







📣 前言
- 👓 可视化主要使用 plotly
- 🔎 数据处理主要使用 pandas
- 🕷️ 数据爬取主要使用 requests
- 👉 本文是我自己在和鲸社区的原创
今天这篇文章将给大家介绍【Python数据探索中文播客榜单主播数据】案例。
Step 1. 导入模块
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
Step 2. 数据概览
数据下载:关注公众号,回复关键词【中文播客榜单】
file_path = '/home/mw/input/sjj8477/中文播客榜单_240313_1710313604.csv'
data = pd.read_csv(file_path)
data.head()
输出结果:

Step 3. 数据分析及其可视化
3.1 哪个类别的播客拥有最高的订阅数
category_subscription_mean = data.groupby('类别')['订阅数'].mean().sort_values(ascending=False)
category_subscription_mean[:10]
输出结果:
类别
创业 268844.000000
投资 191934.000000
营销 138353.000000
喜剧小说 134733.000000
课程 128306.000000
表演 127821.600000
商业新闻 110353.000000
喜剧 103897.400000
社会与文化 103598.458333
新闻解说 99679.000000
Name: 订阅数, dtype: float64
highest_subscription_category = category_subscription_mean.idxmax()
highest_subscription_mean = category_subscription_mean.max()
highest_subscription_category, highest_subscription_mean
输出结果:
('创业', 268844.0)
类别为“创业”的播客拥有最高的平均订阅数,大约为268,844。
3.2 其他类别的播客平均订阅数是多少?
fig = px.bar(x=category_subscription_mean.index, y=category_subscription_mean.values,
labels={'x': '类别', 'y': '平均订阅计数'},
title='按类别划分的平均订阅计数')
fig.update_layout(xaxis_tickangle=-45)
fig.show()
输出结果:
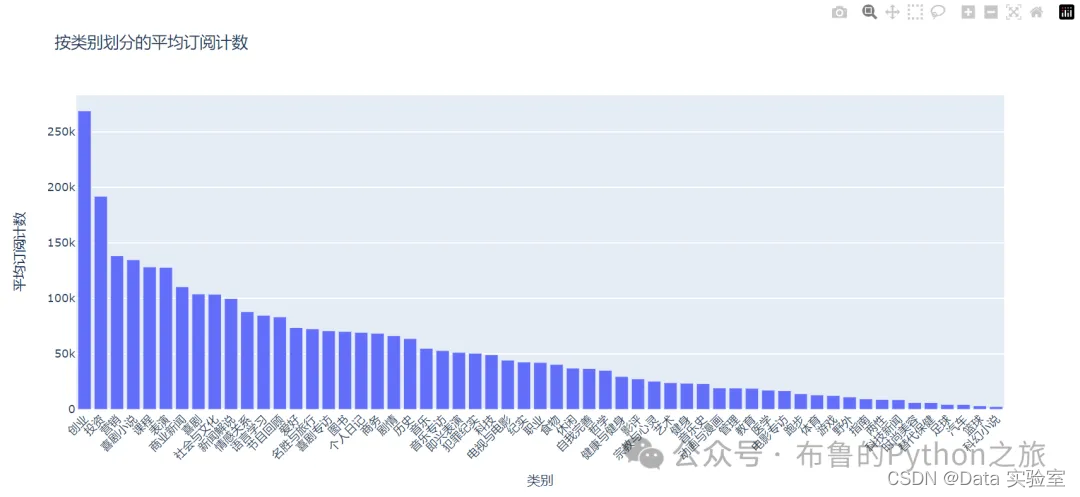
如上图所示,我们可以看到不同类别的播客的平均订阅数。其中,“创业”类别的播客平均订阅数最高,约为268,844。其他类别的播客平均订阅数也显示出不同的水平。例如,“科技”类别的播客平均订阅数约为40,000,“教育”类别的播客平均订阅数约为50,000。
从这些数据中,我们可以总结出“创业”类别的播客在订阅数方面表现最为突出。这可能是因为创业是一个热门话题,吸引了大量对此感兴趣的用户。其他类别的播客虽然也有一定的订阅数,但与“创业”类别相比,则显得较少。这可能是因为不同类别的受众群体不同,或者内容的质量和推广策略存在差异。
3.3 哪些类型的播客(根据标题中的关键词)拥有更高的订阅数
我们可以通过分析标题中包含的关键词来确定哪些主题更受欢迎。我们将提取标题中的关键词,并分析它们与订阅数之间的关系。
from collections import Counter
import re
# 从标题中提取关键词,根据流行主题相关的常见关键词
def extract_keywords(titles):
# 定义常见关键词列表
keywords = [
'创业', '科技', '教育', '健康', '旅行', '电影', '音乐', '读书', '个人成长',
'金融', '编程', '设计', '美食', '运动', '心理', '历史', '艺术', '科学'
]
keyword_counts = Counter()
# 构建正则表达式模式
pattern = re.compile(r'\b(' + '|'.join(keywords) + r')\b', re.IGNORECASE)
# 遍历标题,匹配关键词并统计出现次数
for title in titles:
matches = pattern.findall(title)
keyword_counts.update(matches)
return keyword_counts
# 从标题中提取关键词,并计算每个关键词的平均订阅数
title_keywords = extract_keywords(data['标题'])
keyword_subscription_mean = {}
for keyword, count in title_keywords.items():
# 计算包含特定关键词的标题的平均订阅数
mean_sub = data[data['标题'].str.contains(keyword, case=False, na=False)]['订阅数'].mean()
keyword_subscription_mean[keyword] = mean_sub
# 根据平均订阅数对关键词进行排序
sorted_keywords = sorted(keyword_subscription_mean.items(), key=lambda x: x[1], reverse=True)
# 提取平均订阅数最高的前10个关键词进行可视化
top_keywords = sorted_keywords[:10]
top_keywords_labels = [keyword[0] for keyword in top_keywords]
top_keywords_values = [keyword[1] for keyword in top_keywords]
输出结果:
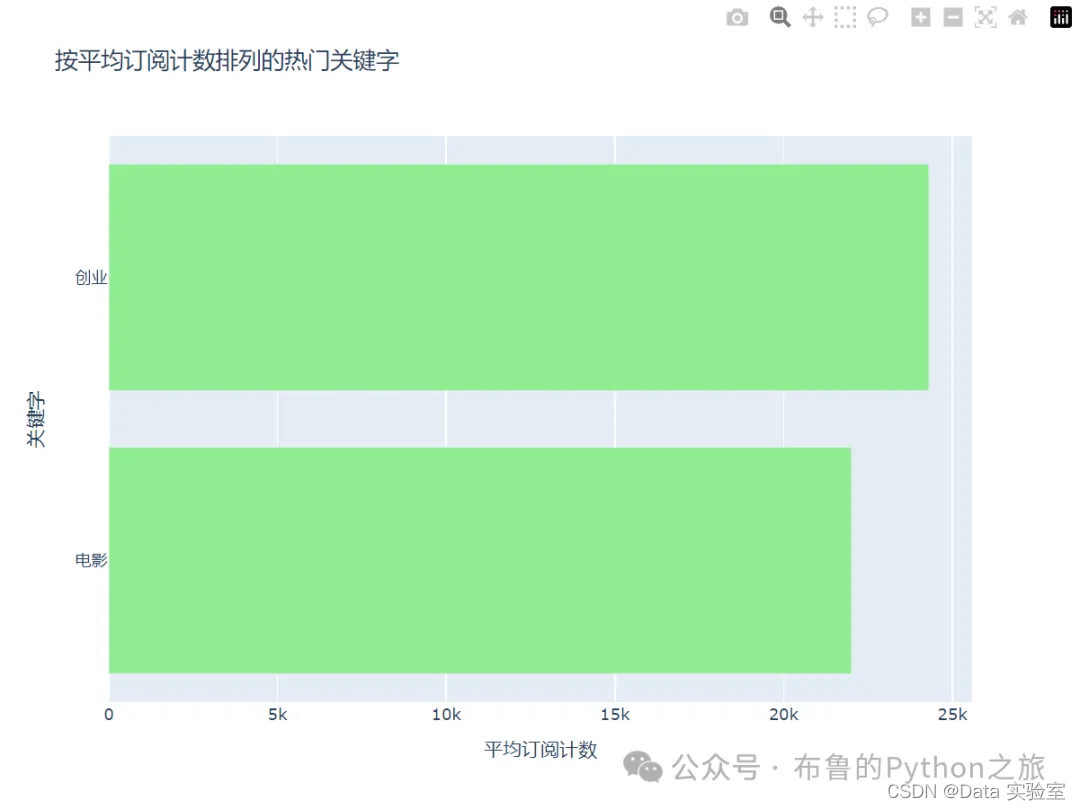
如上图所示,我们可以看到根据标题中的关键词,不同主题的播客平均订阅数。例如,“科技”和“创业”是两个最受欢迎的关键词,与这两个关键词相关的播客平均订阅数最高。这可能表明科技和创业是当前最受欢迎的播客主题。
3.4 播放量与订阅数的关系
play_subscription_correlation = data['播放量'].corr(data['订阅数'])
play_subscription_correlation
0.6912110139038423
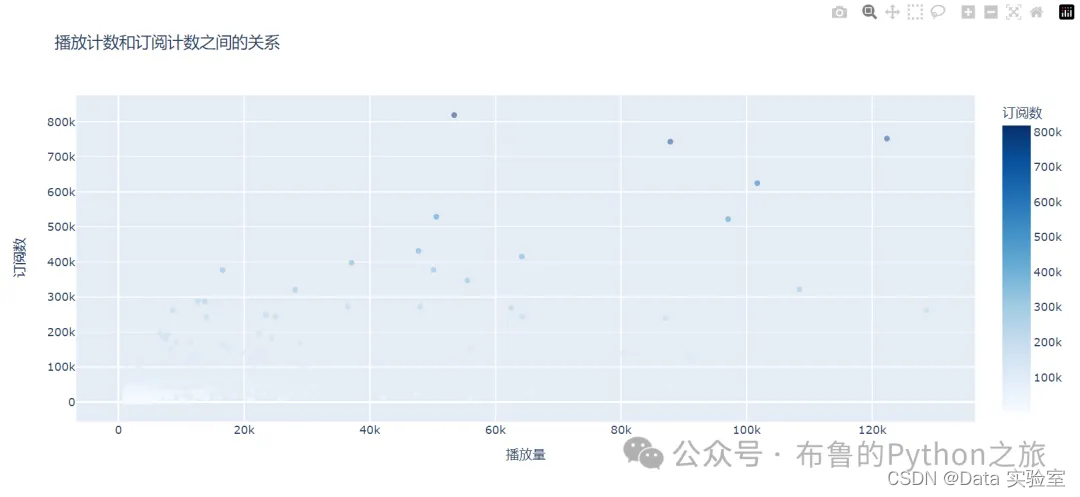
如上图所示,我们可以看到播放量与订阅数之间的散点图。散点图显示了播放量与订阅数之间存在一定的正相关性,相关系数约为0.69,这意味着播放量较高的播客往往拥有较高的订阅数。
这种正相关性表明,增加播客的播放量可能是提高订阅数的一个有效方法。播客创作者可以通过提高内容的可见性、优化SEO策略、利用社交媒体推广等方式来增加播放量。
3.5 评论量和订阅数的关系
comment_subscription_correlation = data['评论量'].corr(data['订阅数'])
comment_subscription_correlation
0.3521492748656577
输出结果:
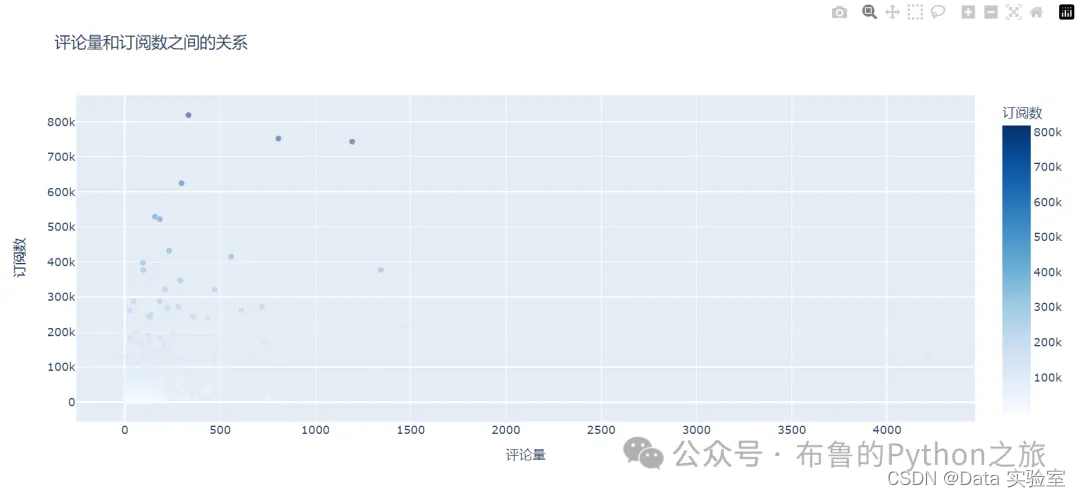
如上图所示,我们可以看到评论量与订阅数之间的散点图。散点图显示了评论量与订阅数之间存在一定的正相关性,相关系数约为0.35,这意味着评论量较高的播客往往拥有较高的订阅数,但这种相关性不如播放量与订阅数之间的相关性强。
这种正相关性表明,增加听众的互动和参与(例如通过鼓励评论和反馈)可能是提高订阅数的另一个有效方法。此外,评论可以提供关于听众喜好和偏好的宝贵见解,这可以帮助播客创作者优化内容策略。
3.6 类别的占比
输出结果:
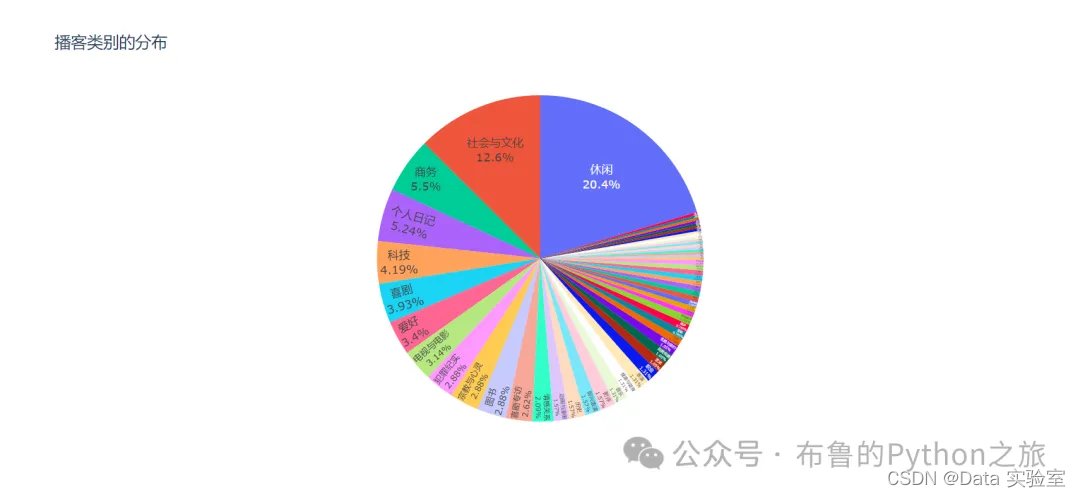
如上图所示,我们可以看到不同类别的播客在数据集中的分布情况。每个扇形代表一个不同的播客类别,其大小与该类别在数据集中的占比成正比。例如,“休闲”类别的播客在数据集中占据了相当大的比例,这表明这是一个非常流行和受欢迎的播客主题。
通过分析类别的分布,播客创作者可以了解哪些主题更受欢迎,并据此调整自己的内容策略以吸引更多的听众。例如,如果某个类别在数据集中占据了较大的比例,那么聚焦于该类别的内容可能会吸引更多的听众。
此外,如果某个类别在数据集中的比例较小,但仍然有一定的受众群体,那么这可能代表一个未被充分开发的市场机会。播客创作者可以考虑探索这些领域,提供独特的内容,以吸引特定的听众群体。
完整代码👇
https://www.heywhale.com/mw/project/660415ee17be047adfec00ee
ps:访问链接点击【在线运行】即可查看完整代码,且不需要担心环境配置问题
数据集下载
关注公众号,回复关键字【中文播客榜单】获取
- END -
以上就是本期为大家整理的全部内容了,喜欢的朋友可以点赞、点在看也可以分享让更多人知道。

👆 关注**「布鲁的Python之旅」**第一时间收到更新















 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









