: 类别, dtype: int64
# 创建 Pie 对象
fig = go.Figure(data=[go.Pie(labels=category_counts.index, values=category_counts, hole=0.3)])
# 设置布局
fig.update_layout(title='类别分布Top20', width=800, height=600)
# 显示图形
fig.show()
输出结果:
完整代码 👇
https://www.heywhale.com/mw/project/65f839ad3e36b30ae9fbfc3c
ps:此代码可以直接在线运行,不需要担心环境配置问题
数据集下载
关注公众号,回复关键字【小宇宙】获取
- END -
以上就是本期为大家整理的全部内容了,喜欢的朋友可以点赞、点在也可以分享让更多人知道。
👆 关注「布鲁的 Python 之旅」第一时间收到更新


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









