








Pandas有2种数据结构,分别是Series和DataFrame
1.Series
Series类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型
Series由索引(index)和列组成
提示
索引起到解释、定位数据的作用,Series是Pandas最基础的数据结构
语法
import pandas as pd
pd.Series(data, index, dtype, name, copy)参数说明
data: 一组数据(ndarray类型)
index: 数据索引标签,如果不指定,默认从0开始
dtype: 数据类型,默认会自己判断
name: 设置名称
copy: 拷贝数据,默认为False
实例
import pandas as pd
arr = [1, 2, 3]
res1 = pd.Series(arr)
# 根据索引值读取数据
res1[1] # 2
# 指定索引值
res2 = pd.Series(arr, index = ['x','y','z'])
# 根据索引值读取数据
res2['y'] # 2
res1
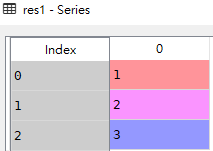
从上图可知,如果没有指定索引,索引值就从0开始
res2
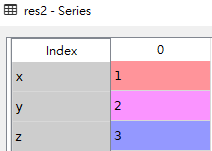
使用key/value对象,类似字典来创建Series
import pandas as pd
dicts = {1: "Odin", 2: "Jack", 3: "Lee"}
res3 = pd.Series(dicts)res3

从上图可知,字典的key变成了索引值
如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可
import pandas as pd
dicts = {1: "Odin", 2: "Jack", 3: "Lee"}
res4 = pd.Series(dicts, index = [1, 2])res4

设置Series名称参数
import pandas as pd
dicts = {1: "Odin", 2: "Jack", 3: "Lee"}
pd.Series(dicts, index = [1, 2], name='Hudas')
未设置Series名称参数
import pandas as pd
dicts = {1: "Odin", 2: "Jack", 3: "Lee"}
pd.Series(dicts, index = [1, 2])
2.DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)
DataFrame既有行索引也有列索引,它可以被看做由多个Series组成的字典(共同用一个索引)
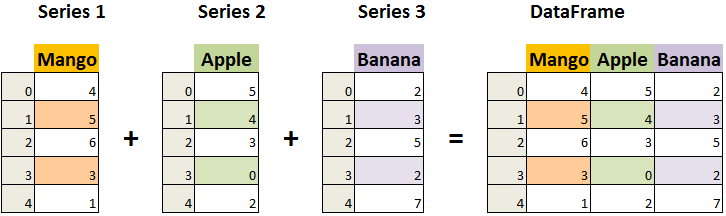
DataFrame是Pandas定义的一个二维数据结构
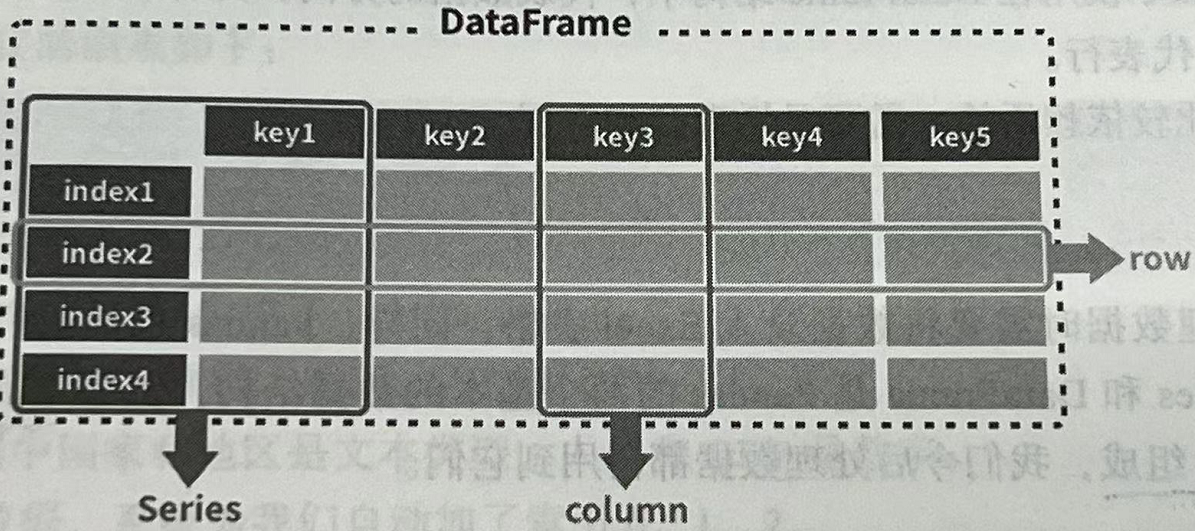
横向的称作行(row),一条数据就是指其中的一行
纵向的称作列(column)或字段,是一条数据的某个值
第一行是表头或者叫字段名,类似于Python字典里的键,代表数据的属性
第一列是索引,就是这行数据所描述的主体,也是这条数据的关键
在一些场景下,表头称为列索引,索引称为行索引
语法
import pandas as pd
pd.DataFrame(data, index, columns, dtype, copy)参数说明
data: 一组数据(ndarray、series, map, lists, dict 等类型)
index: 索引值,或者可以称为行标签
columns: 列标签,默认为 RangeIndex (0, 1, 2, …, n)
dtype: 数据类型
copy: 拷贝数据,默认为 False
2.1 使用列表创建DataFrame
import pandas as pd
data = [['Odin',11],['Harry',12],['Lee',13]]
df1 = pd.DataFrame(data,columns=['Name','Age'],dtype=float)df1

2.2 使用ndarrays创建DataFrame
import pandas as pd
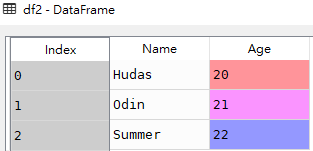
data = {'Name':['Hudas', 'Odin', 'Summer'], 'Age':[20, 21, 22]}
df2 = pd.DataFrame(data)df2
2.3 使用字典key/value创建DataFrame
import pandas as pd
# 字典的key为列名
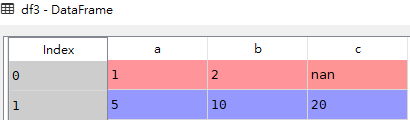
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df3 = pd.DataFrame(data)df3
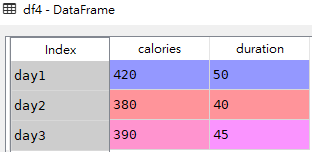
import pandas as pd
data1 = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df4 = pd.DataFrame(data1, index = ["day1", "day2", "day3"])df4















 7637
7637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









