







介绍
本篇文章主要介绍如何爬取麦子学院的课程信息(本爬虫仍是单线程爬虫),在开始介绍之前,先来看看结果示意图
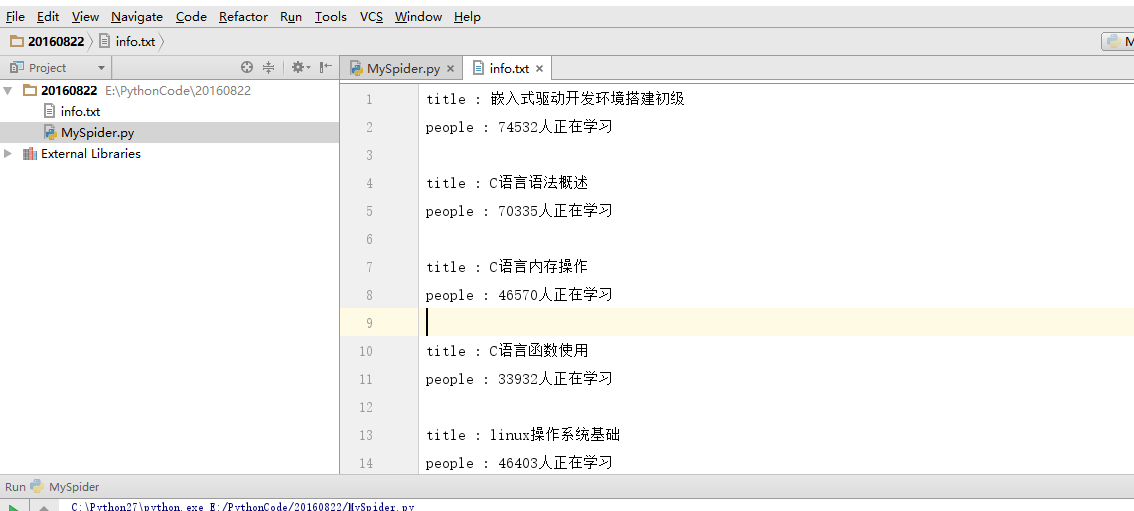
怎么样,是不是已经跃跃欲试了?首先让我们打开麦子学院的网址,然后找到麦子学院的全部课程信息,像下面这样
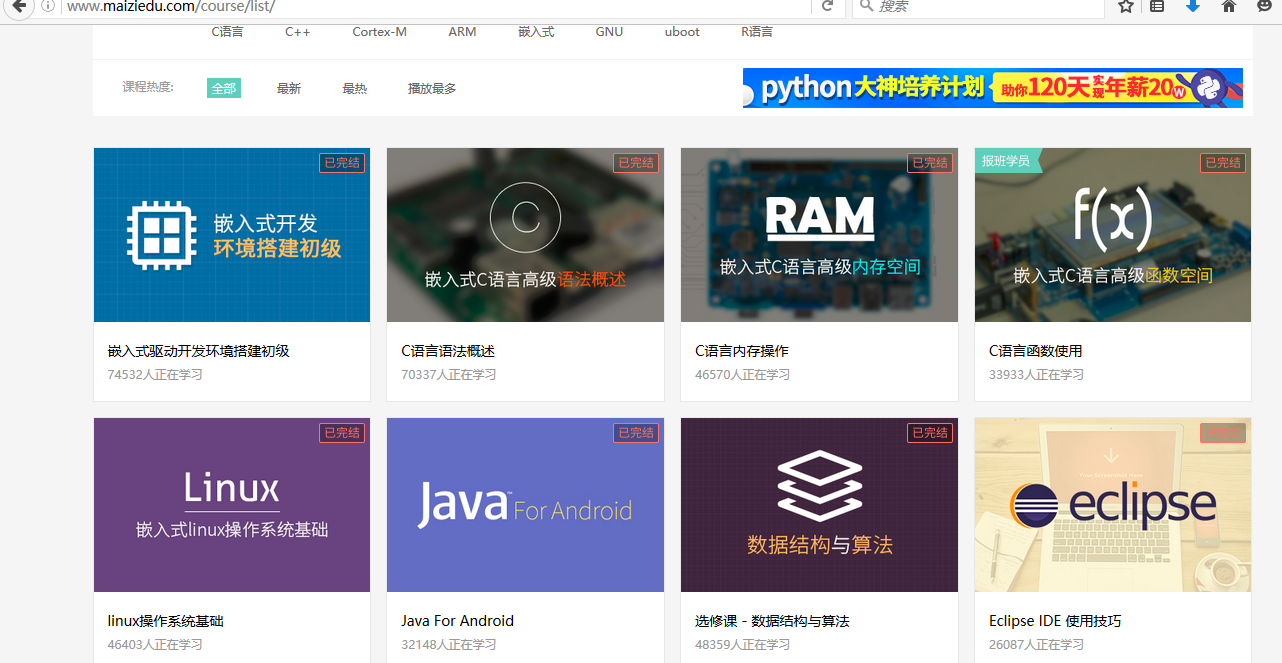
这个时候进行翻页,观看网址的变化,首先,第一页的网址是 http://www.maiziedu.com/course/list/, 第二页变成了 http://www.maiziedu.com/course/list/all-all/0-2/, 第三页变成了 http://www.maiziedu.com/course/list/all-all/0-3/ ,可以看到,每次翻一页,0后面的数字就会递增1,然后就有人会想到了,拿第一页呢?我们尝试着将 http://www.maiziedu.com/course/list/all-all/0-1/ 放进浏览器的地址栏,发现可以打开第一栏,那就好办了,我们只需要使用 re.sub() 就可以很轻松的获取到任何一页的内容。
获取到网址链接之后,下面要做的就是获取网页的源代码,首先右击查看审查或者是检查元素,就可以看到以下界面
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









