







目录
7. 总结SGD、Momentum、AdaGrad、Adam的优缺点(选做)
1.简要介绍图中的优化算法,编程实现并2D可视化
SGD:
随机梯度下降通过迭代地调整模型参数,使得模型的损失函数(或目标函数)达到最小值。在每次迭代中,SGD算法随机选择一个样本,计算该样本的损失函数梯度,然后更新模型参数以减小损失函数的值。与传统的梯度下降算法相比,SGD具有更快的收敛速度和更好的泛化能力。
Momentum:
通过引入动量项来加速SGD的收敛速度,并减小震荡。Momentum算法在更新模型参数时,不仅考虑当前点的梯度,还考虑前一步的参数更新方向,使得参数更新更加平滑。
AdaGrad:
全称为自适应梯度算法(Adaptive Gradient Algorithm),AdaGrad对每个参数的学习率进行调整,对于不频繁出现的参数,执行较大的更新;对于频繁出现的参数,执行较小的更新。这种自适应的学习率调整可以更好地处理稀疏数据。
RMSProp:
RMSProp算法在每次迭代中维护一个指数加权平均值,调整每个参数的学习率。如果某个参数的梯度较大,则RMSProp算法会自动减小它的学习率;如果梯度较小,则会增加学习率。这样可以使得模型的收敛速度更快。
Adam:
全称为自适应矩估计(Adaptive Moment Estimation),Adam结合了Momentum和RMSProp的思想,同时考虑了梯度和一阶矩估计的变化率。Adam算法对每个参数的学习率进行动态调整,并利用指数加权移动平均来估计梯度和一阶矩的均值和方差。通过这种方式,Adam可以自动调整学习率,并且通常在训练初期表现出更好的收敛速度和稳定性。
1. 被优化函数 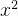

2. 被优化函数 

3. 编程实现图6-1,并观察特征

import numpy as np
from matplotlib import pyplot as plt
# 导入 Matplotlib 的 3D 工具包,用于绘制三维图形
from mpl_toolkits.mplot3d import Axes3D
# 定义被优化函数 func(x, y) = x * x + 20 * y * y
def func(x, y):
return x * x + 20 * y * y
#用于绘制三维曲面图
def paint_loss_func():
# 使用 NumPy 的 linspace 函数在 -50 到 50 的区间上均匀取 100 个数作为 x 和 y 的值
x = np.linspace(-50, 50, 100)
y = np.linspace(-50, 50, 100)
# 使用 NumPy 的 meshgrid 函数生成两个二维数组,这两个数组分别对应 X 和 Y 坐标的网格点
X, Y = np.meshgrid(x, y)
# 使用之前定义的 func 函数计算每个网格点上的 Z 值,得到一个二维数组 Z
Z = func(X, Y)
# 创建一个新的画图窗口
fig = plt.figure() # figsize=(10, 10))
# 添加一个 3D 子图到图形窗口中,并获取这个子图的 Axes3D 对象
ax = Axes3D(fig)
# 设置 x 轴和 y 轴的标签
plt.xlabel('x')
plt.ylabel('y')
# 使用 Axes3D 对象的 plot_surface 方法绘制三维曲面图,rstride 和 cstride 参数控制行和列的跨度,cmap 参数设置颜色映射
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='rainbow')
plt.show()
# 调用 paint_loss_func 函数绘制三维曲面图
paint_loss_func()这里我对老师给出的代码进行注释
把老师给的代码直接复制过来,运行出来的结果是空白的不知道为什么,将matplotlib库更新到最新版本后还是这样,而且也不报错。


4. 观察梯度方向

5. 编写代码实现算法,并可视化轨迹
SGD、Momentum、Adagrad、Adam
代码:
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
#定义SGD优化算法的类
class SGD:
"""随机梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
#定义Momentum优化算法的类
class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
#定义Nesterov优化算法的类
class Nesterov:
"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
#定义AdaGrad优化算法的类
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
#定义RMSprop优化算法的类
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
#定义Adam优化算法的类
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
#定义被优化函数函数f(x, y)
def f(x, y):
return x ** 2 / 20.0 + y ** 2
#定义被优化函数的偏导数df(x, y)
def df(x, y):
return x / 10.0, 2.0 * y
#定义初始位置和参数梯度
init_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0
optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=0.95)
optimizers["Momentum"] = Momentum(lr=0.1)
optimizers["AdaGrad"] = AdaGrad(lr=1.5)
optimizers["Adam"] = Adam(lr=0.3)
idx = 1
#通过遍历optimizers字典,对每个优化算法进行优化过程的展示
for key in optimizers:
optimizer = optimizers[key]
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(30):
x_history.append(params['x'])
y_history.append(params['y'])
grads['x'], grads['y'] = df(params['x'], params['y'])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# for simple contour line
mask = Z > 7
Z[mask] = 0
# plot
plt.subplot(2, 2, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="red")
plt.contour(X, Y, Z) # 绘制等高线
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
plt.title(key)
plt.xlabel("x")
plt.ylabel("y")
plt.subplots_adjust(wspace=0, hspace=0) # 调整子图间距
plt.show()
根据结果可得,收敛效果排序依次为AdaGrad、Adam、Momentum、SGD。
6. 分析上图,说明原理(选做)
(1)为什么SGD会走“之字形”?其它算法为什么会比较平滑?
(参考文章:SGD 的缺点_代码实现sgd算法的类,讨论该算法有和缺点。-CSDN博客和NNDL 作业11:优化算法比较_cifar10 sgd和adam-CSDN博客和神经网络与深度学习 作业11:优化算法比较-CSDN博客)
因为在此函数中梯度的方向并没有指向最小值的方向,SGD只是单纯的朝着梯度方向,放弃了对梯度准确性的追求,会使得其在 函数的形状非均向(比如y方向变化很大时,x方向变化很小 ),能迂回往复地寻找,效率很低。
另外,SGD算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型。
其他算法比较平滑是因为对SGD梯度摆动的问题进行解决,例如Momentum就是引入了动量这一概念来减弱Z字型走位。从而得到的图像比较平滑。
(2)Momentum、AdaGrad对SGD的改进体现在哪里?速度?方向?在图上有哪些体现?
SGD形式:

Momentum形式:

新出现了一个变量v,对应物理上的速度。表示了物体在梯度方向上受力,在这个力的作用下,物体的速度增加。
体现在图上为:“之”字形的“程度”减轻。
这是因为虽然x轴方向上受到的力非常小,但是一直在同一方向上受力,所以朝同一个方向会有一定的加速。反过来,虽然y轴方向上受到的力很大,但是因为交互地受到正方向和反方向的力,它们会互相抵消,所以y轴方向上的速度不稳定。因此,和SGD时的情形相比,可以更快地朝x轴方向靠近,减弱“之”字形的变动程度。(摘自鱼书P169)。
AdaGrad形式:


注:AdaGrad会记录过去所有梯度的平方和。因此,学习越深入,更新的幅度就越小。实际上,如果无止境地学习,更新量就会变为 0,完全不再更新。
体现在图上为:函数的取值高效地向着最小值移动。
这是因为y轴方向上的梯度较大,因此刚开始变动较大,但是后面会根据这个较大的变动按比例进行调整,减小更新的步伐。因此,y轴方向上的更新程度被减弱,“之”字形的变动程度有所衰减。(摘自鱼书P172)
(3)仅从轨迹来看,Adam似乎不如AdaGrad效果好,是这样么?
为了实验的严谨性,这里将两个优化算法的学习率调到相等:

仅从轨迹来看,可以发现,AdaGrad的效果好于Adam。
(4)四种方法分别用了多长时间?是否符合预期?
SGD:0.29798
Momentum:0.11013
AdaGrad:0.20334
Adam:0.23995
符合预期
(5)调整学习率、动量等超参数,轨迹有哪些变化?
lr=0.1,momentum=9

lr=3,momentum=9

lr=10,momentum=9

lr=0.1,momentum=0.9

lr=3,momentum=0.9

lr=10,momentum=0.9

从以上实验结果的路径可以看出,对于本实验数据,SGD和Momentum很容易错过全局最小值,Adam需要较长的时间和较多的搜索次数来找到全局最小值,AdaGrad效果最好。
7. 总结SGD、Momentum、AdaGrad、Adam的优缺点(选做)
SGD
优点
- 算法收敛速度快(在Batch Gradient Descent算法中, 每轮会计算很多相似样本的梯度, 这部分是冗余的)
- 可以在线更新
- 有几率跳出一个比较差的局部最优而收敛到一个更好的局部最优甚至是全局最优
缺点
- 容易收敛到局部最优,并且容易被困在鞍点
Momentum
优点
- 与梯度下降相比,下降速度快,因为如果方向是一直下降的,那么速度将是之前梯度的和,所以比仅用当前梯度下降快。
- 对于窄长的等梯度图,会减轻梯度下降的震荡程度,因为考虑了当前时刻是考虑了之前的梯度方向,加快收敛。
- 增加了稳定性。
- 还有一定摆脱局部最优的能力。
缺点
- 其更新方向完全依赖于当前batch计算出的梯度,因而十分不稳定。
AdaGrad
优点
- 不同更新频率的参数具有不同的学习率,减少摆动,在稀疏数据场景下表现会非常好;
- 允许使用一个更大的学习率α \alphaα,从而加快算法的学习速度;
缺点
- 仍需要手动设置一个全局学习率 , 如果学习率设置过大的话,会使regularizer过于敏感,对梯度的调节太大。
- 训练到中后期,分母中对历史梯度一直累加,学习率将逐渐下降至0,使得训练提前结束。
- 初始化W影响初始化梯度,如果初始梯度很大的话,会导致整个训练过程的学习率很小,导致学习时间变长。
Adam
优点
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
- 对内存需求较小
- 为不同的参数计算不同的自适应学习率
- 也适用于大多非凸优化
- 适用于大数据集和高维空间
缺点
- 可能不收敛。
- 可能错过全局最优解。
8. Adam这么好,SGD是不是就用不到了?(选做)
(参考:优化方法总结:Adam那么棒,为什么还对SGD念念不忘? (SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)_为何vit用adam-CSDN博客这篇文章是作者转载的,但是转载原文已经删除,所以附上这篇文章的链接)
从几篇怒怼Adam的paper来看,多数都构造了一些比较极端的例子来演示了Adam失效的可能性。这些例子一般过于极端,实际情况中可能未必会这样,但这提醒了我们,理解数据对于设计算法的必要性。优化算法的演变历史,都是基于对数据的某种假设而进行的优化,那么某种算法是否有效,就要看你的数据是否符合该算法的胃口了。
算法固然美好,数据才是根本。
另一方面,Adam之流虽然说已经简化了调参,但是并没有一劳永逸地解决问题,默认的参数虽然好,但也不是放之四海而皆准。因此,在充分理解数据的基础上,依然需要根据数据特性、算法特性进行充分的调参实验。
9. 增加RMSprop、Nesterov算法。(选做)
代码:
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
class SGD:
"""随机梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
class Nesterov:
"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSprop:
"""RMSprop"""
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
def f(x, y):
return x ** 2 / 20.0 + y ** 2
def df(x, y):
return x / 10.0, 2.0 * y
init_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0
learningrate = [0.9, 0.3, 0.3, 0.6, 0.6, 0.6, 0.6]
optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=learningrate[0])
optimizers["Momentum"] = Momentum(lr=learningrate[1])
optimizers["Nesterov"] = Nesterov(lr=learningrate[2])
optimizers["AdaGrad"] = AdaGrad(lr=learningrate[3])
optimizers["RMSprop"] = RMSprop(lr=learningrate[4])
optimizers["Adam"] = Adam(lr=learningrate[5])
idx = 1
id_lr = 0
for key in optimizers:
optimizer = optimizers[key]
lr = learningrate[id_lr]
id_lr = id_lr + 1
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(30):
x_history.append(params['x'])
y_history.append(params['y'])
grads['x'], grads['y'] = df(params['x'], params['y'])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# for simple contour line
mask = Z > 7
Z[mask] = 0
# plot
plt.subplot(2, 3, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="r")
# plt.contour(X, Y, Z) # 绘制等高线
plt.contour(X, Y, Z, cmap='gray') # 颜色填充
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
# plt.axis('off')
# plt.title(key+'\nlr='+str(lr), fontstyle='italic')
plt.text(0, 10, key + '\nlr=' + str(lr), fontsize=20, color="b",
verticalalignment='top', horizontalalignment='center', fontstyle='italic')
plt.xlabel("x")
plt.ylabel("y")
plt.subplots_adjust(wspace=0, hspace=0) # 调整子图间距
plt.show()
对比Momentum与Nesterov、AdaGrad与RMSprop。
这里直接在第二问一起给出。
2. 解释不同轨迹的形成原因
分析各个算法的优缺点
(参考:SGD ,Adam,momentum等优化算法比较_adam momentum-CSDN博客)
深度学习优化算法经历了 SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam这样的发展历程。


总结:
1. 对于遗留问题:
对于优化算法的可视化:
我把老师给的代码直接复制过来,运行出来的结果是空白的不知道为什么,将matplotlib库更新到最新版本后还是这样,而且也不报错。看了很多学长学姐的博客,发现他们的都可以运行,可能是我环境的原因。
2. 这次作业的感悟是不是最新的Adam优化算法就是最好的,不能所有的实验都无脑用Adam算法,这些优化算法都各有千秋,在没有具体的数据集的情况下空谈哪个算法是最好的,是不合适的,不同的优化算法适用于不同的数据集,没有绝对的最好的算法,合适的就是最好的。
REF:图灵社区-图书 (ituring.com.cn)
深度学习入门:基于Python的理论与实现
NNDL 作业11:优化算法比较_"ptimizers[\"sgd\"] = sgd(lr=0.95) optimizers[\"mo-CSDN博客
【NNDL 作业】优化算法比较 增加 RMSprop、Nesterov_随着优化的进展,需要调整γ吗?rmsprop算法习题-CSDN博客















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









