







彩票假设
一、基本概念
彩票假设(Lottery Ticket Hypothesis)是由 Jonathan Frankle 和 Michael Carbin 在 2019 年的论文《The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks》中提出的一个关于深度神经网络的有趣观察和理论。
1. 核心观点
一个随机初始化、稠密(dense)的、前馈神经网络中,包含一个子网络 (subnetwork),这个子网络在初始化时就具备了在整个网络训练相同轮数后所能达到的相当甚至更好的性能,而无需重新学习权重。这个子网络被称为“中奖彩票 (winning ticket)”。
更通俗地讲, 想象你买了一大堆彩票(一个大的、随机初始化的神经网络)。其中大部分彩票都不会中奖(大部分子网络性能不佳)。但是,彩票假设认为,在这堆彩票中,隐藏着一些“中奖彩票”——这些子网络天生就具有好的权重配置(在初始化的那一刻),如果只训练这些子网络(保持其初始权重值,或者用初始权重重新训练),它们就能达到甚至超过训练整个大网络的性能。
2. 关键要素
(1) 子网络 (Subnetwork): 通过对原始稠密网络的权重进行剪枝(pruning)得到。剪枝通常是将一部分权重设置为零。
(2) 初始化权重 (Initial Weights): “中奖彩票”的特殊之处在于,它的性能与它在原始网络中的初始权重值密切相关。如果将这些“中奖彩票”的结构(哪些权重保留,哪些权重置零)提取出来,然后用随机的新权重重新初始化,它们通常表现不佳。必须使用它们在原始网络中的初始权重(或者至少是接近初始权重的配置)才能“中奖”。
(3) 稀疏性 (Sparsity): “中奖彩票”通常是高度稀疏的,意味着它们只包含原始网络中一小部分的权重。
二、彩票假设的用途
如果彩票假设被广泛证实并能有效地应用于各种网络和任务,它将带来许多潜在的实践用途:
- 模型压缩 (Model Compression):
- 可以直接找到并部署这些稀疏的“中奖彩票”,从而大幅减小模型大小,降低存储需求和传输成本。这对于资源受限的设备(如移动设备、嵌入式系统)尤为重要。
- 加速推理 (Faster Inference):
- 稀疏网络的计算量远小于稠密网络,因此可以显著提高模型的推理速度。
- 降低训练成本 (Potentially Reduced Training Cost):
- 虽然找到“中奖彩票”本身需要训练和剪枝的过程,但一旦找到,如果可以直接使用其初始权重或进行少量微调,可能会比从头训练一个同样大小的稀疏网络更快。
- 更进一步的探索是,是否能直接在初始化阶段就识别出这些“中奖彩票”的结构,从而避免昂贵的“训练-剪枝-重置权重”循环。
- 更好的网络初始化策略 (Better Initialization Strategies):
- 理解为什么某些初始权重配置能够形成“中奖彩票”,可能有助于设计出更好的网络初始化方法,使得网络更容易训练,或者更容易找到高性能的稀疏子网络。
- 理解神经网络的工作原理 (Understanding Neural Networks):
- 彩票假设为我们提供了一个新的视角来理解神经网络的训练过程和泛化能力。它表明,网络结构和初始权重的相互作用可能比我们之前想象的更为重要。网络可能不是在从随机状态“学习”一切,而是在“选择”和“放大”已经存在的有利结构。
- 自动化网络结构搜索 (Automated Architecture Search):
- 寻找“中奖彩票”的过程可以看作是一种特殊的网络结构搜索方法,它专注于在给定的大网络中寻找最优的稀疏结构。
三、训练流程
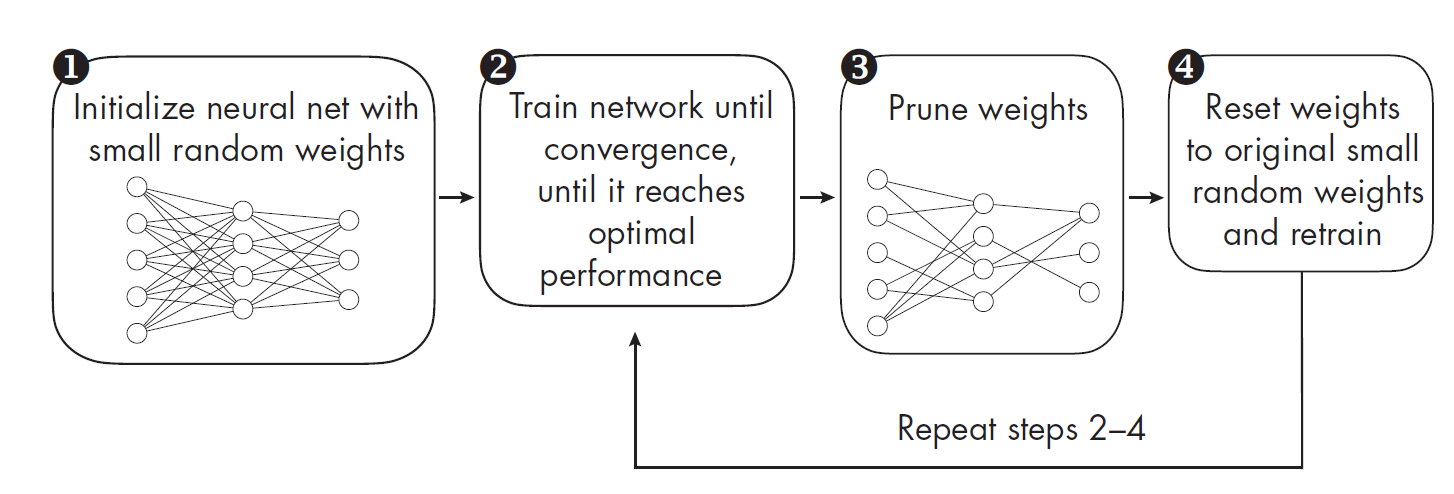
原始论文中提出的寻找“中奖彩票”的典型流程(迭代式幅度剪枝,Iterative Magnitude Pruning, IMP):
- 初始化 (Initialize): 随机初始化一个稠密的神经网络 f ( x ; θ 0 ) f(x; \theta_0) f(x;θ0),其中 θ 0 \theta_0 θ0 是初始权重。
- 训练 (Train): 将网络训练 j j j 轮,得到权重 θ j \theta_j θj。
- 剪枝 (Prune): 根据权重的大小(magnitude)对网络进行剪枝。将 p % p\% p% 的权重中绝对值最小的那些权重置零,得到一个剪枝后的掩码 (mask) m m m。
- 重置 (Reset): 将未被剪枝的权重重置回它们在步骤 1 中的初始值 θ 0 \theta_0 θ0。即,得到一个新的权重集 θ 0 ′ = m ⊙ θ 0 \theta'_0 = m \odot \theta_0 θ0′=m⊙θ0( ⊙ \odot ⊙ 表示元素对应相乘)。
- 重复 (Repeat): 以 θ 0 ′ \theta'_0 θ0′ 作为新的初始权重,重复步骤 2-4,直到达到期望的稀疏度。
关键点在于步骤 4 的“重置”操作。 这就是彩票假设的核心:保留下来的子网络的结构很重要,并且这个结构与原始的初始权重相结合才能发挥作用。
参考 《Machine Learning Q and AI 30 Essential Questions and Answers on Machine Learning and AI》,其流程图如下:
变种和后续研究:
- One-shot Pruning: 一次性剪枝到目标稀疏度,然后重置权重。
- Pruning at Initialization: 一些研究试图在训练开始前,甚至在初始化阶段就识别出潜在的“中奖彩票”结构,以避免完整的训练-剪枝循环。
- Winning Ticket without Resetting (Supermasks): 一些研究发现,在某些情况下,即使不重置回初始权重,而是继续训练剪枝后的网络,也能找到性能良好的稀疏网络,但这通常不被认为是严格意义上的“彩票假设”所描述的现象。
- Transferability of Tickets: 研究“中奖彩票”是否可以从一个任务迁移到另一个任务,或者从一个数据集迁移到另一个数据集。
四、意义和局限性
1. 意义
(1) 挑战了传统认知: 传统上认为,大型网络的成功在于其巨大的参数量和从随机初始化开始学习的能力。彩票假设表明,有效的结构可能在初始化时就已经“编码”在网络中了,训练过程更像是在“发现”和“优化”这些结构。
(2) 推动了稀疏网络研究: 激发了对稀疏网络训练、剪枝算法以及网络初始化方法的新一轮研究热潮。
(3) 为模型效率提升提供了新思路: 如果能够高效地找到“中奖彩票”,将极大地推动模型在实际应用中的效率。
(4) 对理解泛化有潜在贡献: 为什么这些特定的稀疏子网络能够很好地泛化,是一个值得深入研究的问题。
2. 局限性
(1) 寻找成本高昂: 原始的迭代式剪枝和重置权重的过程非常耗时耗计算资源,因为它需要多次完整的训练过程。这使得在非常大的模型上寻找“中奖彩票”变得不切实际。
(2) 对超参数敏感: 寻找过程对学习率、剪枝比例、训练轮数等超参数比较敏感。
(3) “中奖彩票”的定义和稳定性:
* “中奖”的标准是什么?达到原始网络性能?还是超过?
* 找到的“彩票”是否对数据、初始化种子的微小变化稳定?
(4) 初始权重的重要性机制尚不完全清楚: 为什么必须是那些特定的初始权重值与特定的结构相结合才能成功,其背后的确切机制仍在探索中。
(5) 泛化到更复杂的结构和任务: 彩票假设最初主要在图像分类任务和标准的前馈网络上得到验证。它在更复杂的网络结构(如 Transformers, GNNs)和更复杂的任务(如自然语言处理、强化学习)上的普适性和有效性仍在研究中,结果不尽相同。
(6) 与从头开始训练稀疏网络的比较: 一些研究表明,精心设计的从头开始训练稀疏网络的算法,有时也能达到与“中奖彩票”相当甚至更好的性能,且训练成本更低。这使得“重置回初始权重”的必要性受到了一些质疑。
(7) 硬件支持: 当前的深度学习硬件(如 GPU)对稠密计算优化得更好。高效执行高度稀疏且不规则的网络的硬件支持仍在发展中。即使找到了完美的稀疏网络,如果硬件不能有效利用其稀疏性,实际的加速效果也可能有限。
五、总结
彩票假设是一个引人入胜的理论,它揭示了深度神经网络中可能存在的、与初始化权重紧密相关的内在结构。它为模型压缩、加速和理解神经网络提供了新的视角。然而,寻找“中奖彩票”的成本、其普适性以及背后的机制仍是当前研究的重点和挑战。尽管存在局限性,彩票假设无疑推动了我们对深度学习更深层次的思考。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











