







Motivation
以往的跨模态检索工作都是一对一映射关系,对于语义不明或者多语义的文本和视觉图像/视频效果不好,下图是一个例子,文本中表达的含义和视频中表达的含义非常模糊的,再比如一句话只是描述了图像中某一个区域,作者提出使用一对多的方法,将单例(文本或者图像视频等)映射到多级特征中,分成K个表示,就是一对多的关系建模,并且通过local和global的方式去构建模型,对损失函数也做了相应修改,达到了更好的结果,并且提出了一种具有ambiguous特点的数据集MRW,这种数据集是:视频中是对一句话文本的反应。

Contribution
提出PIE-Net网络用以解决上述语意模糊、文本和图像视频部分关联的问题
证明了在image-text和video-text的有效性
提出了新的数据集用于开展视频和文本之间的关系存在语义不明这种新的方向
Method
首先需要理解下图,传统的方式是将video和text都变成一个向量,对完整的向量计算相似度,本文就提出一个实例可以用多个实例表针表示,视频和文本特征是多个,可能里面只有部分是相关联的,相当于放松了要求。

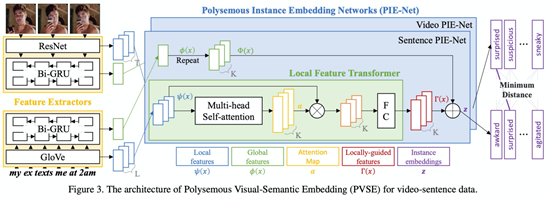
作者提出PVSE框架,同时利用局部特征和全局特征,文本和视频用的都是一样的PIE-Net网络,权重不共享,对于视频,每一帧输入预训练的网络得到每一帧的特征作为局部特征参与后续,并且将得到的这些特征参与双向GRU得到全局特征,后面通过local feture transfomer和残差学习得到最后的embedding。
损失函数有三项,包括用Multiple Instance Learning (MIL) framework的MIL loss、Diversity Loss和Domain Discrepancy Loss。

MRW数据集

这个数据集是直接从https://www.reddit.com/r/reactiongifs 做的,算是比较粗糙的
Experiments


可以看出在做的比较多的image-text的任务上指标还可以,但是在video-text的指标上都普遍很低,特别是MRW数据集,实际上跨模态的video-text也是2018年才开始的,发展也才刚起步,作者在paper中也说了这一点。
github:https://github.com/yalesong/pvse
可以参考:https://blog.csdn.net/m0_37169880/article/details/105437784
对视频进行二进制存储的一个代码库:https://github.com/TwentyBN/GulpIO















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









