







今日CS.CV 计算机视觉论文速览
Wed, 12 Jun 2019
Totally 52 papers
?上期速览✈更多精彩请移步主页

Interesting:
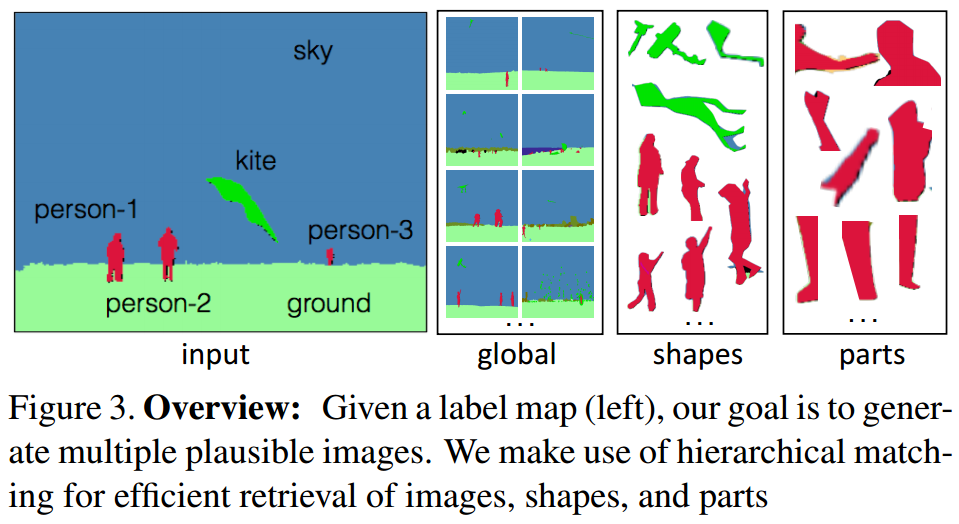
?Shapes and Context, 研究人员提出了一种从语义标签图合成图像以及操作图像内容的方法,具有丰富的适应性、可以合成十分高分辨的图像,这些图像具有合适的外形和视觉结果,可以通过这种方法合成丰富的图像资源。(from CMU)
输入语义图像,输出合成的彩色图像:
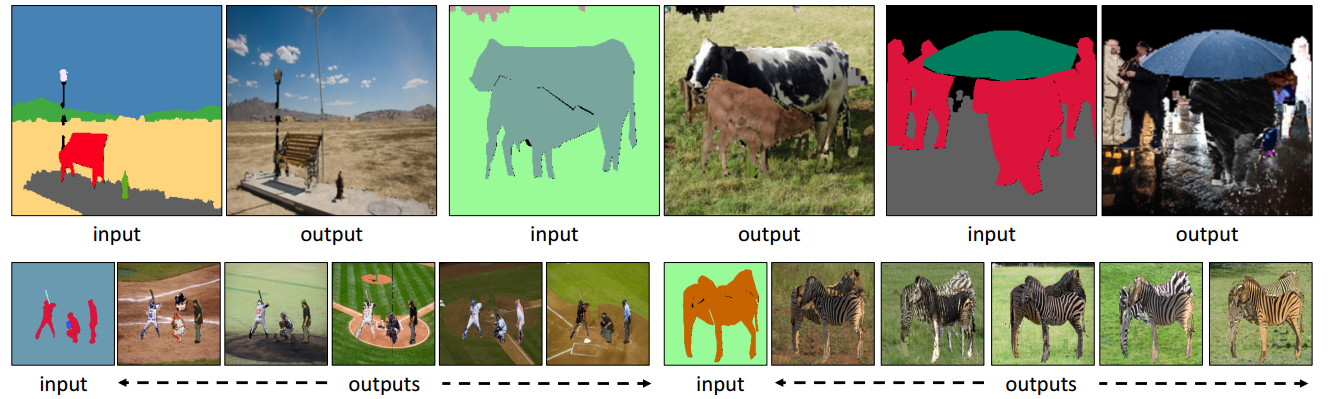
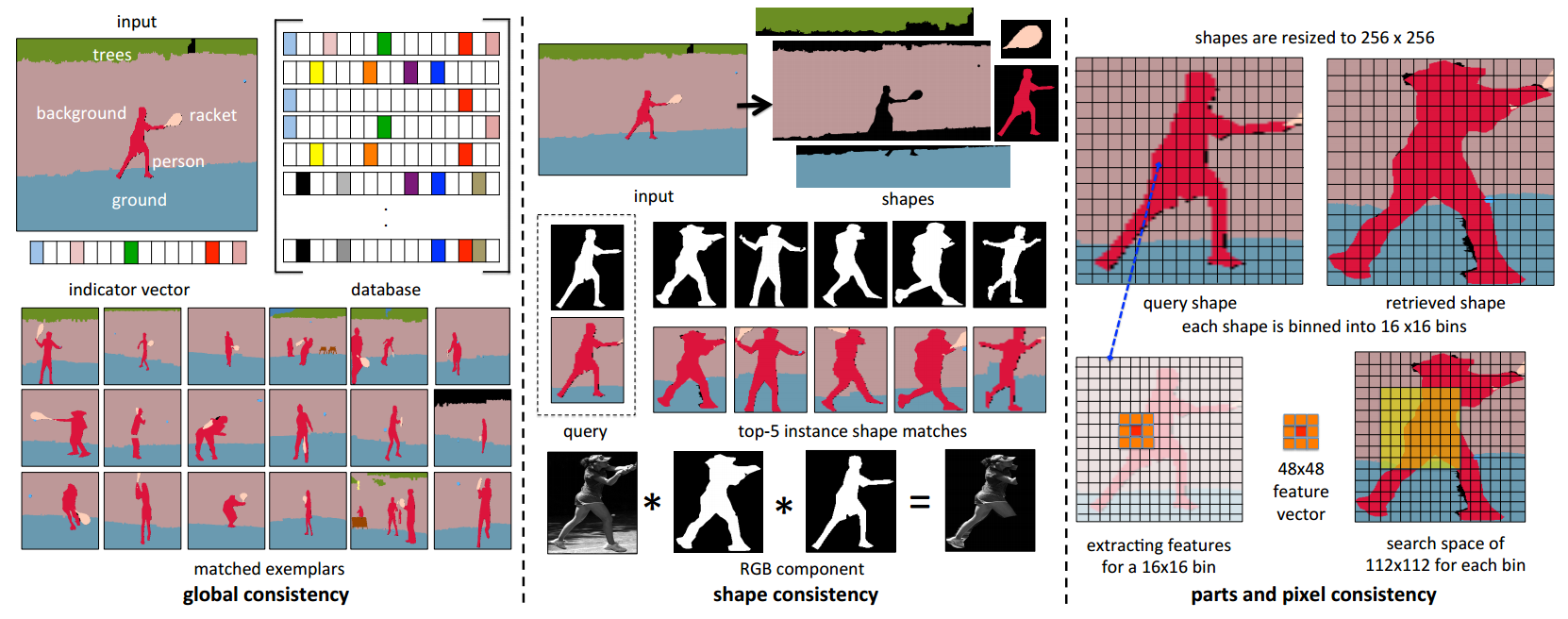
对于输入的语义图,研究人员提出了非参数的匹配方法来处理全局、外形、部分甚至像素的细节,以便合成出新的图像:
非参数匹配的过程主要分为四个步骤,首先利用知识矢量来从数据集中找到相关样本,随后利用形状连续性并基于形状和内容特征来寻找到最适合的掩膜,接着利用部分连续性和局域合成方法来补全细节的信息,最后在像素水平对图形进行处理:
一些合成的结果:

统一输入多个合成的输出:

图像插入元素的操作结果:

?三维场景中CAD模型检索与9DoF的匹配, 研究人员提出了一种对扫描场景中的物体进行6D位姿检测,并利用检测结果与对应的CAD模型进行匹配和对齐(symmetry-aware
object correspondences ,SOCs),随后将生成有效的CAD重建结果,包含干净的、完整的物体几何模型。(from 慕尼黑工大)
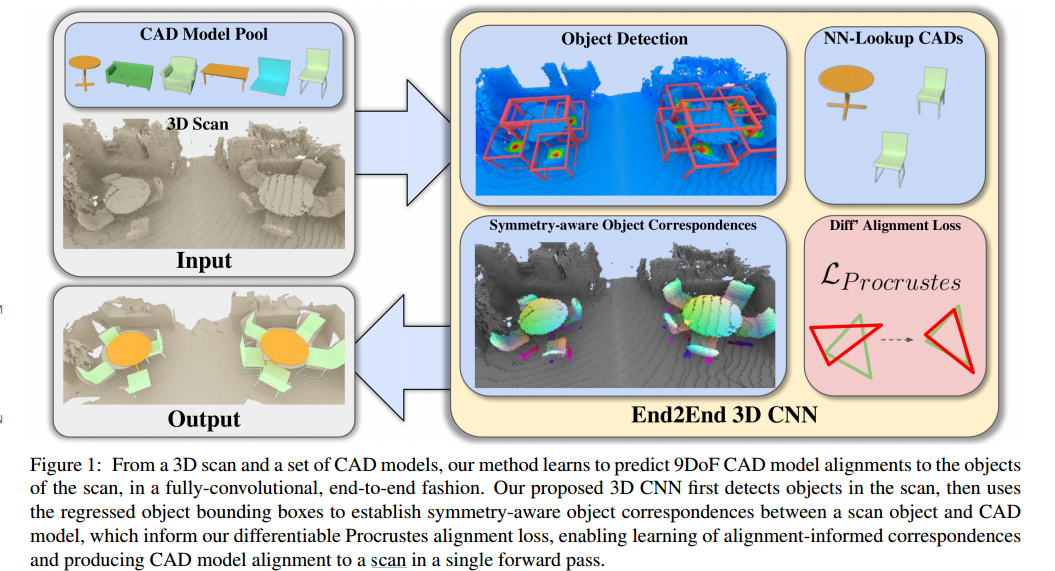
用于CAD模型匹配的端到端模型:
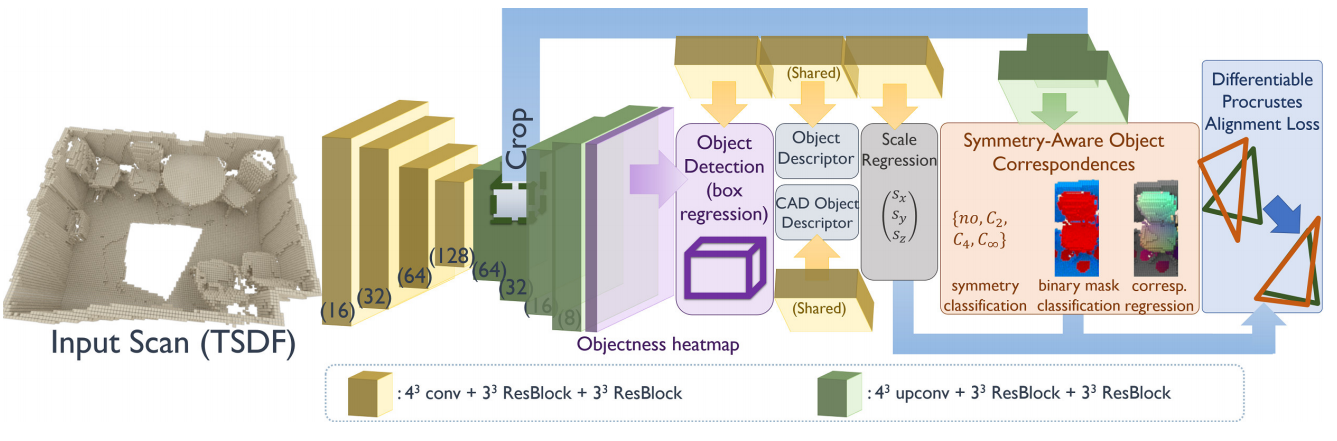
得到的一些结果,其中扫描数据来自,家具的CAD模型来自shapent core:
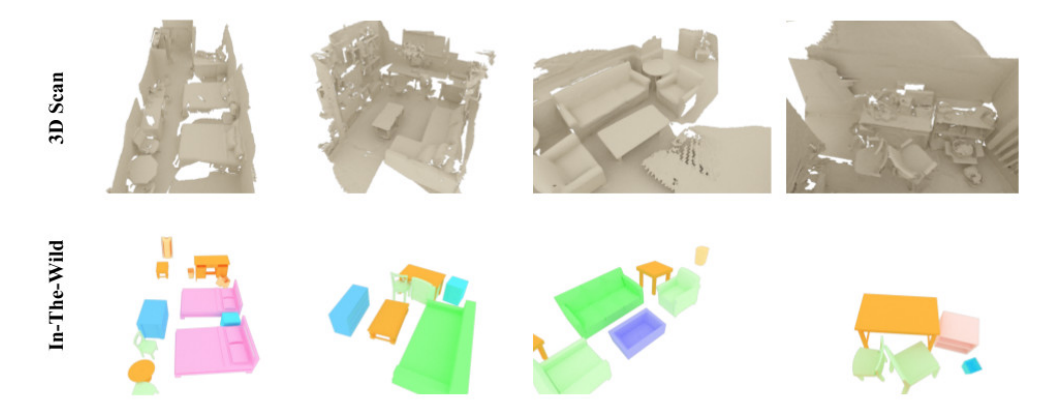
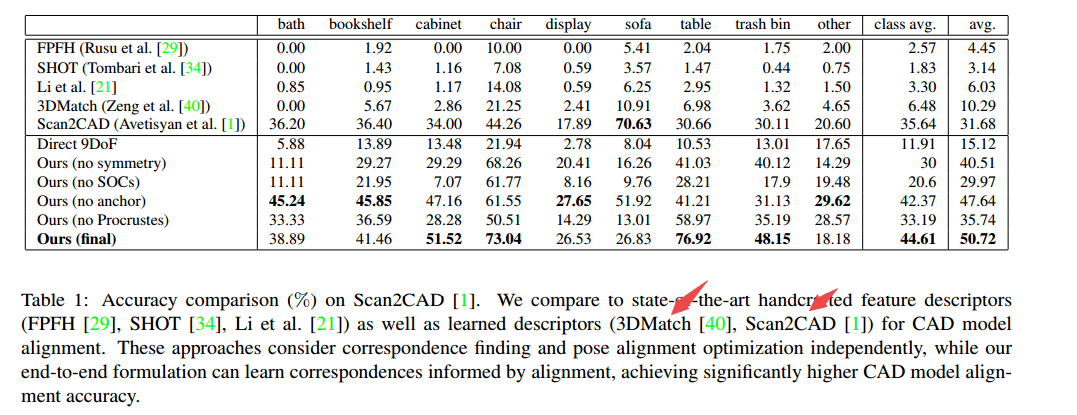
一些相关方法的比较:
数据主要来自于扫描数据的TSDF编码,encoded in a volumetric grid and generated through volumetric fusion [5]
场景数据来自Scan2CAD annotations provide 1506 scenes for training. SUNCG.
using the level-set generation toolkit by Batty [2]生成CAD模型的表示
?提出了一种新的三维表示方法clouds of oriented gradient ,COG, 可以精确的描述透视投影的角度如何影响成像图像的梯度。为了更好地表示大尺度的三维物体以及对于小物体的检测,研究人员引入了隐支持表面。最后提出的曼哈顿体素方法来更好的捕捉房间的三维几何布局信息。最后利用了多级分类器来捕捉内容上的关系,在SUN RGB-D数据集上实现了很好的结果(from 佐治亚理工 )
从输入的图像和深度图中首先对齐包含物体的立方体并转换到惯用的坐标系下,随后从中抽取出点云密度特征、3D法向量直方图和COG 描述子。并将点云密度和体素密度匹配起来。
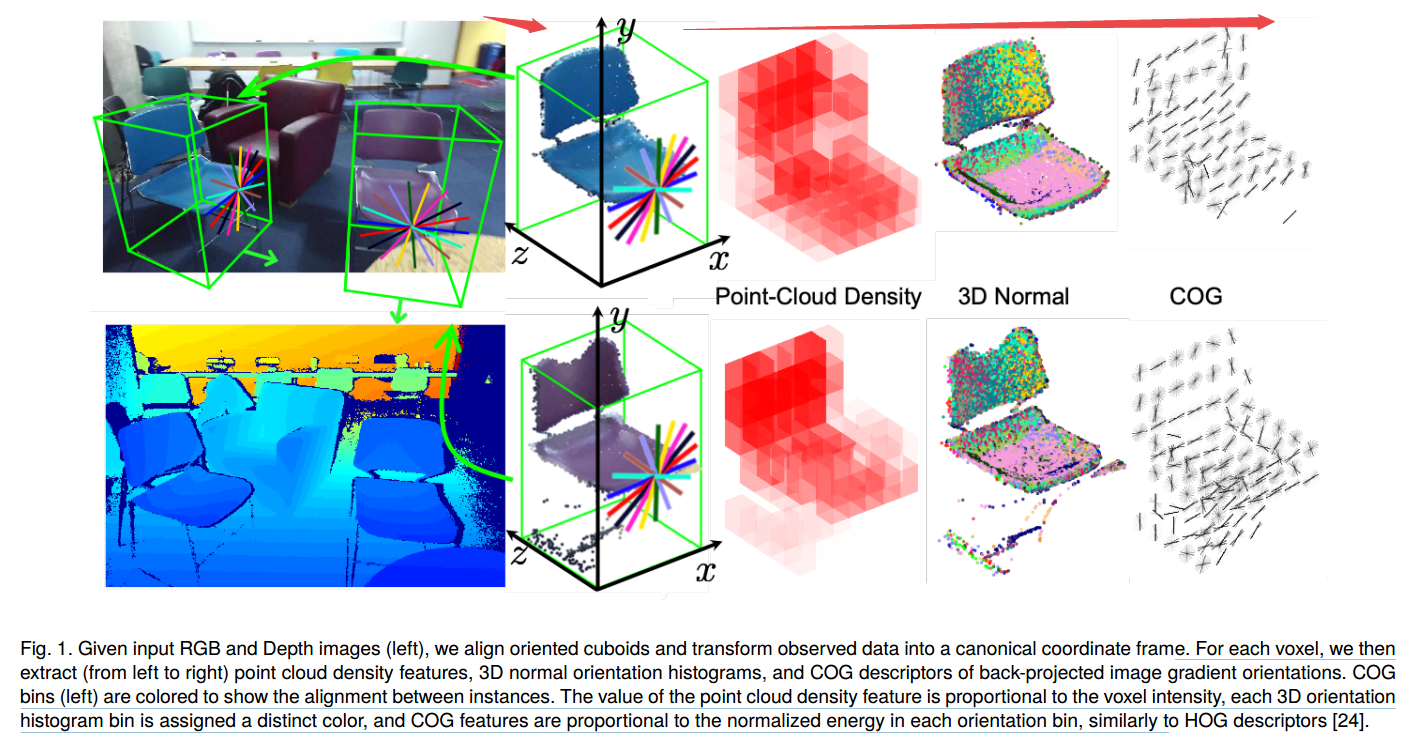
对于床和床上用品的检测结果:

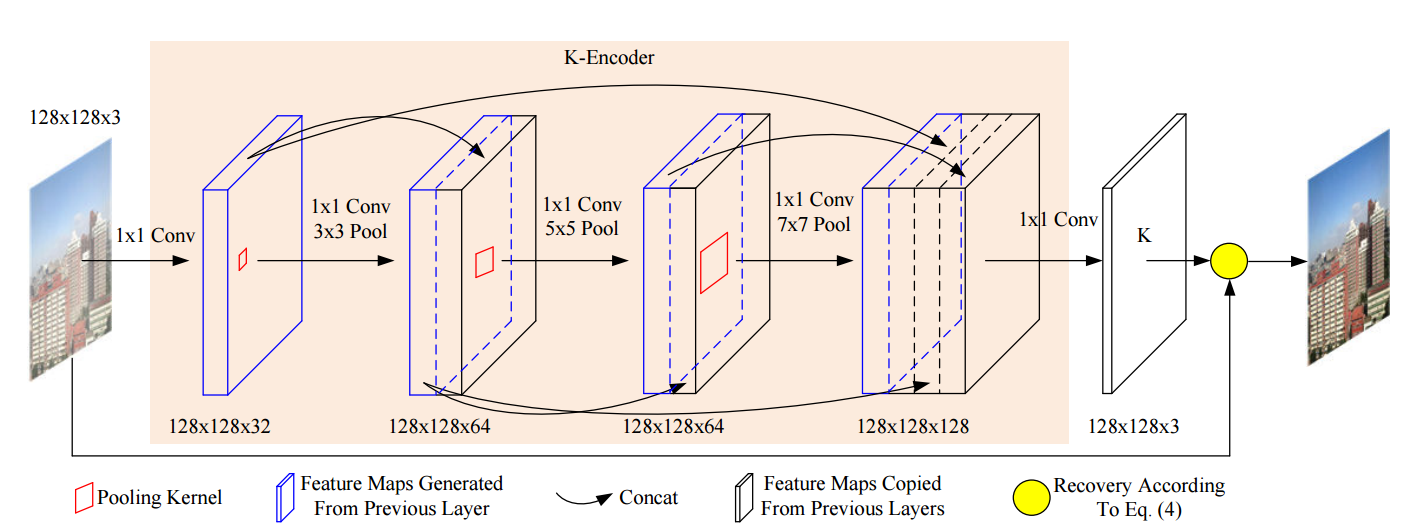
?FAMED-Net高速高精度的多尺读去雾方法, 图像去雾方法目前受制于模型复杂、计算效率和表达能力,为了解决这些问题,研究人员尝试使用三个不同尺度的编码器和融合模块构建去雾算法。每一个编码器由级联和稠密连接的逐点卷积层和池化层相连(类似shufflenet)。由于特征的复用和没有大型卷积操作使得这一模型十分轻量和高效。(from 悉尼大学 UBTECH)
网络有多个point-wise的卷积层和池化层的dense链接构成,
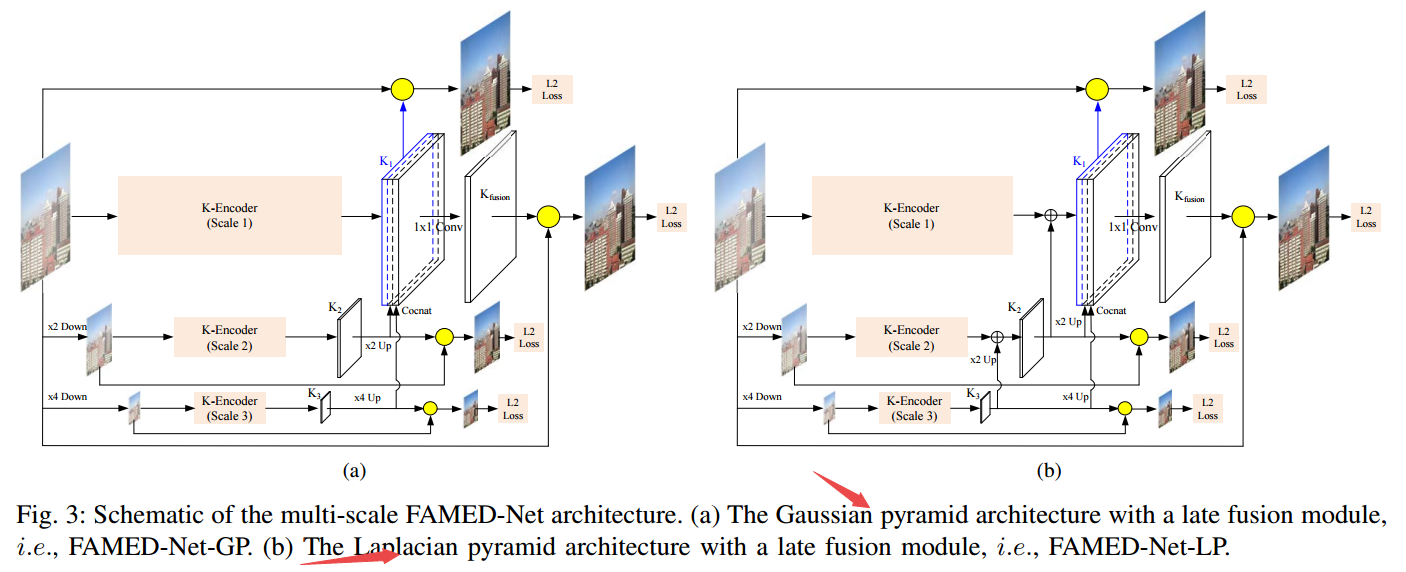
高斯金字塔和拉普拉斯金字塔结构的编码器和融合模型:
模型的一些结果:

真实图像的结果:

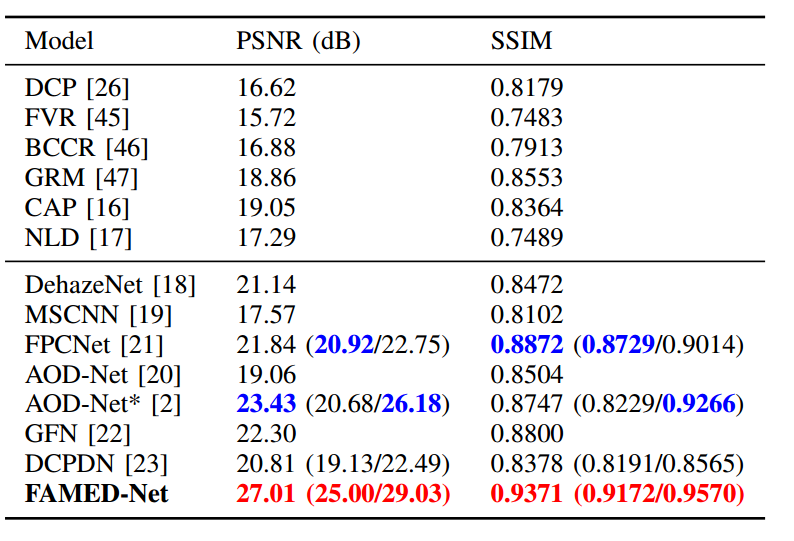
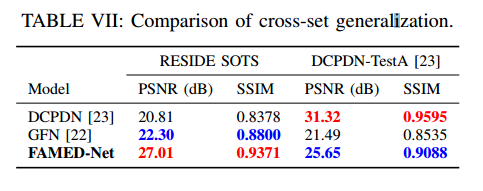
与相关结果的比较:
code:https://github.com/chaimi2013/FAMED-Net 作者即将放出
dataset:ITS and OTS,< RESIDE and TestSet-S
Daily Computer Vision Papers
| ****Shapes and Context: In-the-Wild Image Synthesis & Manipulation Authors Aayush Bansal, Yaser Sheikh, Deva Ramanan 我们引入了一种数据驱动方法,用于交互式地合成来自语义标签图的野外图像。我们的方法与此领域的近期工作截然不同,因为我们不使用任何学习方法。相反,我们的方法使用简单但经典的工具将场景上下文,形状和部件与存储的样本库进行匹配。虽然简单,但这种方法比近期工作1有几个明显的优势,因为没有学到任何东西,它不仅限于特定的训练数据分布,如城市景观,立面或面部2,它可以合成任意高分辨率的图像,仅受到分辨率的限制。通过适当地组成形状和部分,示例库3,它可以生成指数大的可行候选输出图像集,可以说是由用户交互式搜索。我们在不同的COCO数据集上展示结果,在标准图像合成指标上显着优于基于学习的方法。最后,我们探索用户交互和用户可控性,证明我们的系统可以用作用户驱动的内容创建的平台。 |
| **Clouds of Oriented Gradients for 3D Detection of Objects, Surfaces, and Indoor Scene Layouts Authors Zhile Ren, Erik B. Sudderth 我们开发了新的表示和算法,用于在杂乱的室内场景中进行三维三维物体检测和空间布局预测。我们首先提出了一个定向梯度COG描述符云,它将对象类别的2D外观和3D姿态联系起来,从而准确地模拟透视投影如何影响感知的图像渐变。为了更好地表示大型物体的3D视觉样式并提供上下文提示以改善小物体的检测,我们引入了潜在的支撑表面。然后,我们提出了曼哈顿体素表示,它更好地捕捉了常见室内环境的3D房间布局几何形状。通过潜在的结构化预测框架来学习有效的分类规则。通过级联分类器捕获类别和布局之间的上下文关系,从而导致超出SUN RGB D数据库的现有技术水平的整体场景假设。 |
| **3-D Surface Segmentation Meets Conditional Random Fields Authors Leixin Zhou, Zisha Zhong, Abhay Shah, Xiaodong Wu 在许多医学图像分析应用中,自动表面分割是重要且具有挑战性的。已经为各种对象分割任务开发了最近的基于深度学习的方法。它们中的大多数是基于分类的方法,例如, U net,它预测每个体素成为目标对象或背景的概率。这些方法的一个问题是缺乏对分割对象的拓扑保证,并且通常需要后处理来推断对象的边界表面。本文提出了一种基于三维卷积神经网络CNN和条件随机场CRF的新型模型,用于解决端到端训练的表面分割问题。据我们所知,这是第一个将3D神经网络与CRF模型应用于直接表面分割的研究。在NCI ISBI 2013 MR前列腺数据集和医学分割十项全能脾脏数据集上进行的实验证明了非常有前景的分割结果。 |
| Rethinking Person Re-Identification with Confidence Authors George Adaimi, Sven Kreiss, Alexandre Alahi 人体识别系统的一个共同挑战是区分具有非常相似外观的人。目前基于交叉熵最小化的学习框架不适合这一挑战。为了解决这个问题,我们建议使用三种方法标记平滑,置信度惩罚和深度变分信息瓶颈来修改表示学习框架中的交叉熵损失和模型置信度。我们的方法的一个关键属性是我们不使用任何手工制作的人类特征,而是将注意力集中在学习监督上。虽然建模置信度的方法没有显示出对象分类等其他计算机视觉任务的显着改进,但我们能够显示其在3个公开可用数据集上重新识别超出最新技术方法的任务的显着影响。我们的分析和实验不仅提供了人们所面临的问题的见解,而且还提供了一个简单而直接的方法来解决这个问题。 |
| Gated CRF Loss for Weakly Supervised Semantic Image Segmentation Authors Anton Obukhov, Stamatios Georgoulis, Dengxin Dai, Luc Van Gool 用于语义分割的现有技术方法依赖于在完全注释的数据集上训练的深度卷积神经网络,已经证明在时间和金钱方面收集都是非常昂贵的。为了弥补这种情况,弱监督方法利用需要少得多的注释努力的其他形式的监督,但是由于这些区域中的监督信号的近似性质,它们通常表现出无法预测精确的对象边界。虽然在提高性能方面取得了很大进展,但许多弱监督方法都是根据自己的具体情况量身定制的。这在重用算法和稳步前进方面提出了挑战。在本文中,我们在处理弱监督语义分割时故意避免这种做法。特别是,我们为标记像素训练具有部分交叉熵损失函数的标准神经网络,并为未标记像素训练我们提出的门控CRF损失。门控CRF损失旨在提供几个重要的资产1它使内核构造具有灵活性,以掩盖不受欢迎的像素位置的影响2它将学习上下文关系卸载到CNN并集中于语义边界3它不依赖于高维过滤和因此具有简单的实现。在整篇论文中,我们介绍了损失函数的优点,分析了弱监督训练的几个方面,并表明我们的纯粹方法实现了基于点击和基于涂鸦的注释的最新技术性能。 |
| **Scale Invariant Fully Convolutional Network: Detecting Hands Efficiently Authors Dan Liu, Dawei Du, Libo Zhang, Tiejian Luo, Yanjun Wu, Feiyue Huang, Siwei Lyu 现有的手检测方法通常遵循具有高计算 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









