






18 位人形机器人充当「迎宾」人员,整齐划一向嘉宾挥手,这是 2024 世界人工智能大会上的一个震撼场景,让人们直观感受到了今年机器人的飞速发展。

图源:甲子光年
1954 年,世界上第一台可编程机器人「尤尼梅特」在通用汽车装配线正式投入工作,历经半个多世纪,机器人从笨重的工业巨擘一步步成长为更智能、更灵活的人类助手。其中,人工智能技术,尤其是自然语言处理与计算机视觉的突破性进展,为机器人的发展铺设了一条高速轨道,利用巨大计算能力和海量数据,通过行为克隆等简单的算法来训练通用机器人策略, 正逐步解锁未来机器人的无限潜能。

尤尼梅特机器人 图源:百度百科
然而,目前机器人学习管道大多针对某个特定任务训练,这让它们在新情境或执行不同任务时显得力不从心。 此外,机器人训练数据主要来自仿真模拟、人体演示及机器人遥操作场景,不同数据源间存在巨大的异构性, 一个机器学习模型也很难整合如此多来源的数据,训练机器人通用策略一直是一大难题。
针对此,麻省理工研究人员提出了一个机器人策略组合框架 PoCo (Policy Composition), 该框架使用扩散模型的概率合成,组合不同领域和模态的数据,为构建复杂的机器人策略组合开发了任务级、行为级、领域级的策略合成方法,能够解决机器人在工具使用任务中的数据异构性、任务多样性问题。相关研究已经以「PoCo: Policy Composition from and for Heterogeneous Robot Learning」为题,发表在 arXiv 上。
研究亮点:
-
无需重新训练,PoCo 框架可以灵活组合不同领域数据训练的策略
-
在仿真模拟和真实世界中,PoCo 的工具使用任务都取得优异表现,与单个领域训练的方法相比,PoCo 对不同环境中的任务表现出高度泛化能力

论文地址:
https://arxiv.org/abs/2402.02511
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
三大数据集来源,涵盖人 & 机数据、真实 & 仿真数据等领域
本研究所涉及的数据集主要来自人类演示视频数据、真实机器人数据、仿真模拟数据。
人类演示视频数据集
人类演示视频可以从野外未校准的摄像机中收集,共收集多达 200 条轨迹。

数据集处理流程,未校准的RGB-D摄像机在野外采集的人类演示视频可以转换为标记的轨迹
真实机器人数据集
通过安装的手腕摄像头和头顶摄像头获取场景的局部、全局视图,用 GelSight Svelte Hand 采集工具姿势、工具形状、工具与对象接触时的触觉信息,每个任务收集 50-100 个轨迹演示。
仿真模拟数据集
模拟数据集遵循 Fleet-Tools,其中专家演示通过关键点轨迹优化生成,共收集大约 5 万个模拟数据点。在后续训练过程中,研究人员对点云数据和动作数据都进行了数据增强 (data augmentation),并保存固定的模拟场景以供测试使用。
此外,研究人员在来自深度图像 (depth images) 和遮罩 (masks) 中的 512 个工具和 512 个物体点云中,加入逐点噪声 (point-wise noises)、随机裁剪 (random dropping) 等,以提升模型的鲁棒性。
通过概率分布乘积形式进行策略组合
在策略组合中,研究人员给定两个概率分布编码的轨迹信息 pDM(⋅∣c,T)、pD′M′(⋅∣c′,T′),推理时在乘积分布中采样直接结合这两个概率分布的信息。
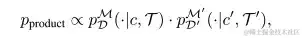
其中,pproduct 在同时满足两个概率分布的所有轨迹上表现出高似然性, 可有效编码两种分布的信息。
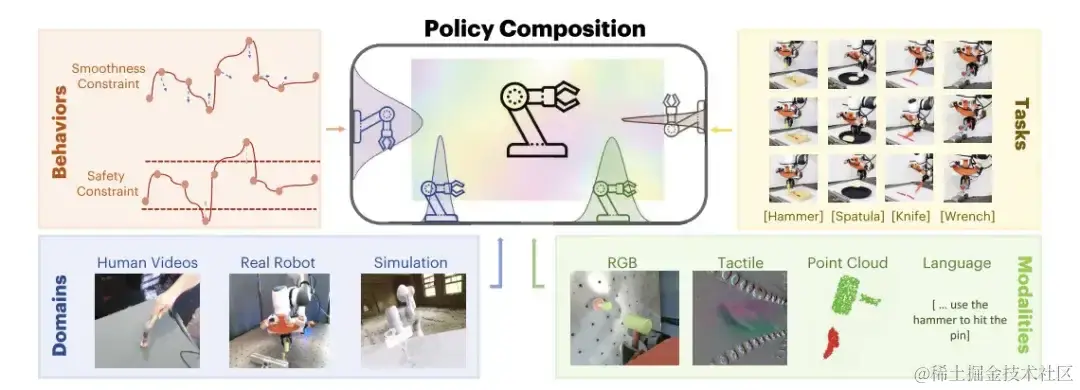
策略组合 PoCo
研究人员提出的 PoCo,将跨行为、任务、通道和领域的信息组合在一起, 无需重新训练,在预测时以模块方式组合信息,通过利用多个领域的信息即可实现对工具使用任务的泛化。
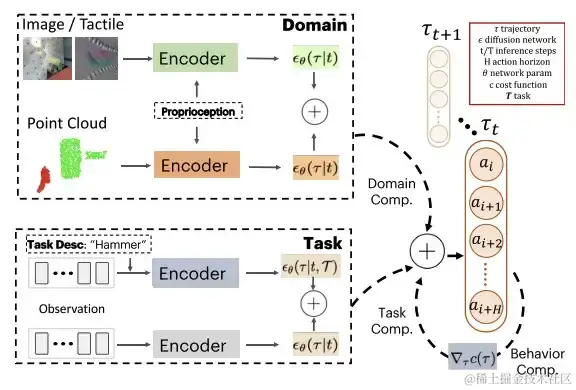
策略组合图解
假设每个模型的扩散输出在相同的空间,即动作维度和动作时域相同。在测试时,PoCo 结合梯度预测 (gradient predictions) 进行组合。这种方法可以应用于不同领域策略的组合,例如组合使用图像、点云和触觉图像等不同模态数据训练的策略。也可以用于不同任务的策略组合,以及通过行为组合为所需行为提供额外成本函数 (additional cost functions)。
对此,研究人员提供了任务级组合 (Task-level Composition)、行为级组合 (Behavior-level Composition)、领域级组合 (Domain-level Composition) 这 3 个示例,以此说明 PoCo 如何提高策略性能。
任务级组合 Task-level Composition
任务级组合在可能完成任务 T 的轨迹上增加了额外权重,可提高合成轨迹的最终质量,不需要为每个任务单独训练,而是训练一个能够实现多任务目标的通用策略。
行为级组合 Behavior-level Composition
这种组合可以结合任务分布和成本目标 (cost objective) 的信息,确保合成的轨迹既能完成任务,又能优化指定的成本目标。
领域级组合 Domain-level Composition
这种组合可以利用来自不同传感器模态、领域捕获的信息,对单独领域收集的数据互补非常有用。 例如,当真实机器人数据收集成本高但准确度更高,模拟演示数据收集成本较低但准确度低,可以对同一领域不同模式的数据进行特征串联 (feature concatenation) 以简化处理。
可视化工具使用任务,评估 3 大策略组合

可视化工具使用任务
在训练时,研究人员采用具有去噪扩散概率模型 (DDPM) 的时间 U-Net 结构,并进行 100 步训练;测试时,采用去噪扩散隐式模型 (DDIM),进行 32 步测试。为了在不同领域 D 和任务 T 之间组合不同的扩散模型,研究人员对所有模型使用相同的动作空间,并对机器人的动作边界做了固定的归一化处理。
研究人员通过机器人对通用工具(扳手、锤子、铲子和扳手)的使用任务来评估提出的 PoCo,当达到特定阈值时,任务被确定为成功,例如,当销钉被敲入时,锤击任务被认为成功。
行为级组合可以改善期望的行为目标
研究人员使用 test-time 推理来组合诸如平滑度和工作空间约束等行为,合成权重被固定为 γc=0.1。
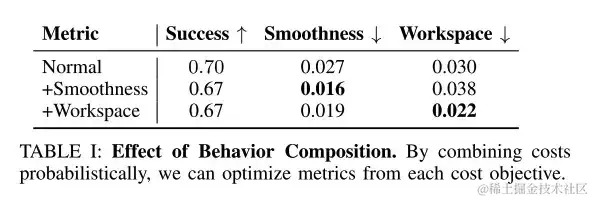
行为组合效应。通过概率地结合成本 (costs),可以优化每个成本目标的指标
如上表所示,test-time 行为级组合可以改善期望的行为目标,如平滑度和工作空间约束。
任务级组合在多任务策略评估中最优
当任务权重 α=0 时,任务级组合策略映射到无条件多任务策略 (unconditioned multitask policies),当 α=1 时,映射到标准任务条件策略 (task-conditioned policies),当 0 < α < 1 时,研究人员在任务条件、任务无条件策略 (task unconditional policies) 之间进行插值 (interpolating)。当 α > 1 时,可以得到更加与任务条件相关的轨迹。
在模拟的多任务策略评估中,任务级组合的表现最好
据上图表明,相对于无条件、特定任务条件性的多任务工具使用扩散策略,条件性、无条件多任务工具使用策略的任务组合更优。
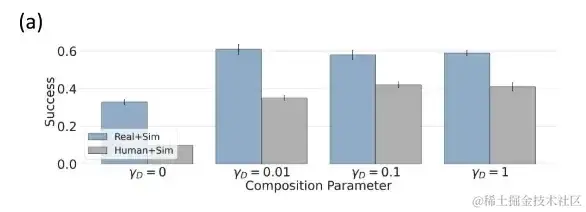
人类+模拟数据,领域级组合性能更优
研究人员使用模拟数据集 θsim、人类数据集 θhuman 和机器人数据集 θrobot 训练单独的策略模型,并在仿真模拟设置中评估领域级组合。
用模拟策略帮助跨领域组合及模拟评估
由于 θsim 不存在训练/测试领域差距,表现良好,可达到 92% 成功率。在人类数据等领域中,研究人员将它与性能更好的策略 θsim 进行组合,显著提高了性能。
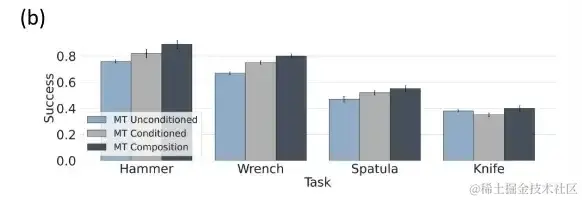
策略组合性能超过单独组成部分,通用性更强
研究人员将 PoCo 用于机器人工具使用任务中,组合不同领域和任务的数据,进而提高其泛化能力。4 项任务分别是:用扳手拧螺丝,用锤子敲击钉子,用铲子将煎饼从锅中铲起,用刀切开橡皮泥。

通过组合在仿真模拟、人类和真实数据中训练的策略,可以在跨多个干扰物(第1行)、不同物体和工具姿态(第2行),以及新的物体和工具实例(第3行)之间进行泛化
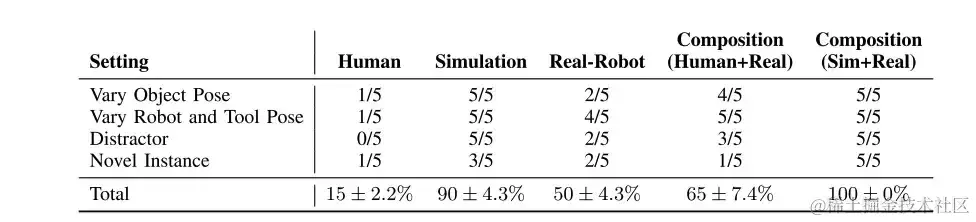
领域组合的定量结果。与单独成分策略相比,策略组合显著提高任务平均成功率
如上表所示,虽然人类 (Human) 数据训练的策略和真实机器人 (Real-Robot) 训练的策略在不同的场景下表现不佳 (与 Simulation 比较),但它们的组合 (Human+Real) 可以超过每个单独的组成部分。
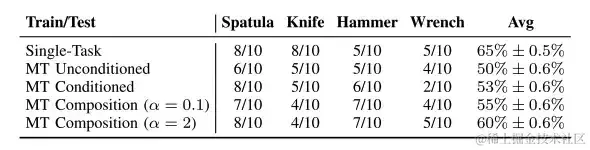
不同工具使用任务的策略表现,在工具使用任务中,任务组合策略总体性能提升
通过现实世界,研究人员评估机器人在 4 个不同工具使用任务上的策略表现,发现在工具使用任务中,任务组合策略性能提升更佳。 如上表所示,多任务策略与 Tspatula 和 Thammer 为条件的特定任务相比,性能几乎一致,它们都在 fine action 中表现出一定的稳定性。此外,组合超参数需要保持在一个范围内才能有效且稳定。
通用性的最佳条件,人形机器人强势崛起
通用机器人在过去两年得到了蓬勃发展,但一个有意思的现象是,目前行业似乎更认同以人形的方式来推动通用机器人的发展。为什么通用机器人一定要是人形? 五源资本董事总经理陈哲对此表示,「因为只有人形机器人才可能在人类的生活环境中适应不同交互场景!」既然机器人要帮人类干活,以人形外在来模仿人类学习,这显然是最佳的。
作为行业的指向标,早在 2022 年 9 月,特斯拉就发布了通用人型机器人 Optimus,虽然起初连路都走不稳,但它具备完整的人型机器人原型,满足人类能做的灵巧工作基础,在特斯拉软硬件技术的持续迭代下,Optimus 将具备更令人期待的功能,事实证明确实如此。

在 2024 世界人工智能大会上,特斯拉向大家展示了其人形机器人 Optimus 的最新研究进展:直立行走速度提高 30%、十个手指也进化出感知和触觉,能轻握易碎的鸡蛋、也能平稳地搬运沉重箱子。据了解,Optimus 已在特斯拉工厂尝试实际应用,比如借助视觉神经网络和 FSD 芯片,模仿人类操作进行电池的分拣训练,预计明年将有超过 1,000 个人形机器人在特斯拉工厂帮助人类完成生产任务。
同样地,作为一家成立于 2015 年的行业领先通用机器人公司,上海傅利叶智能科技有限公司也将其人形机器人 GR-1 带到了大会现场。自 2023 年推出至今,GR-1 已率先实现量产交付,在环境感知、仿真模型、运动控制优化等方面实现进阶升级。
此外,在今年 3 月份,英伟达在年度 GTC 开发者大会上,也推出了名为 GR00T 的人形机器人项目,通过观察人类行为来理解自然语言和模仿动作,机器人可以快速学习协调性、灵活性和其他技能,以导航、适应、与现实世界互动。
随着科技的不断进步,我们有理由相信,人形机器人或将成为连接人与机器、现实与未来的桥梁,引领我们进入一个更加智能、美好的社会。
参考资料:
https://m.163.com/dy/article/J69LAFDR0512MLBG.html
https://36kr.com/p/1987021834257154
https://hub.baai.ac.cn/view/211


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









