






一、安装JAVA环境
1、下载jdk安装包
【jdk-8u152-linux-x64.tar.gz】这里的安装包可以从官网下载(官网地址:https://www.oracle.com/java /technologies /javase-jdk8-downloads.html)
2、卸载自带的安装包
[root@master ~]# rpm -qa | grep java
卸载相关服务,键入命令 rpm –e –-nodeps 删除的包
[root@master ~]# rpm -qa | grep java
[root@master ~]# java --version
bash: java: 未找到命令3、解压安装包
安装JDK【将安装包解压到/usr/local/src 目录下,将安装包放在了root目录下】
[root@localhost ~]# ls
anaconda-ks.cfg jdk-8u152-linux-x64.tar.gz
[root@localhost ~]# tar -zxvf jdk-8u152-linux-x64.tar.gz -C /usr/local/src/
jdk1.8.0_152/
jdk1.8.0_152/javafx-src.zip
jdk1.8.0_152/bin/
jdk1.8.0_152/bin/jmc
。。。。。。
[root@localhost ~]# ls /usr/local/src/
jdk1.8.0_152
[root@localhost ~]#


4、配置Java环境
1)配置文件
[root@localhost ~]# vi /etc/profile
【在配置文件最后加入以下两行:
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin】
使配置变量生效
[root@localhost ~]# source /etc/profile
2)检查Java是否可用
[root@localhost ~]# echo $JAVA_HOME /usr/local/src/jdk1.8.0_152
/usr/local/src/jdk1.8.0_152 /usr/local/src/jdk1.8.0_152
[root@localhost ~]# java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
[root@localhost ~]# 【能够正常显示 Java 版本则说明 JDK 安装并配置成功。】
二、实现免密登录
1)创建ssh秘钥,输入如下命令,生成公私密钥
[root@localhost ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2)将master公钥id_dsa复制到master进行公钥认证,实现本机免密登陆,测试完exit退出
[root@localhost ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub master
[root@master ~]# ssh master
Last login: Sun Apr 28 21:54:05 2024 from 192.168.130.1
[root@master ~]# exit
登出
Connection to master closed.
[root@master ~]#
三、Hadoop环境的安装与配置
1、解压安装包
将/root下的hadoop-2.7.7.tar.gz压缩包解压到/opt目录下,并将解压文件改名为hadoop
[root@master ~]# ls
anaconda-ks.cfg hadoop-2.7.1.tar.gz jdk-8u152-linux-x64.tar.gz
[root@master ~]# tar -zxvf hadoop-2.7.1.tar.gz -C /opt/
[root@master opt]# mv hadoop-2.7.1 hadoop
[root@master opt]# ls
hadoop soft
[root@master opt]# 2、修改配置文件
[root@master ~]# vi /etc/profile
【在文件最后添加以下两行:
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin】
使配置文件生效
[root@master ~]# source /etc/profile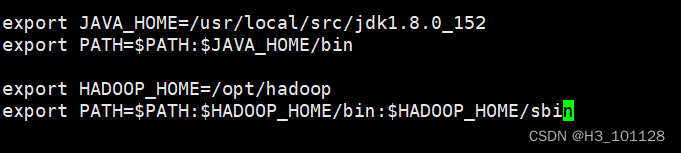
3、编辑/opt/hadoop/etc/hadoop/hadoop-env.sh文件
[root@master ~]# cd /opt/hadoop/etc/hadoop/
[root@master hadoop]# vi hadoop-env.sh
修改配置文件为jdk的安装路径:
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
4、编辑core-site.xml文件
[root@master hadoop]# vi core-site.xml
【文件中加入以下内容】
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
</configuration>
5、编辑hdfs-site.xml文件
[root@master hadoop]# vi hdfs-site.xml
【在文件中加入以下内容】
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
6、编辑mapred-site.xml文件
将mapred-site.xml.tmplate改名为mapred-site.xml
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
【在文件中加入以下内容】
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
7、编辑yarn-site.xml文件
[root@master hadoop]# vi yarn-site.xml
【在文件中加入以下内容】
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8、编辑slaves文件
[root@master hadoop]# vi slaves
【在文件中写入以下内容】
master9、格式化hdfs
[root@master ~]# hdfs namenode -format

10、启动集群 jps查看,登录网页
[root@master ~]# start-all.sh
[root@master ~]# jps
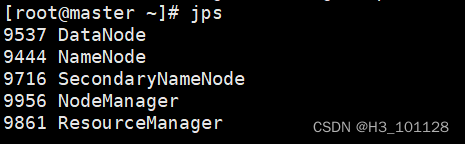
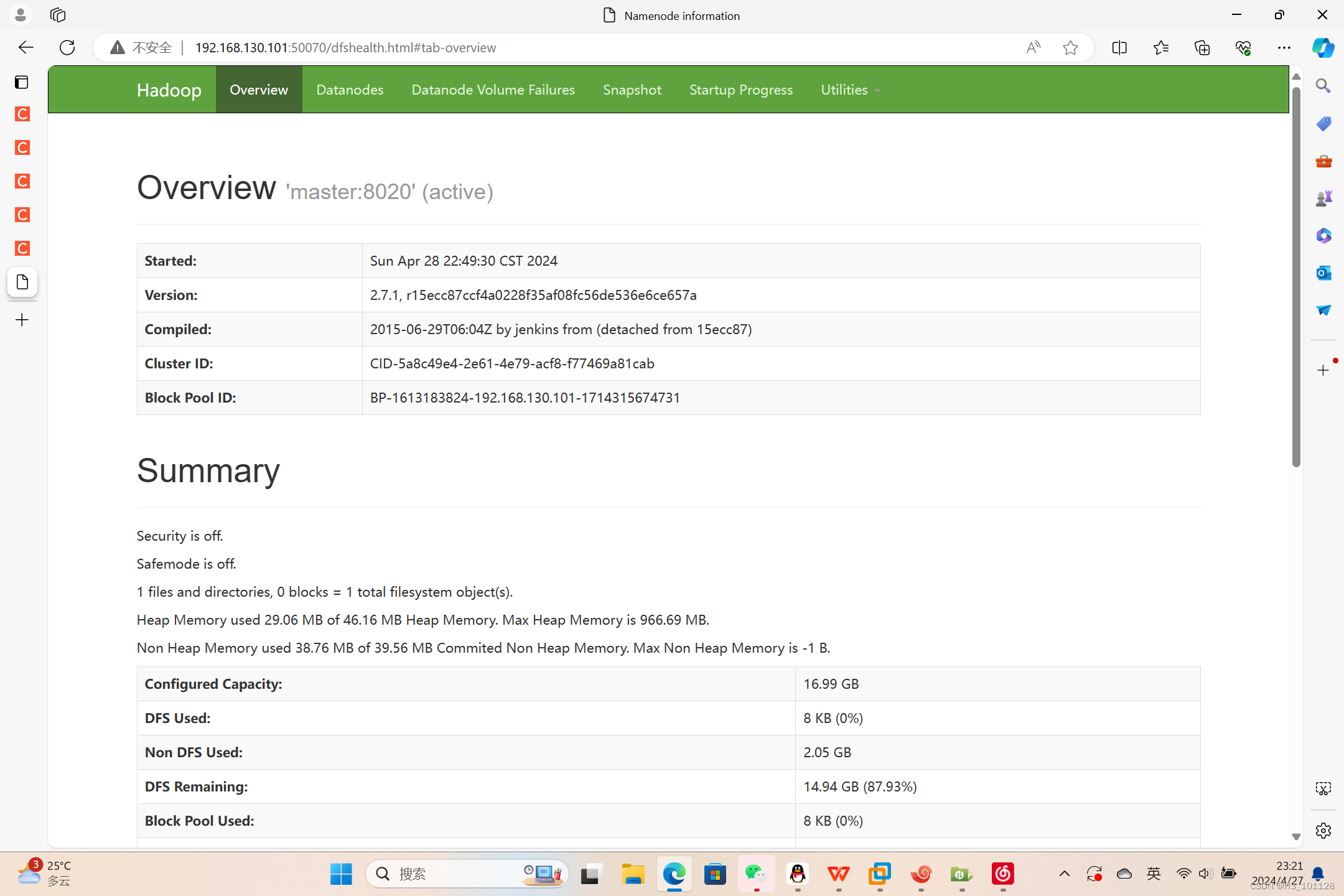
【在浏览器的地址栏输入http://192.168.130.101:50070,进入页面可以查看NameNode和DataNode 信息】
四、安装伪分布式spark
1、解压安装包
将root目录下的安装包解压到/usr/local/src目录下
[root@master ~]# tar -zxvf spark-3.2.1-bin-hadoop2.7.tgz -C /usr/local/src/
2、将spark-env.sh.template复制和重命名后得到spark-env.sh,打开spark-env.sh添加内容
[root@master ~]# cd /usr/local/src/spark-3.2.1-bin-hadoop2.7/conf/
[root@master conf]# cp spark-env.sh.template spark-env.sh
[root@master conf]# vi spark-env.sh
【在文件中加入以下内容】
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export SPARK_MASTER_IP=master
export SPART_LOCAL_IP=master
3、进入spark目录的/sbin下启动spark集群,jps查看
[root@master conf]# cd /usr/local/src/spark-3.2.1-bin-hadoop2.7/sbin/
[root@master sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/src/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/src/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-master.out
[root@master sbin]# jps
9537 DataNode
9444 NameNode
9716 SecondaryNameNode
9956 NodeManager
9861 ResourceManager
10503 Worker
10569 Jps
10447 Master
[root@master sbin]#
4、启动spark-ahell
[root@master sbin]# cd /usr/local/src/spark-3.2.1-bin-hadoop2.7/
[root@master spark-3.2.1-bin-hadoop2.7]# ./bin/spark-shell
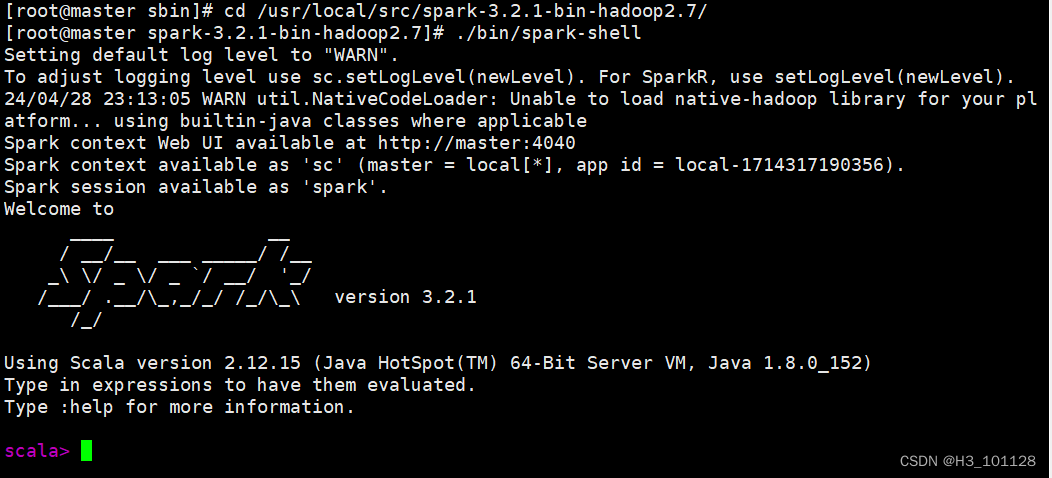
5、查看网页http://192.168.130.101:8080
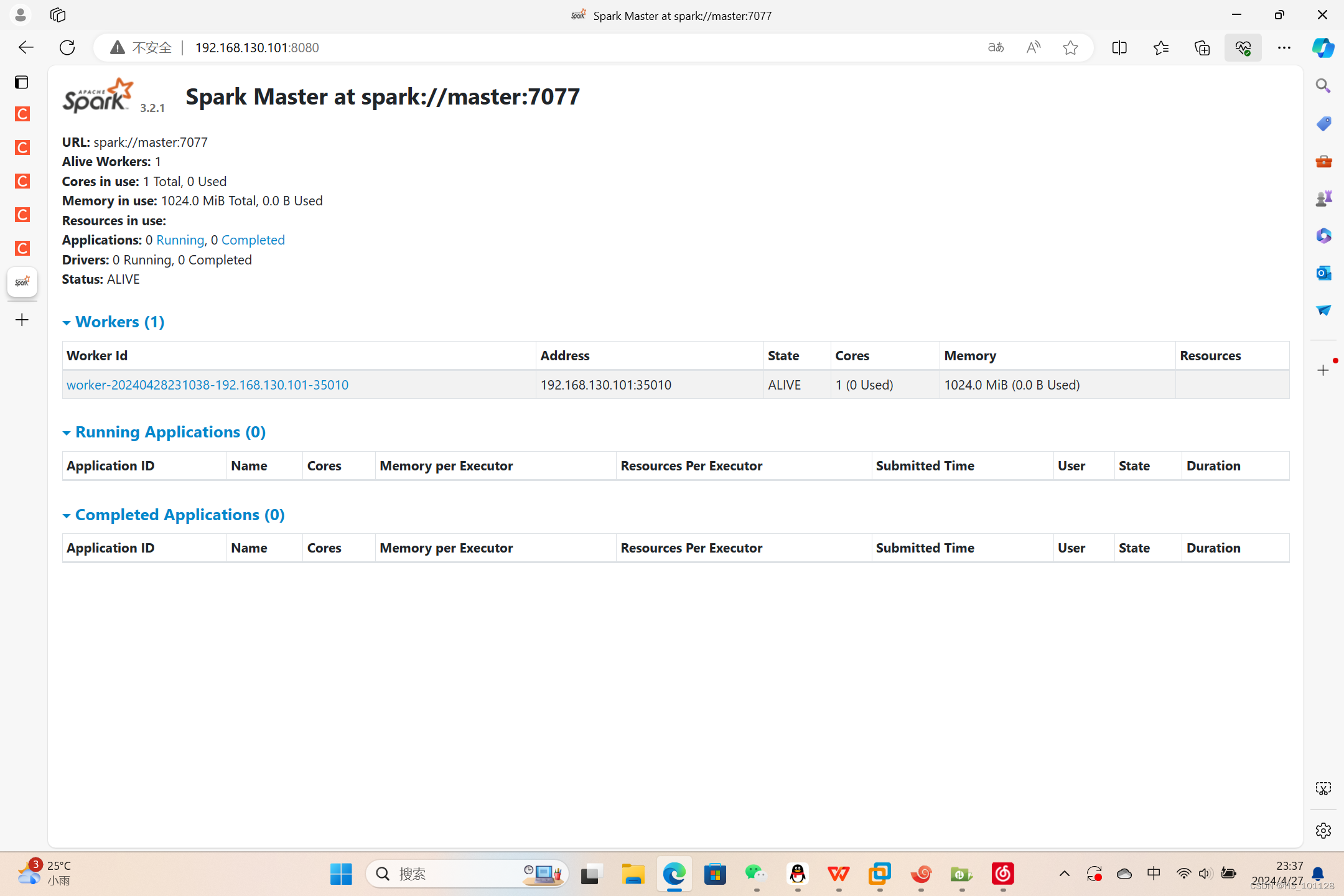
五、安装伪分布式scala
1、解压安装包
【将root目录下的安装包解压到/usr/local/src目录下】
[root@master ~]# tar -zxvf scala-2.11.8.tgz -C /usr/local/src/
2、配置scala环境变量,重新加载配置文件,运行scala
[root@master ~]# vi /etc/profile
【在文件最后加入以下两行内容】
export SCALA_HOME=/usr/local/src/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
使配置文件生效
[root@master ~]# source /etc/profile
3、检查Scala是否生效
















 1425
1425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









