







文章目录
1、计算机组成
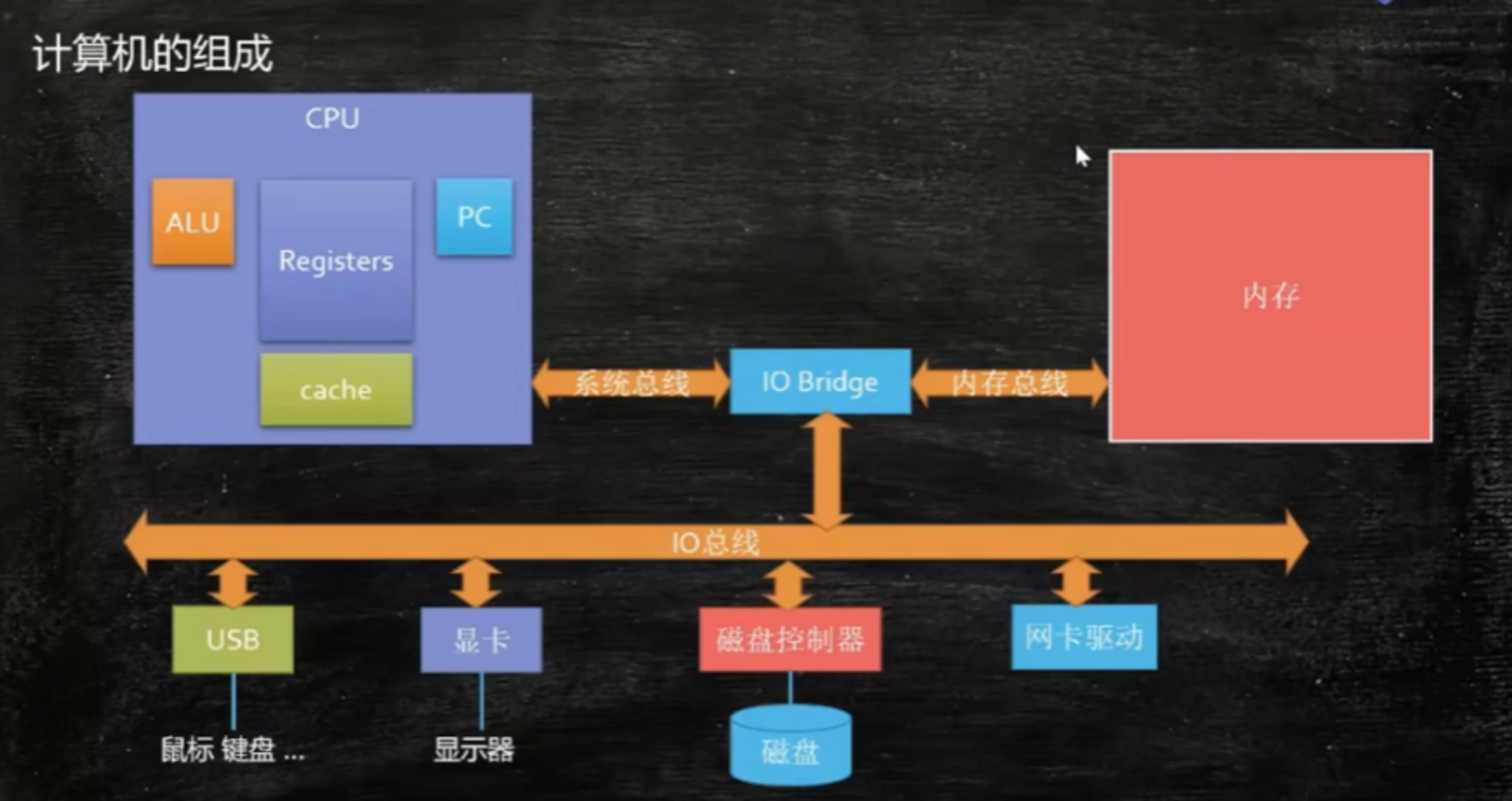
CPU = ALU + PC + Registers + cache
- ALU ——> 运算单元/算数逻辑单元
- 计算寄存器的数据,然后写回到内存
- PC(program counter) ——> 指令寄存器 /程序计数器
- 存放下一条指令的地址
- Register ——> 寄存器
- 在PC找到指令的地址,读进指令后,发现该指令需要数据,将数据放到寄存器(registers)
- cache ——>缓存(redis)
CPU通过总线从内存中读数据
2、存储器的层次结构
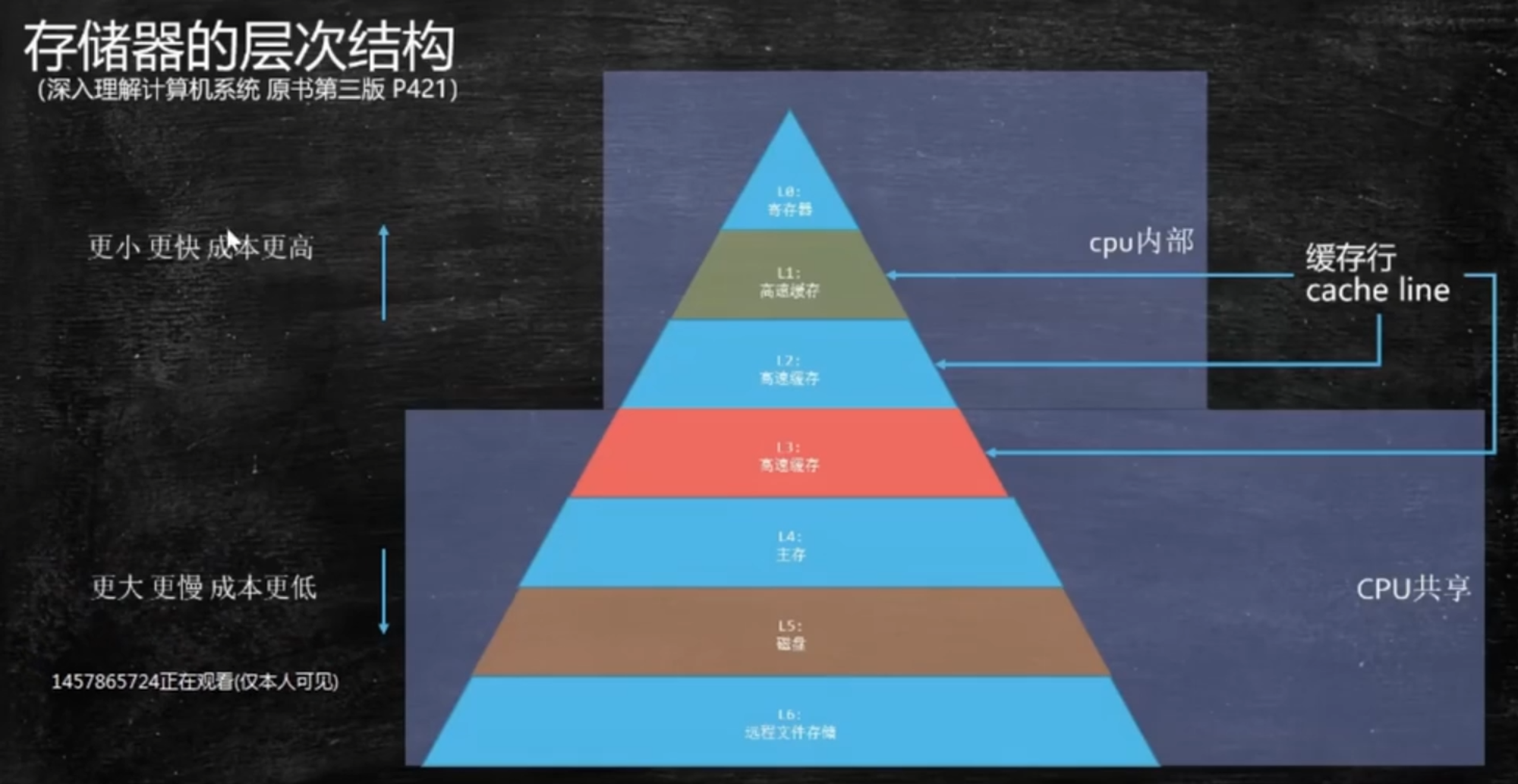
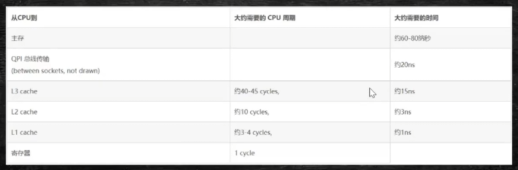
从L0到L4,速度大概相差100倍
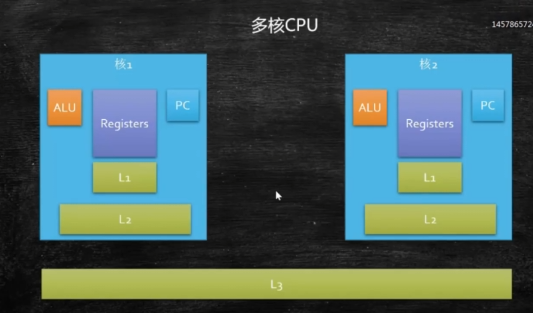
- 多核CPU
- 一个GPU中存在多个核,每个核中包含1级、2级缓存。所有核共享3级缓存。
- 在进行数据查找时,查找顺序为L1、L2、 L3.
- 超线程
- 一个运算单元,两组线程对应的资源单元(核中包含两组PC、两组寄存器),来提高效率。
- 四核八线程:就是有4 个ALU,每个和里有两组寄存器和PC
3、cache line 的概念 缓存行对齐 伪共享
- 计算机通过内存总线从内存读数据,是一块一块的读取的,每一块叫cache line
- 英特尔的CPU,一个cache line 也就是一个缓存行是64个字节(bite)
- 当ALU计算需要数据时(比如是数据x),依次在L1、L2、L3中寻找, 没有就会去内存读取,将“x,y"这一缓存行同时读进来,这时,当ALU处理完数据x后,需要y时,发现y和x被同时读进内核了,这时的运算速度会大大提升
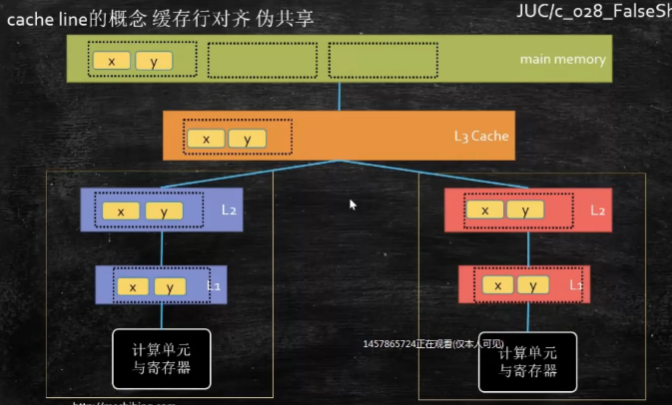
- 这时存在一个问题,缓存保持一致
- 针对两个线程使用同一缓存行的数据,一个在使用其中的x, 一个在使用y,如果其中一个对x进行了更改,要求另一个线程必须可见,通知另一个线程可见的这种操作就叫 缓存一致性协议,保证缓存行的数据在不同线程中保持一致.
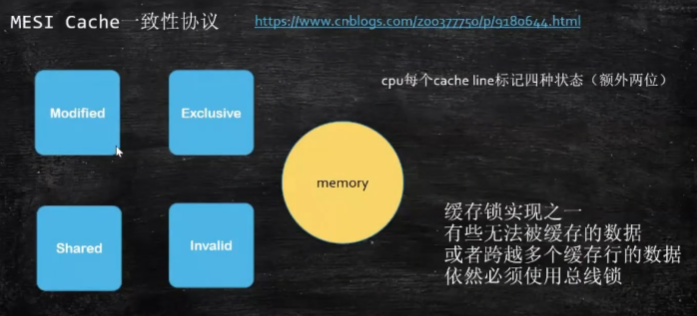
- 针对两个线程使用同一缓存行的数据,一个在使用其中的x, 一个在使用y,如果其中一个对x进行了更改,要求另一个线程必须可见,通知另一个线程可见的这种操作就叫 缓存一致性协议,保证缓存行的数据在不同线程中保持一致.
- 缓存行的4中状态MESI:
- Modified:被修改
- Exclusive:独享
- Shared:分享,只读不写
- Invalid:失效
这时的一个流程就是,当一个线程中的x被修改,此时该缓存行的状态会被更改为Modified,内核会通过缓存锁去告知另一个线程,他的缓存行Invalid,它需要从内存中重新读取。
4、CPU乱序执行的概念
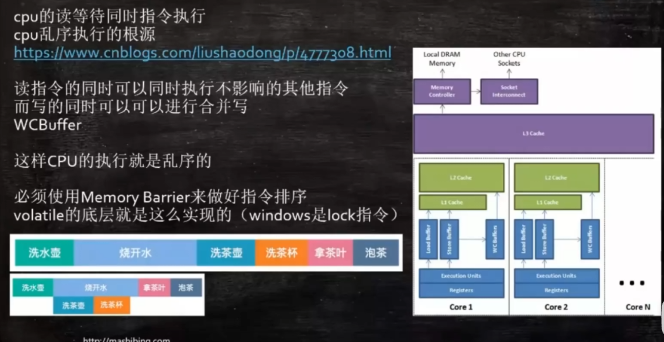
比如在多核CPU同时运行时,是不允许乱序执行的,这时Java使用volatile来实现不允许乱序执行
- volatile的核心两点:
- 线程之间的可见性
- 禁止CPU的乱序执行
- cpu的乱序执行
- 在JVM层级是要通过内存屏障来实现,来防止它乱序执行
- 到虚拟机这个层级、C++这个层级,实际上是通过一条汇编指令,通过lock这条指令来完成的
4.1 一道面试题:DCL(Double Check Lock双重检查锁)单例模式要不要加volatile
-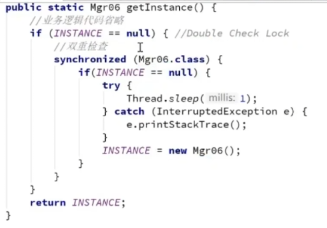
先判断INSTANCE是否为空,然后上锁,然后再次检查INSTANCE是否为空,这是为了防止该线程在上锁期间其他线程执行了INSTANCE = new Mgr06()
- DCL(Double Check Lock双重检查锁)单例模式要加volatile

-
对象的创建过程
- 0 new #2 //在内存中申请一个对象,分配了一块内存,内存中的m为初始值0。
- 4 invokespecial #3 <T.> //执行该句后,m被赋值为8。
- astore_1 //执行该句后 t 和 才会和真正的对象建立关联。

-
若不使用volatile进行禁止指令重排序,则在DCL单例new对象时,发生指令乱序,先使变量和内存建立连接,然后没等进行下一步的初始化时,下面的程序就进行了变量是否为null的判断,并使用这个半初始化状态的对象继续向下执行,导致程序出现错误。
内存屏障 -
JVM级内存屏障:

- JSR内存屏障
- LoadLoad屏障:
- StoreStore屏障:
- LoadStore屏障:
- StoreLoad屏障:
- JSR内存屏障
-
硬件级内存屏障:
4.2 合并写技术
- 计算单元AUL和L1缓存中间还有一个缓存,叫WC_buffer(WriteCombing, 合并写),它只有4个字节。
- 合并写:当CPU需要写回一个值到内存或缓存时,内存会首先把这些值存在WC_buffer中,这个缓存四字节满了之后,一次性把这四个字节写到L1中。
5、程序运行的底层原理
- 程序:qq.exe, PowerPoint.exe
- 进程:资源分配的基本单位。(程序启动、进入内存。比如,双击qq.exe,这时就会将磁盘中的数据(指令和代码)传给内存,)
- 线程:程序执行的基本单位(从main线程开始执行)
- 程序如何开始运行
- CPU读指令 PC,读数据 Register, 计算 ALU ,回写,-> 下一条
- 线程如何进行调度
- 线程调度器(操作系统、OS)
- 线程切换的概念
- Context Switch CPU保存现场 ,执行新线程,恢复现场,继续执行原线程这样的一个过程
用户级线程(JVM线程)和操作系统级线程(也就是内核级线程)
- Context Switch CPU保存现场 ,执行新线程,恢复现场,继续执行原线程这样的一个过程
- 一个JVM线程对应一个内核级线程 1:1
- go语言中叫协程,它和内核级线程是m:n的关系,且m远远大于n
6、锁
6.1 锁的概念
- 锁的概念:对线程上锁就是,只有等这个线程执行结束,别的线程才能执行
- 不持有锁的线程怎么办:忙等待(自旋锁,也叫轻量级锁),等待队列(需要经过操作系统调度,也叫重量级锁)
- 自旋锁一定比重量级锁的效率高吗?不是,当线程执行时间长,且线程多时,选择重量级锁,等待系统的调度
6.2 synchronized关键字
synchronized从重量级锁到自旋锁到现在更加复杂的锁
6.2.1 自旋锁的核心——CAS(compareAndSwap )
- 在进行m++时,从内存读取数m给ALU,然后在往回写入时判断,要往回写入的数和内存中的数是否一样,如果不一样,将其存入,一直运行到两个数相同
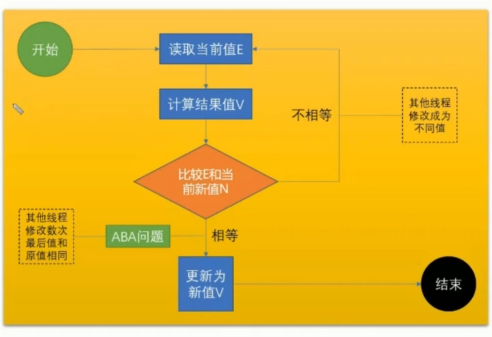
- 存在的两个问题:(针对多核cpu,单核不存在这个问题)
- ABA问题: (我们将内存的0送入ALU计算为1,现在将1重新写入内存,这时进行判断,内存是0与1不等。在判断时存在一个问题,判断时的0是读进ALU的0么,这个0可能是经历了其他线程变成8后又变为0,这就是ABA问题)
- 解决方法:为其加个版本号(也就是为内存0加个版本号)
- CAS修改值时候的原子性问题:(我们将内存的0送入ALU计算为1,现在将1重新写入内存,这时进行判断内存0还是0,这是将内存0赋值为1。但是现在出现一个问题就是,在判断0是0后,0变1之前,内存0被另外一个线程赋值为8了,这时候怎么办),这时候需要保证他是原子性的,怎么保证的呢?
- lock cmpxchg 指令 //汇编指令 CPU采用CAS的方式去访问内存的指令
- lock 是用来锁总线, 来保证cmpxchg的原子性
- lock cmpxchg 指令 //汇编指令 CPU采用CAS的方式去访问内存的指令
- ABA问题: (我们将内存的0送入ALU计算为1,现在将1重新写入内存,这时进行判断,内存是0与1不等。在判断时存在一个问题,判断时的0是读进ALU的0么,这个0可能是经历了其他线程变成8后又变为0,这就是ABA问题)
6.2.2 偏向锁
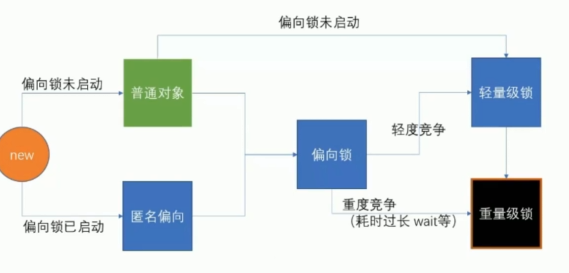
- 偏向锁的概念:
- 偏向锁不是锁。是第一个线程过来,不用启动锁竞争,就能使用,但是只要有其他资源过来竞争,就要进行锁升级
- 他是为了那些在百分之七八十的时间,只有一个线程在运行synchronized的代码所设计的一把锁
- 如果没有偏向锁,每次即使只过来一个线程也要启动锁竞争,过于浪费时间。
- 深入理解Java锁升级:无锁 → 偏向锁 → 轻量级锁 → 重量级锁 https://blog.csdn.net/qq_40722827/article/details/105598682
- JOL(Java Object Layout, Java 对象布局)
- Object o = new Object()
- new一个新对象它占16个字节:
- markword(8个字节)
- classpointer(4个字节):new出来的对象属于哪一个类的,也可以认为他是只想object.class的指针
- 后面4个字节是,存放成员变量,如果没有,留着对齐(对齐:如果不能被8整除,就变成能被8整除)
- new一个新对象它占16个字节:
- Object o = new Object()















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









