






简要介绍图中的优化算法,编程实现并2D可视化
1.SGD:
SGD(Stochastic Gradient Descent):随机梯度下降,是最基本的优化算法之一。它通过计算损失函数的梯度来更新模型参数,每次更新只考虑一个样本或一小批量样本,优势在此,劣势也在此,优势在于训练过程可以加快,但是同样带来的可能使收敛到局部最优解。
2.Momentum:
Momentum:动量法是在SGD基础上的改进,它通过引入动量项来加速收敛。动量项可以看作是模拟物理中的惯性,即在更新时加上一部分之前更新的方向和大小,从而使更新更加稳定。
3.Nesterov:
Nesterov:Nesterov加速梯度下降法是在动量法的基础上进行改进的,它通过预测下一步的梯度方向来更新模型参数。
4.AdaGrad:
AdaGrad:AdaGrad算法是一种自适应学习率的优化算法,它通过对每个参数的学习率进行自适应调整来加速收敛。AdaGrad算法会根据参数的历史梯度信息来调整学习率,从而使得在更新参数时对于频繁出现的梯度较大的参数,学习率会较小,而对于不经常出现的梯度较大的参数,学习率会较大。
5.RMSprop:
RMSprop:RMSprop算法是对AdaGrad算法的改进,它通过引入一个衰减系数来平衡历史梯度信息和当前梯度信息,从而避免学习率过小的问题。RMSprop算法可以加速收敛,并且对于稀疏数据集效果较好。
6.Adam:
Adam:Adam算法是一种结合了动量法和RMSprop算法的优化算法,它通过计算梯度的一阶矩估计和二阶矩估计来调整每个参数的学习率。Adam算法可以加速收敛,并且对于大规模数据集和高维空间的优化问题效果较好。
总之就是,每一个优化方法都在梯度,学习率上做文章,不论是添加过去的梯度还是预测后来的梯度,还是优化每一个参数的学习率,都通过一些方式来对优化进行有目的性地改变。
1. 被优化函数 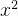
实验代码:
# coding: utf-8
import copy
from nndl.op import Op
import torch
import numpy as np
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings('ignore')
warnings.filterwarnings('ignore', category=DeprecationWarning)
warnings.filterwarnings('ignore', message='This is a warning message')
class OptimizedFunction(Op):
def __init__(self, w):
super(OptimizedFunction, self).__init__()
self.w = w
self.params = {'x': 0}
self.grads = {'x': 0}
def forward(self, x):
self.params['x'] = x
return torch.matmul(self.w.T, torch.tensor(torch.square(self.params['x']), dtype=torch.float32))
def backward(self):
self.grads['x'] = 2 * torch.multiply(self.w.T, self.params['x'])
class SGD:
"""
随机梯度下降法(Stochastic Gradient Descent)
"""
def __init__(self, lr=0.01):
self.lr = torch.tensor(lr)
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum:
"""
Momentum SGD
"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = torch.tensor(lr)
self.momentum = torch.tensor(momentum)
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = torch.tensor(np.zeros_like(val))
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
class Nesterov:
"""
Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)
"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = torch.tensor(momentum)
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = torch.tensor(np.zeros_like(val))
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
class AdaGrad:
"""
AdaGrad
"""
def __init__(self, lr=0.5):
self.lr = torch.tensor(lr)
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = torch.tensor(np.zeros_like(val))
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (torch.tensor(np.sqrt(self.h[key])) + torch.tensor(1e-7))
class RMSprop:
"""
RMSprop
"""
def __init__(self, lr=0.1, decay_rate=0.99):
self.lr = torch.tensor(lr)
self.decay_rate = torch.tensor(decay_rate)
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = torch.tensor(np.zeros_like(val))
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (torch.tensor(np.sqrt(self.h[key])) + torch.tensor(1e-7))
class Adam:
"""
Adam (http://arxiv.org/abs/1412.6980v8)
"""
def __init__(self, lr=0.2, beta1=0.9, beta2=0.99):
self.lr = torch.tensor(lr)
self.beta1 = torch.tensor(beta1)
self.beta2 = torch.tensor(beta2)
self.iter = torch.tensor(0)
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = torch.tensor(np.zeros_like(val))
self.v[key] = torch.tensor(np.zeros_like(val))
self.iter += 1
lr_t = self.lr * torch.tensor(np.sqrt(1.0 - self.beta2 ** self.iter)) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
def train_f(model, optimizer, x_init, epoch):
x = x_init
all_x = []
losses = []
for i in range(epoch):
all_x.append(copy.copy(x.numpy()))
loss = model(x)
losses.append(loss)
model.backward()
optimizer.update(params=model.params, grads=model.grads)
x = model.params['x']
return torch.tensor(all_x), losses
# 参数更新可视化
class Visualization(object):
def __init__(self):
"""
初始化可视化类
"""
# 只画出参数x1和x2在区间[-5, 5]的曲线部分
x1 = np.arange(-5, 5, 0.1)
x2 = np.arange(-5, 5, 0.1)
x1, x2 = np.meshgrid(x1, x2)
self.init_x = torch.tensor([x1, x2])
def plot_2d(self, ax, model, x, ax_i, ax_j, fig_name):
"""
可视化参数更新轨迹
"""
cp = ax[ax_i, ax_j].contourf(self.init_x[0], self.init_x[1], model(self.init_x.transpose(0, 1)),
colors=['#e4007f', '#f19ec2', '#e86096', '#eb7aaa', '#f6c8dc', '#f5f5f5',
'#000000'])
c = ax[ax_i, ax_j].contour(self.init_x[0], self.init_x[1], model(self.init_x.transpose(0, 1)), colors='black')
cbar = fig.colorbar(cp)
ax[ax_i, ax_j].plot(x[:, 0], x[:, 1], '-o', color='#000000')
ax[ax_i, ax_j].plot(0, 'r*', markersize=18, color='#fefefe')
ax[ax_i, ax_j].set_xlabel('$x1$')
ax[ax_i, ax_j].set_ylabel('$x2$')
ax[ax_i, ax_j].set_xlim((-2, 5))
ax[ax_i, ax_j].set_ylim((-2, 5))
ax[ax_i, ax_j].set_title(fig_name)
def train_and_plot_f(ax, model, optimizer, epoch, ax_i, ax_j, fig_name):
"""
训练模型并可视化参数更新轨迹
"""
# 设置x的初始值
x_init = torch.tensor([3, 4], dtype=torch.float32)
x, losses = train_f(model, optimizer, x_init, epoch)
# 展示x1、x2的更新轨迹
vis = Visualization()
vis.plot_2d(ax, model, x, ax_i, ax_j, fig_name)
# 固定随机种子
torch.manual_seed(0)
w = torch.tensor([0.2, 2])
# 实例化模型
model = OptimizedFunction(w)
# 创建图像并分块
fig, ax = plt.subplots(2, 3, sharex=True, sharey=True, figsize=(10, 6))
opt1 = SGD(lr=0.2)
train_and_plot_f(ax, model, opt1, epoch=50, ax_i=0, ax_j=0, fig_name='SGD-vis-para')
opt2 = Momentum()
train_and_plot_f(ax, model, opt2, epoch=50, ax_i=0, ax_j=1, fig_name='Momentum-vis-para')
opt3 = Nesterov()
train_and_plot_f(ax, model, opt3, epoch=50, ax_i=0, ax_j=2, fig_name='Nesterov-vis-para')
opt4 = AdaGrad()
train_and_plot_f(ax, model, opt4, epoch=50, ax_i=1, ax_j=0, fig_name='AdaGrad-vis-para')
opt5 = RMSprop()
train_and_plot_f(ax, model, opt5, epoch=50, ax_i=1, ax_j=1, fig_name='RMSprop-vis-para')
opt6 = Adam()
train_and_plot_f(ax, model, opt6, epoch=50, ax_i=1, ax_j=2, fig_name='Adam-vis-para')
plt.show()
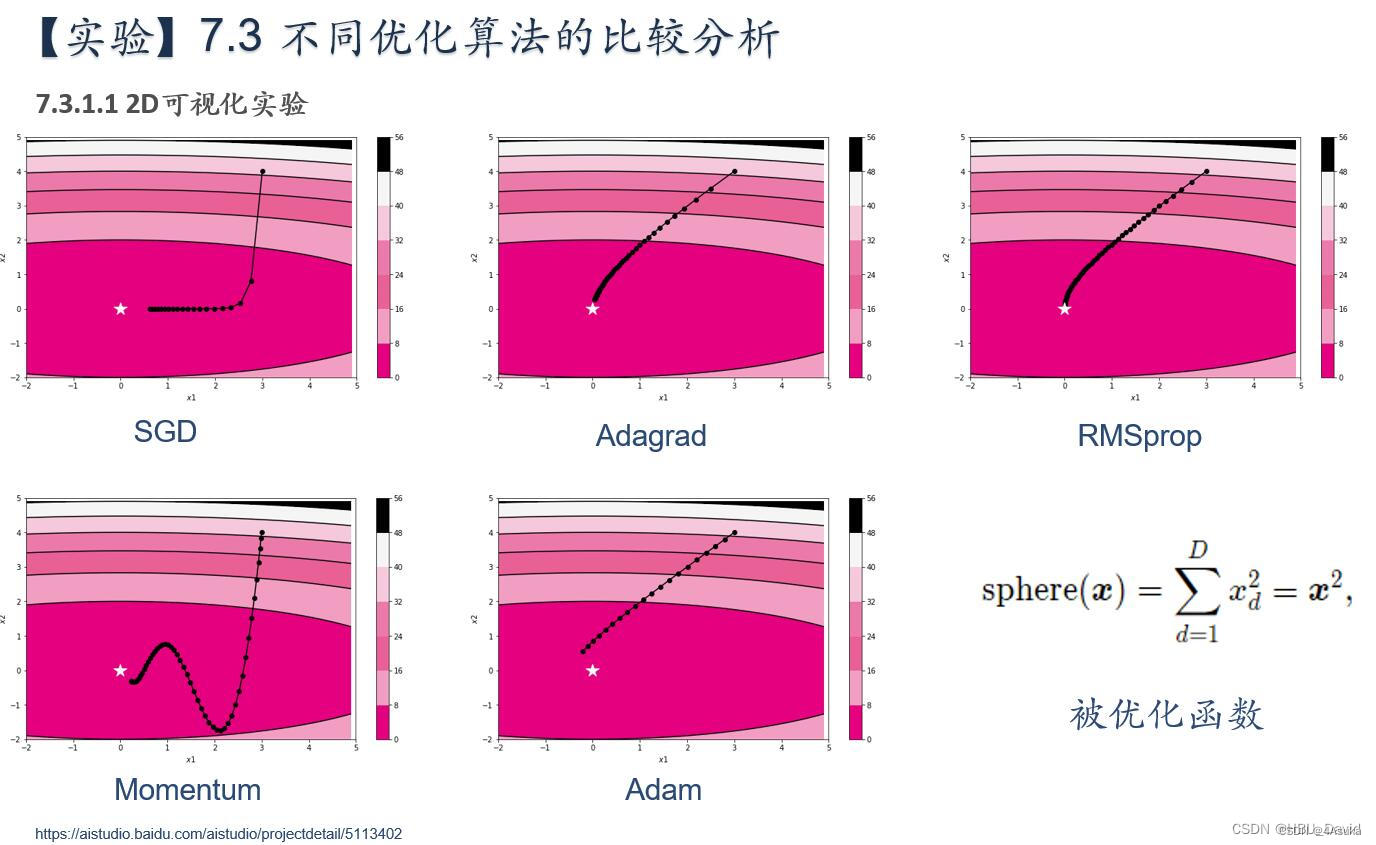
实验结果:

2. 被优化函数 
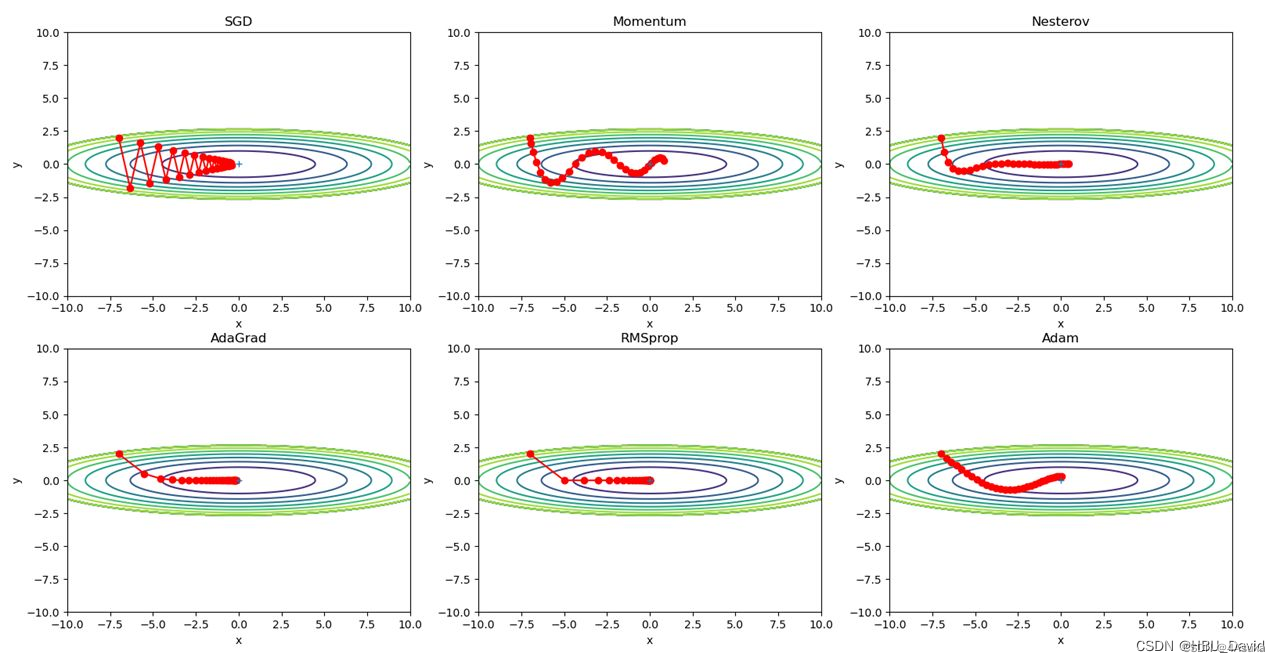
使用参考中的代码,不具体贴出了,直接看一下运行结果:
3. 解释不同轨迹的形成原因并分析各个算法的优缺点
1.SGD(Stochastic Gradient Descent):
由图可以看出SGD算法的更新轨迹呈现出震荡的形态,因为每次更新只考虑一个样本或一小批量样本,导致更新方向可能不一致,从而出现震荡。SGD算法还可能收敛到局部最优解,因为它只考虑当前样本的梯度,可能会出现梯度方向不准确的情况。
优点:简单易实现,适用于大规模数据集。
缺点:收敛速度慢,容易收敛到局部最优解。
2.Momentum:
由图可知,Momentum算法的轨迹呈现出平滑但波动稍大的形态,这是由于引入了动量项,可以加速收敛并减少震荡和梯度方向改变的情况。Momentum算法也可能会收敛到局部最优解,因为动量项可能会使得模型跳过全局最优解而收敛到局部最优解。
优点:可以加速收敛,减少震荡和梯度方向改变的情况。
缺点:可能会收敛到局部最优解。
3.Nesterov:
由图可知,Nesterov算法的轨迹呈现出比较平滑且准确的形态,这是由于预测下一步的梯度方向,可以更快地收敛并且比动量法更容易跳出局部最优解。
优点:可以更快地收敛,并且比动量法更容易跳出局部最优解。
缺点:需要额外的计算。
4.AdaGrad:
由图,AdaGrad算法的轨迹出先快后慢的形态并且相对平滑,这是由于自适应调整学习率,对于频繁出现的梯度较大的参数,学习率会较小,而对于不经常出现的梯度较大的参数,学习率会较大。
优点:自适应调整学习率,适用于稀疏数据集。
缺点:学习率会随着时间的增加不断减小,可能会导致学习率过小。
5.RMSprop:
由图,RMSprop算法的轨迹呈现出先快后慢的形态第一个平滑第二个波动很大,这是由于引入了衰减系数,平衡历史梯度信息和当前梯度信息,避免学习率过小的问题。
优点:可以加速收敛,对于稀疏数据集效果较好。
缺点:需要额外的计算。
6.Adam:
由图,Adam算法的轨迹呈现出先快后慢的形态但是速度差距不大,这是由于计算梯度的一阶矩估计和二阶矩估计来调整每个参数的学习率,可以加速收敛。
优点:可以加速收敛,对于大规模数据集和高维空间的优化问题效果较好。
缺点:需要额外的计算。
总结:
本次作业,没有给出每个优化算法的具体更新迭代方式,也就是公式,只是简单介绍了一下,从浅显的层面认识了一下,没有深入到公式的领域。
代码参考了给出的六个优化算法类,以及之前用到的各种函数等等,深入认识了如何画图的方式等等,由于时间关系,没有给出每一步的注释,但是结构基本类似所以也比较看懂吧。
参考:
【23-24 秋学期】NNDL 作业12 优化算法2D可视化-CSDN博客
NNDL 作业11:优化算法比较_"ptimizers[\"sgd\"] = sgd(lr=0.95) optimizers[\"mo-CSDN博客
【NNDL 作业】优化算法比较 增加 RMSprop、Nesterov_随着优化的进展,需要调整γ吗?rmsprop算法习题-CSDN博客















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









